深度强化学习落地方法论(5)——状态空间篇
目录
- 前言
- 状态设计的四个步骤
-
- 任务分析
- 相关信息筛选
-
- 直接相关信息
- 间接相关信息
- 相关信息预处理
- 统一性考虑
-
- 形式统一
- 逻辑统一
- 效果验证
-
- 模仿学习验证
- 直接验证
- 缺省验证
- 总结
前言
DRL的状态信息代表了agent所感知到的环境信息,以及因自身的action带来的变化。状态信息是agent制定决策和评估其长期收益的依据,而状态设计的好坏直接决定了DRL算法能否收敛、收敛速度以及最终性能,兹事体大,不可不察。通常在一些公共平台,如Gym,大部分domain的状态空间都是现成的,学者们在上边比的是谁的算法收敛快、性能好;然而,在实际项目中,状态空间设计工作却要自己来,根据我的个人经验,增加一个优秀的新状态信息所带来的性能提升明显高于其他方面的工作(如调参),性价比非常高,因此状态空间的优化工作几乎贯彻项目始终。
大家注意到我多次使用“设计”这个词,这不就是特征工程(feature engineering)嘛,9102年都快过完了,怎么还搞这一套?直接上深度神经网络呀!真要那么简单就好了……把所有原始信息一股脑堆砌起来,让神经网络去挑选其中有用的成分并学习它们与决策间的相关性,原理上是没毛病的,可端到端的DRL学习效率实在不太给力,比有监督学习差老远了,即使经过大量训练神经网络能够最终提取到有用信息,因为训练时间的延长也会导致算法实用性的下降。更糟糕的是,一些不相关的干扰信息还会起到反作用。因此,要想在可控时间内得到比较好的policy,的确需要人为筛选出一些好的状态信息,可以是raw information,也可以是经过二次加工的信息,帮助神经网络更轻松准确地建立起决策相关性。
状态设计的四个步骤
那么具体该如何做呢?我把状态空间设计的精髓总结成以下4个步骤:任务分析,相关信息筛选,统一性考虑,效果验证。
任务分析
任务分析是状态设计的灵魂,好的状态信息建立在对任务逻辑的深入理解之上。客户提出最终目标,优秀的算法工程师需要把这个目标进一步分解,研究该目标的本质是什么,要实现它涉及到哪些重要环节,每个环节有哪些影响因素,每个因素又由哪些信息体现。对任务逻辑的深入分析也有助于我们设计优秀的回报函数(reward),并反哺状态空间的设计。对一个复杂任务的理解,除非天赋异禀或者相关经验丰富,一般都是要经过一段时间的摸爬滚打后才会深入到一定程度,期间还可能不断推翻之前的错误认知,更伴随瞬间顿悟的喜悦,因此要保持足够的耐心。

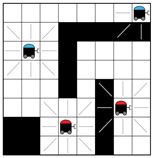
为了便于说明,这里引入一个简单任务场景:在一个遍布障碍物的平面区域内有若干辆小车在随机位置待命,现在要求它们以最短时间行驶到各自的终点位置停下来,期间避免与障碍物或者其他小车发生碰撞。我们可以把上述目标分解成三部分:1.达到终点,2.避免碰撞,3.用时短。到达终点要求小车知道自己在哪,还要知道终点在哪;避免碰撞要求小车知道附近障碍物的位置,自己和周围其他小车的位置及运动状态;用时短要求小车少绕路,行驶速度快,尽量避免减速和刹车。
相关信息筛选
带着以上分析,我们就可以进入下一个环节——相关信息筛选。顾名思义,就是在所有可用信息中找出与任务目标、子目标有关的那些。我们都知道RL任务逻辑最终是以回报函数(reward)为载体呈现的,而RL算法优化的则是该reward系统下的长期累计收益。神经网络的作用是将原始状态信息经过层层非线性提炼后转化为与长期收益高度关联的形式,并进一步指导生成action决策。理想情况下,状态空间应该完全由筛选出的相关信息组成。某个状态信息所代表的事件在越短时间内得到反馈,神经网络就越容易学会如何对其进行加工并建立起决策相关性。按照这个反馈时间的长短,我们还可以粗略地将这些相关信息分为直接相关信息和间接相关信息。
直接相关信息
所谓直接相关信息,就是与某个reward奖励项或惩罚项即时联动的信息。比如为了更有效地避免小车之间发生碰撞,回报函数里设计了“最近小车距离反比”惩罚项 − α ⋅ max ( D − d m i n ) -\alpha\cdot\max\left (D-d_{min} \right ) −α⋅max(D−dmin),其中 D D D是靠近惩罚阈值,当agent与周围最近小车距离 d m i n d_{min} dmin小于 D D D时,即开始反比惩罚,靠得越近罚得越多。这里的 d m i n d_{min} dmin相对于该惩罚项就属于直接相关信息,agent在每一步都能收到与 d m i n d_{min} dmin线性相关的反馈,很容易建立起决策相关性。再举一个例子,我们希望小车在电量不足时主动停止工作转而去指定地点充电,除了在reward中设置电量不足的惩罚项,同时也应该在状态空间中增加当前剩余电量,小于设定阈值时即在每步做惩罚。这也属于直接相关信息,没有这个信息,小车是无法建立起电量不足与该惩罚的相关性的,也就无从学会主动去充电。

直接相关信息不仅对DRL算法学习很友好,在有对口reward奖励/惩罚项的前提下,对算法工作者来说也更容易设计。事实上,DRL的状态空间设计往往和reward设计同时进行,为了达到某个目的需要增加一项奖励/惩罚,并相应增加一个或多个直接相关状态信息,帮助模型识别现象与反馈之间的因果关系,这一设计理念很直观也很有效。
间接相关信息
间接相关信息指的是reward中没有即时联动项的状态信息,其所代表的事件需要一段时间后才得到反馈。相对于直接相关信息,DRL利用它们建立决策相关性的难度更高,学习效率更差。比如下图中的游戏画面,agent要通关必须先吃钥匙,假如reward没有专门设置“吃钥匙”的奖励项,那么吃钥匙的好处要等到通关的时候才能体现出来。

再比如小车要学会到达终点,当前位置坐标、朝向、速度、加速度、终点坐标、周围障碍物的分布似乎都与到达终点这一目标有关,假如我们暂时没有针对这个目标做更细化的credit assignment,而只设置了到达终点奖励,那么这些信息就都属于间接相关信息,agent只有经过充分探索后才能发现某时刻这些信息的变化与最终达到终点之间的联系。
间接相关信息通过某些手段可以转化为直接相关信息,从而提高DRL的学习效率。最简单的方法是对任务目标做更详细的credit assignment并增加相应的reward奖励/惩罚项,如果某状态信息恰好与之即时联动,相应状态信息就成为了直接相关信息。还以小车为例,如果在reward中增加靠近终点奖励或远离终点惩罚,那么小车的朝向(配合小车当前坐标和终点坐标)就成为了直接相关信息。更多关于reward函数设计的内容我在下一篇中再详细介绍。
相关信息预处理
无论是直接相关还是间接相关,原始信息都要经过神经网络的提炼才能转化为action输出,提炼难度与学习效率和最终性能呈反向相关。如果我们提前对原始信息做些二次加工,人为提炼出与学习目标更相关的因素,相当于替神经网络干了一部分活儿,虽然不那么elegant,但往往能收到奇效。举个极端例子,直接告诉agent钥匙的相对坐标在哪儿,一定比神经网络通过原始图像更容易学到吃钥匙的操作。由于强化学习的优化目标是折扣累加的长期收益,这使得reward起作用的方式较为间接,无法像有监督学习那样为神经网络的feature extraction提供很好的指导,这也是DRL训练效率低下的根本原因。因此,我们在状态空间上多下一点功夫,DRL学习的难度就降低一点。在资源有限的情况下这很有可能就是训不出来和训得出来的区别,也有可能是性能不达标与性能达标的区别。
统一性考虑
当我们已经筛选出了所有相关信息,接下来该以何种形式使用它们呢?把他们拉成一组向量塞到神经网络里行不行?当然可以,但那样做只能得到适用于当前特定场景的policy。比如状态信息中包含了其他小车的信息,则训练出的policy只适合特定数量小车的任务,假如车数增加或减少,输入向量维度随之变化,policy就没法用了。因此,我们必须合理设计状态信息使其对环境主要因素的改变有最起码的兼容性,我把它称之为统一性考虑。具体地,这里的统一性又包含形式统一和逻辑统一。
形式统一
为了保证输入向量长度恒定,我们需要找到一种统一形式把不同信息填到对应的位置。比如小车周围装了一圈测距雷达,按固定顺序输出一维距离向量,那么无论把小车放到什么地方,这些信息所代表的含义也不会变;或者采用imagelike的状态表示方式,把地图信息网格化,无论是作为二维channel或拉成一维向量,都能保持外在形式的统一。


针对上述第二种方案,为了将信息离散化到网格点上,不可避免地会带来精度损失。但在实际应用中,只要网格尺寸合理,这样的精度损失是可以接受的。事实上,离散化操作本身会在一定程度上降低学习难度从而带来性能的提升,有paper报告在Montezuma’s Revenge游戏里通过离散化agent和环境的信息,DRL模型性能不仅没有下降,反倒提升了30%多。
逻辑统一
状态空间只做到外在形式统一是不够的。比如我们把小车当前位置 ( x 0 , y 0 ) \left(x_{0},y_{0}\right) (x0,y0)和终点位置坐标 ( x 1 , y 1 ) \left(x_{1},y_{1}\right) (x1,y1)作为状态信息同时输入网络,按照DRL的过拟合天性,神经网络最终会记住这张地图每个坐标处的特征以及在这里通行的最佳路线,policy在这幅地图里测试性能会很高,但换幅地图就完全不能用了。通常情况下,我们并不希望DRL用这种方式获得高性能,而是希望它能学会应对不同地形的通用知识,即使换张地图也至少能达到“勉强能用”的地步,再通过在新地图中finetune即可快速具备实用价值。因此,更合理的方式是将两个绝对坐标合并为一个相对坐标 ( x 1 − x 0 , y 1 − y 0 ) \left(x_{1}-x_{0},y_{1}-y_{0}\right) (x1−x0,y1−y0),即终点位置在小车坐标系中的坐标,这样就可以使policy与具体地图“脱钩”,从而学习到更加通用的导航知识。可见,要想让网络学到我们希望它学到的知识,前提是输入正确形式的状态信息。
再说回上一节的自动充电任务,如果输入的是绝对电量,而不包含低电量阈值(预警电量),DRL模型需要通过大量探索,根据当前电量与是否被惩罚的经验去摸索出预警电量是多少,并用于指导action的生成。这个隐性阈值会固化到网络参数中,如果客户后续希望提升预警电量,policy就又要用新阈值重新训练了。为了避免这种情况,我们可以把绝对电量改为相对电量(绝对电量/预警电量),能够直接反映当前电量与预警电量的关系,即使预警电量被改变也不影响模型的使用,因为此时固化到网络参数中的知识不再是某个电量阈值而是比例阈值。
效果验证
当我们设计好状态空间或对原状态空间进行修改后,接下来需要通过实验验证其是否达到预期效果。验证方法可以分为三类:模仿学习验证,直接验证和缺省验证。
模仿学习验证
如果项目已经有一个较好的baseline,可以搭建一个policy网络,专门模仿该baseline在各种状态下的action,如果状态中包含了正确决策所需的相关信息,那么得到的policy性能就会越接近baseline。考虑到有监督学习的高效性,这是验证状态信息有效性的一种较快方式,尤其适用于项目初期一片懵懂的时候。
直接验证
如果没有这样的baseline,那就只能用直接验证了,即用DRL训练一个policy并验证其效果。为了提升效率,可以只比较训练中途(固定步数、固定数据量)的性能,因为一般情况下好状态和差状态的won-lost关系在较早的时候就确定了。另外由于DQN收敛速度相对较快,可以优先考虑用来验证新状态。

缺省验证
当我们已经训练得到一个不错的policy时,可以用缺省的方式验证每个状态信息的作用大小,即正常输入其他信息,而将目标信息取合理区间内的定值(如区间中点),测试性能损失的百分比。损失越大说明该状态信息越关键,反之则说明作用越边缘化,有时候甚至会发现性能不降反升,说明该信息有干扰作用,还是去掉的好。缺省验证的意义在于,剔除那些无用或起反作用的状态,为进一步优化关键状态和弱作用状态提供指导。
总结
与学术研究不同,在DRL落地工作中,状态空间设计是如此的重要,所以我用了很长的篇幅探讨了其中各种细节。此外,尽管我已经十分克制,但仍然不得不引入了大量关于回报函数(reward)的描述和设计理念,这是因为在实践中,状态空间和回报函数的设计几乎是水乳交融的,很难做到泾渭分明,往往修改了其中一个,另一个也需要相应做出改变。在下一篇中,我将集中介绍回报函数的设计,当然难免也会涉及到一些状态空间设计的内容,总之,一起服用效果更佳~