AutoGluon-教程1-简单的入门模型
写在前面
因为本人实在是懒,而且有关于机器学习和深度学习的基础知识不是很牢固,但又想着借着人工智能高大上的旗号整出一些好玩的模型,这边听说有一个模块能简简单单的就构建出深度学习模型,而且调参出的效果还比较好,碍于网上没啥教程,那我能怎么办,自己边看边写喽。
参考链接:
github源码地址:https://github.com/awslabs/autogluon
官网教程:https://auto.gluon.ai/stable/index.html
安装
目前该模块只适用于Linux与Mac系统,windows模块正在开发当中。各位想尝鲜的话,可以在windows装wsl,然后利用下面的语句安装模块
python3 -m pip install -U pip
python3 -m pip install -U setuptools wheel
python3 -m pip install autogluon
# cpu 版
python3 -m pip install -U "mxnet<2.0.0"
# gpu版
# Here we assume CUDA 10.1 is installed. You should change the number
# according to your own CUDA version (e.g. mxnet_cu100 for CUDA 10.0).
python3 -m pip install -U "mxnet_cu101<2.0.0"
库功能
其实这个库要完成的任务分成了几个教程,分别是表格预测、图像预测、目标检测、文本预测等,这篇先完成第一个教程表格预测
表格预测(Tabular Prediction)
定义:根据个人的理解,这个表格预测应该是属于输入数据是表格,然后根据这些信息再做相关的机器学习任务。
优点:无需数据清洗、特征工程、超参优化、模型选择
示例1
目的:预测一个人的收入是否超出5万美元
导入数据,构建对象
# import data
import pandas
import numpy
from autogluon.tabular import TabularDataset, TabularPredictor
train_data = TabularDataset('https://autogluon.s3.amazonaws.com/datasets/Inc/train.csv')
subsample_size = 500 # subsample subset of data for faster demo, try setting this to much larger values
train_data = train_data.sample(n=subsample_size, random_state=0)
train_data.head()

这边构造的AutoGluon Dataset对象,也就是TabularDataset是等同于pandas的data.frame的,所以可以用pandas.dataframe的属性来使用它,比如上面说的train_data.head()。同样的,如果你有自己的数据的话,可以按照下面这张图片提示构造对象
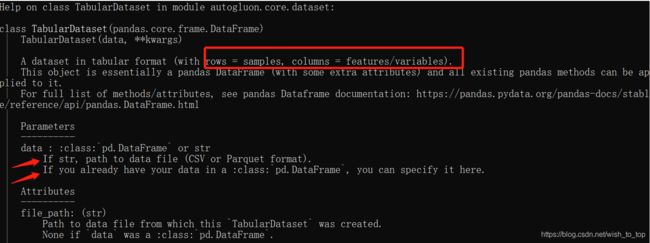
反正万事不决时就查帮助文档嘛
label = 'class'
pd.value_counts(train_data[label]) # 或train_data[label].value_counts()
# 上面两种方式视个人习惯
# 看下标签有哪些,以及对应标签的个数

训练模型
save_path = 'agModels-predictClass' # specifies folder to store trained models
predictor = TabularPredictor(label=label, path=save_path).fit(train_data)
save_path用来指定训练模型的文件夹
然后直接TabularPredictor进行模型构建

上面这张图很好玩哈,就是大概说明了为什么推断是二分类任务,如果不准的话如何修改,还有就是我们现在的可用内存是多少

然后。。。哈哈哈,笔记本太垃圾了,还可以自动根据内存调整参数
加载测试集并验证
# load test set
test_data = TabularDataset('https://autogluon.s3.amazonaws.com/datasets/Inc/test.csv')
y_test = test_data[label] # values to predict
test_data_nolab = test_data.drop(columns=[label]) # delete label column to prove we're not cheating
test_data_nolab.head()
predictor = TabularPredictor.load(save_path) # unnecessary, just demonstrates how to load previously-trained predictor from file
# model evalute
y_pred = predictor.predict(test_data_nolab)
print("Predictions: \n", y_pred)
perf = predictor.evaluate_predictions(y_true=y_test, y_pred=y_pred, auxiliary_metrics=True)

大概就展示下测试集的数据概况
然后就是结果了,都是一些基本的模型评估指标,没有想到的是同样的数据,同样的代码训练出来的结果竟然会比官网的好那么一点点,可能是因为不同的运行环境导致的吧,但差别不大,也就差了4个百分点
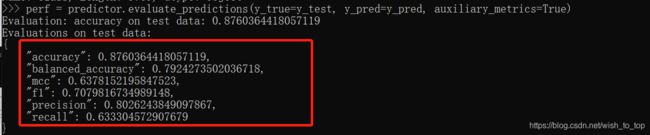
展示所有预训练模型在测试集的效能
predictor.leaderboard(test_data, silent=True)

由分类精度得知,predictor.predict(test_data_nolab)这个时候用的是WeighEnsemble_L2模型
到目前为止,训练第一个简单模型就完成啦,但是我想看这个模型的具体参数呢,这个就需要后面进行探索了,我也会发布后续的教程。第一次是教程,如有不合理的地方,请指出。
展示特定分类器的精度
predictor.predict(test_data, model='LightGBM')
额外部分
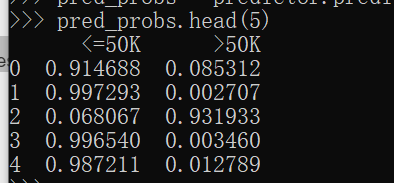
输出预测概率
pred_probs = predictor.predict_proba(test_data_nolab)
pred_probs.head(5)
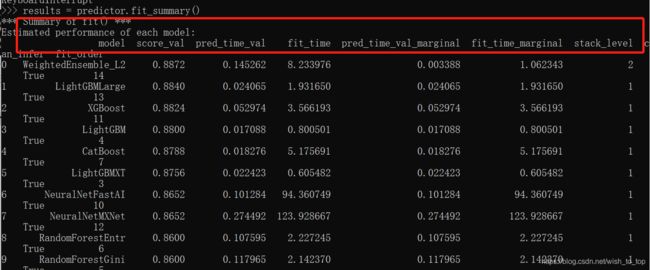
拟合过程中发生了什么
results = predictor.fit_summary()
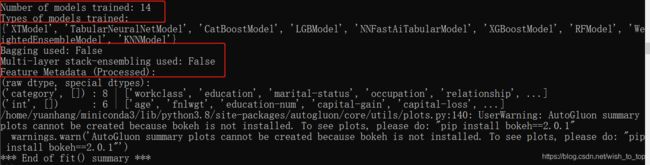
更高的输出精度
- time_limit : 模型训练的最长等待时间,通常不设置
- eval_metric: 评估指标,AUC还是精度等
- presets: 默认为’medium_quality_faster_train’,损失了精度但是速度比较快。要是设置为“best_quality”,则会做做bagging和stacking以提高性能
time_limit = 60 # for quick demonstration only, you should set this to longest time you are willing to wait (in seconds)
metric = 'roc_auc' # specify your evaluation metric here
predictor = TabularPredictor(label, eval_metric=metric).fit(train_data, time_limit=time_limit, presets='best_quality')
predictor.leaderboard(test_data, silent=True)