利用卡方检验进行特征选择
1 统计学上卡方检验
卡方检验就是统计样本的理论频次和实际频次的吻合程度或拟合优度。卡方值越大,二者偏离程度就越大。卡方值为0,则表明与理论值完全相符。其计算公式如下:
![]() ,其中,
,其中, 为实际值,
为实际值,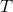 为理论值。以喝牛奶和感冒发病率之间的数据为例,
为理论值。以喝牛奶和感冒发病率之间的数据为例,
| 感冒 | 不感冒 | 合计 | 感冒率 | |
|---|---|---|---|---|
| 喝牛奶 | 43 | 96 | 139 | 30.94% |
| 不喝牛奶 | 28 | 84 | 112 | 25.00% |
| 合计 | 71 | 180 | 251 | 28.29% |
其计算代码如下:
import pandas as pd
import numpy as np
data=[('喝牛奶','感冒')]*43+[('不喝牛奶','感冒')]*28+[('喝牛奶','不感冒')]*96+[('不喝牛奶','不感冒')]*84
data=pd.DataFrame(data,columns=['feat1','feat2'])
#求其卡方值
result=data.groupby(['feat1','feat2'])['feat2'].count().unstack()
col_exp_dict=data['feat2'].value_counts(normalize=True)
result['All']=result.sum(axis=1)
cols=result.columns[:-1]
for col in cols:
result[col+'_exp']=result['All']*col_exp_dict[col]
sum_chi=0
for col in cols:
sum_chi+=((result[col]-result[col+'_exp'])**2/result[col+'_exp']).sum()
print(sum_chi) #sum_chi=1.072 用于特征选择的卡方检验
卡方检验还可以用于特征选择。Sklearn中提供了chi2()方法计算卡方,但这里的卡方计算和第1部分中介绍的卡方计算不一样。以下面代码为例进行说明:
import pandas as pd
import numpy as np
from sklearn.datasets import load_iris
from sklearn.feature_selection import SelectKBest
from sklearn.feature_selection import chi2
iris=load_iris()
X,y=iris.data,iris.target
chivalue=chi2(X, y)
result=pd.DataFrame(chivalue[0],index=['feat1','feat2','feat3','feat4'])
##用下面这段代码可以复现出与chi2()函数结果相同的卡方值
##即:result的结果和resul_1的结果相同
#chi2(x,y)计算的主要过程如下:
#1)首先将X中的每一列元素当作频次数据,chi2会判断X中是否所有元素都>0
#2) 针对X中的每一列元素,按y进行分组,对不同分组下的X求和 ,其结果即为实际值
#3)统计y中每个种类的占比,然后将X中的每一列元素的频次之和按比例分配到不同的y上,其结果即为理论值
#4)计算每个特征的卡方值
df=pd.DataFrame(np.concatenate((X,y.reshape(150,1)),axis=1),
columns=['feat1','feat2','feat3','feat4']+['target'])
observed=df.groupby('target')['feat1','feat2','feat3','feat4'].sum()
Y_per=np.array(df['target'].value_counts(normalize=True).sort_index())
feature_count=np.array(df[['feat1','feat2','feat3','feat4']].sum(axis=0))
expected=pd.DataFrame(np.dot(feature_count.reshape(-1,1),Y_per.reshape(1,-1)).T,
columns=['feat1','feat2','feat3','feat4'])
result_1=((observed-expected)**2/expected).sum()
##利用chi2()实现特征选择
#chivalue[0]为卡方值,chivalue[1]为对应的pvalue值
#feature_index返回前k个卡方值最大的特征对应的索引值
feature_index=SelectKBest(chi2,k=2).fit(X, y).get_support(indices=True)
#X_new为按chi2标准返回的前k个特征对应的X值,相当与X[:,list([feature_index])]
X_new=SelectKBest(chi2,k=2).fit_transform(X,y)注意:
(1) 卡方检验的假设是“两个事件是相互独立的”的,即当计算出的卡方值越大,则两个事件独立的概率就越小,相关性就越大。所以这里使用SelectKBest()挑选卡方值最大的前N个变量。
(2) 虽然在上述例子中使用了鸢尾花(数值型特征、回归问题)数据集,但卡方检验进行特征选择并不适用这种场景。其适用场景为:(1)非负取值的特征,比如逻辑性特征(取值为0和1)或频率型特征(其值表示的意义为频率)。(2)分类问题。
(3) 卡方检验是文本分类中常用的特征选择方法。
参考资料:
1. 【Python】sklearn.feature_selection chi2基于卡方,特征筛选详解_mjiansun的博客-CSDN博客_feature_selection.chi2