tensorflow2.0之seq2seq+attention模型和实例
什么是seq2seq
Seq2Seq模型是输出的长度不确定时采用的模型,这种情况一般是在机器翻译的任务中出现,将一句中文翻译成英文,那么这句英文的长度有可能会比中文短,也有可能会比中文长,所以输出的长度就不确定了。除了机器翻译像人机对话,情感分类等都可以用到seq2seq
seq2seq 是一个Encoder–Decoder 结构的网络,它的输入是一个序列,输出也是一个序列, Encoder 中将一个可变长度的信号序列变为固定长度的向量表达,Decoder 将这个固定长度的向量变成可变长度的目标的信号序列。这里看看常见的encoder-decoder结构,基本思想就是利用两个RNN,一个RNN作为encoder,另一个RNN作为decoder,除了RNN外LSTM,GRU也可以使用。
如图所示这是一个基于LSTM的seq2seq模型用来做问答系统。把你的问题作为encoder进行编码当成X输入,回答作为decoder进行编码当成label输出,中间经过语义编码,把encoder的输出当作decoder的输入
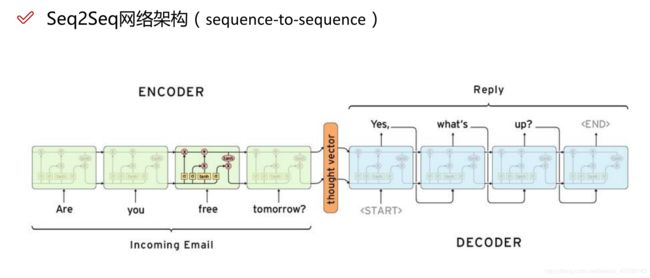
attention机制
attention机制是模仿人类注意力而提出的一种解决问题的办法,简单地说就是从大量信息中快速筛选出高价值信息。主要用于解决LSTM/RNN模型输入序列较长的时候很难获得最终合理的向量表示问题,做法是保留LSTM的中间结果,用新的模型对其进行学习,并将其与输出进行关联,从而达到信息筛选的目的。
为什么加入attention机制
首先 Encoder 将输入编码为固定大小状态向量(hidden state)的过程实际上是一个“信息有损压缩”的过程。如果信息量越大,那么这个转化向量的过程对信息造成的损失就越大。同时,随着 sequence length的增加,意味着时间维度上的序列很长,RNN 模型也会出现梯度弥散。最后,基础的模型连接 Encoder 和 Decoder 模块的组件仅仅是一个固定大小的状态向量,这使得Decoder无法直接去关注到输入信息的更多细节。因此加入attention机制对Encoder层状态的加权从而掌握输入语句中的所有细节信息。
实例-物品评价
这次实例用到的数据是一个评价以及评价总结的文本数据。如图所示,本次只用到了其中的两列。一列是Summary作为我们的Decoder一列作为我们的Encoder。

第一步:我们要先读取数据,获取我们需要的这两列数据,并把Text中的停用词和一些缩写词给分开并且清除其中的特殊符号等一些用处不大的单词。
def clean_text(text, remove_stopwords=True):
text = text.lower()
if True:
text = text.split()
new_text = []
for word in text:
if word in contractions:
new_text.append(contractions[word])
else:
new_text.append(word)
text = " ".join(new_text)
text = re.sub(r'https?:\/\/.*[\r\n]*', '', text, flags=re.MULTILINE)
text = re.sub(r'\, ' ', text)
text = re.sub(r'&', '', text)
text = re.sub(r'[_"\-;%()|+&=*%.,!?:#$@\[\]/]', ' ', text)
text = re.sub(r'
', ' ', text)
text = re.sub(r'\'', ' ', text)
if remove_stopwords:
text = text.split()
stops = set(stopwords.words("english"))
text = [w for w in text if not w in stops]
text = " ".join(text)
return text
处理后的结果如图所示,评价及总结。

第二步:再次读取这些数据,获取数据中的所有不重复的单词做成词映射。在获取所有单词以后再加入几个特殊的单词:["", “”, “”, “”] PAD是当你的文档长度小于统一的长度以后用PAD填充。UNK是一些未知的单词用UNK填充。GO和EOS是一句话的开头和结尾便于机器的识别,让机器知道什么时候开始什么时候就可以结束了。
vocab_words = []
def count_words( text):
for sentence in text:
for word in sentence.split():
if word not in vocab_words:
vocab_words.append(word)
special_words = ["" , "" , "" , "" ]
vocab_words = special_words + vocab_words
vocab2id = {word: i for i, word in enumerate(vocab_words)}
id2vocab = {i: word for i, word in enumerate(vocab_words)}
结果如图所示。

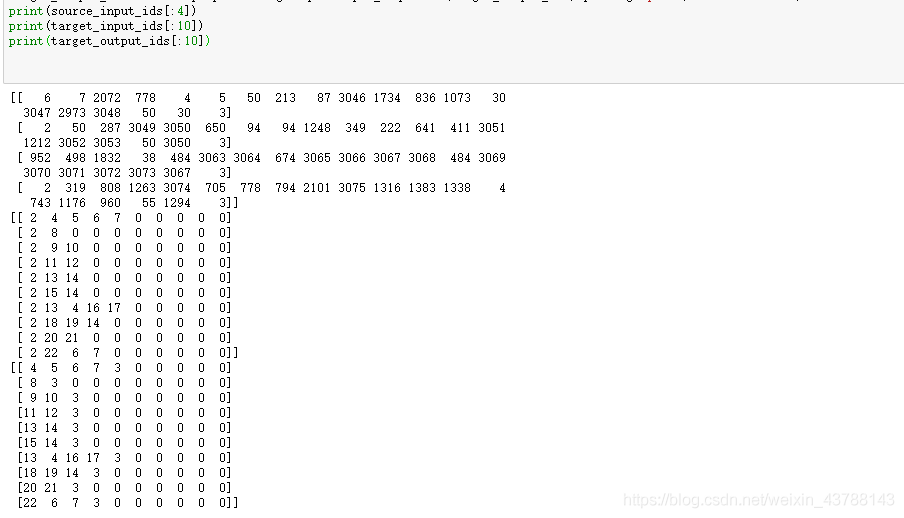
第三步 做完映射以后就可以把我们的文本数据进行转换了,把单词转换成对应的唯一数字。在把GO,EOS等特殊字符的向量放在每段话的评价的前面和后面,把GO放在总结评语的前面,组成我们的输入[source_input_ids, target_input_ids],把EOS再放在总结评语的后面当成我们的标签 target_output_ids,
然后再使用 keras.preprocessing.sequence.pad_sequences()方法把所有的数据长度进行统一。
def process_input_data(source_data_ids, target_indexs, vocab2id):
source_inputs = []
decoder_inputs, decoder_outputs = [], []
for source, target in zip(source_data_ids, target_indexs):
source_inputs.append([vocab2id["" ]] + source + [vocab2id["" ]])
decoder_inputs.append([vocab2id["" ]] + target)
decoder_outputs.append(target + [vocab2id["" ]])
return source_inputs, decoder_inputs, decoder_outputs
maxlen = 10
source_input_ids = keras.preprocessing.sequence.pad_sequences(source_input_ids, padding='post', maxlen=maxlen)
target_input_ids = keras.preprocessing.sequence.pad_sequences(target_input_ids, padding='post', maxlen=maxlen)
target_output_ids = keras.preprocessing.sequence.pad_sequences(target_output_ids, padding='post', maxlen=maxlen)
***第四步:***上面的代码就已经把我们的数据处理做完了,现在我们要做的就是把建立Seq2seq模型
一:编写Encoder,这里面包含一个embedding层和一个LSTM层
class Encoder(keras.Model):
def __init__(self, vocab_size, embedding_dim, hidden_units):
super(Encoder, self).__init__()
# Embedding Layer
self.embedding = Embedding(vocab_size, embedding_dim, mask_zero=True)
# Encode LSTM Layer
self.encoder_lstm = LSTM(hidden_units, return_sequences=True, return_state=True, name="encode_lstm")
def call(self, inputs):
encoder_embed = self.embedding(inputs)
encoder_outputs, state_h, state_c = self.encoder_lstm(encoder_embed)
return encoder_outputs, state_h, state_c
二:编写Decoder,有三部分输入,一是encoder部分的每个时刻输出,二是encoder的隐藏状态输出,三是decoder的目标输入。另外decoder还包含一个Attention层,计算decoder每个输入与encoder的注意力。
class Decoder(keras.Model):
def __init__(self, vocab_size, embedding_dim, hidden_units):
super(Decoder, self).__init__()
# Embedding Layer
self.embedding = Embedding(vocab_size, embedding_dim, mask_zero=True)
# Decode LSTM Layer
self.decoder_lstm = LSTM(hidden_units, return_sequences=True, return_state=True, name="decode_lstm")
# Attention Layer
self.attention = Attention()
def call(self, enc_outputs, dec_inputs, states_inputs):
decoder_embed = self.embedding(dec_inputs)
dec_outputs, dec_state_h, dec_state_c = self.decoder_lstm(decoder_embed, initial_state=states_inputs)
attention_output = self.attention([dec_outputs, enc_outputs])
return attention_output, dec_state_h, dec_state_c
三:把encoder和decoder模块合并,组成一个完整的seq2seq模型。
def Seq2Seq(maxlen, embedding_dim, hidden_units, vocab_size):
"""
seq2seq model
"""
# Input Layer
encoder_inputs = Input(shape=(maxlen,), name="encode_input")
decoder_inputs = Input(shape=(None,), name="decode_input")
# Encoder Layer
encoder = Encoder(vocab_size, embedding_dim, hidden_units)
enc_outputs, enc_state_h, enc_state_c = encoder(encoder_inputs)
dec_states_inputs = [enc_state_h, enc_state_c]
# Decoder Layer
decoder = Decoder(vocab_size, embedding_dim, hidden_units)
attention_output, dec_state_h, dec_state_c = decoder(enc_outputs, decoder_inputs, dec_states_inputs)
# Dense Layer
dense_outputs = Dense(vocab_size, activation='softmax', name="dense")(attention_output)
# seq2seq model
model = Model(inputs=[encoder_inputs, decoder_inputs], outputs=dense_outputs)
到此我们的模型已经建立。

第五步:把我们的数据输入到我们建立好的模型当中进行训练,并保存好训练好的模型
epochs = 49
batch_size = 32
val_rate = 0.2
loss_fn = keras.losses.SparseCategoricalCrossentropy()
model.compile(loss=loss_fn, optimizer='adam')
model.fit([source_input_ids, target_input_ids], target_output_ids,
batch_size=batch_size, epochs=epochs, validation_split=val_rate)
代码下载:https://download.csdn.net/download/weixin_43788143/12661025
代码参考:https://blog.csdn.net/qq_35549634/article/details/106603346?utm_medium=distribute.pc_relevant.none-task-blog-baidujs-5&spm=1001.2101.3001.4242