知识追踪理论入门
what
知识追踪(Knowledge Tracing)是根据学生过去的答题情况对学生的知识掌握情况进行建模,从而得到学生当前知识状态表示的一种技术。便我们能准确地预测学生对于各个知识概念的掌握程度,以及学生在未来学习行为的表现。准确可靠的知识追踪意味着我们可以根据学生的自身的知识状态,给他们推荐合适的练习题目,比如,推荐给学生薄弱知识概念关联的题目,而过于困难或者过于简单的题目不应该被推荐,从而可以给学生进行高效的个性化教学。
when
知识追踪模型是模拟学习者知识掌握情况的一个典型模型,由Atkinson 于1972 年首次提出,Corbett和Anderson,1995年将BKT引入智能教育领域,应用于智能教育系统(ITS)
霍索恩效应:指人们如果得知自己正在被研究或检测,行为表现就会有所增强。
How
为了解决知识追踪任务s首先要
进行用户交互建模,现有的建模方法依据反馈的时间分为下面两种.
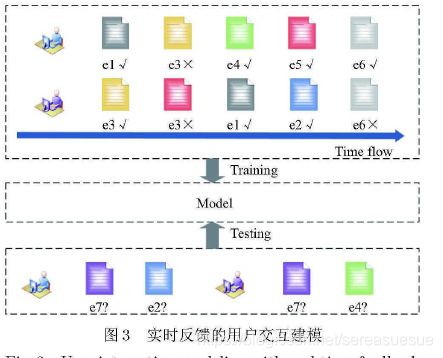
第一种建模方式为实时反馈的用户交互建模.
在现实中的棠些情况下学生完成一道习题后需要重刻更新模型中学生对于知识点的掌握情况倩息.比如在P常练习中,学生完成一道习题后可以立即得到反馈,学生的知识点掌握情况也随之发生变化.
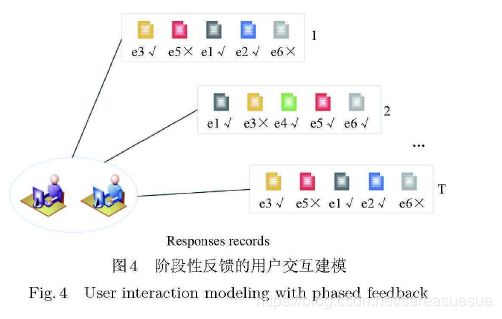
第二种建模方式为基于阶段性反馈的用户交互建模.
与上一种情况完全相反,某些情况下学生宗成一道习题不能够立即获得反馈,因此不能立刻更新模型中学生对于知识点的掌握情况.比如在考试时,学生完成一道题目后不可能立刻获取答案,因此考试过程中学生对于知识点的掌握程度变化不大
知识追踪模型
现有的知识追踪模型大致可以分为3类:基于概率图模型的知识追踪、基于矩阵分解的知识追踪以及基于深度学习的知识追踪参考:
贝叶斯知识追踪(BKT)-基于概率图模型的知识追踪
采用实时反馈的用户交互建模,将学习者的潜在知识状态建模为一组二元变量,每个突量代表是否理解某个知识,随着学生不断地练习,对于知识点的掌握也会有动态的变化,BKT通过利用隐马尔可夫模型(HMM)来维护代表知识点熟练度的二元变量{掌握该知识点,没掌握该知识点},原始的BKT模型假设学生一旦學会了技能,就永远不会被遗忘,最近有研究将学生的猜测和失误个体学习者的先验知识估计M以及问题难度估计等因素融入到BKT模型中
首先我们来看一下BKT的模型是如何的:
如下图,是BKT的一个模型,以及对应的4个主要参数,L0,T,G,S。模型需要根据学生以往的历史答题系列情况学习出这4个对应的参数。
BKT是对不同的的知识点进行建模的,理论上来说,训练数据有多少个知识点,就有多少组对应的(L0,T,G,S)参数。
L0:表示学生的未开始做这道题目时,或者为开始连续这项知识点的时候,他的一个掌握程度如何(即掌握这个知识点的概率是多少),这个一般我们可以从训练数据里面求平均值获得,也可以使用经验,比如一般来说掌握的程度是对半概率,那么L0=0.5
T :表示学生经过做题练习后,知识点从不会到学会的概率
G:表示学生没掌握这项知识点,但是还是蒙对的概率
S:表示学生实际上掌握了这项知识点,但是还是给做错了的概率
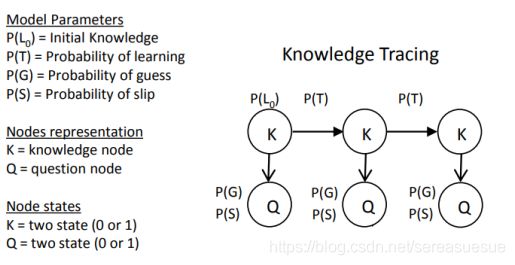
通过这4个参数,可以构造一个HMM的模型,剩下的事就是训练这个模型
基于矩阵分解的知识追踪
PMF 概率矩阵分解、由于推荐领域与知识追踪建模的相似性,部分学者将PMF算法改进应用于知识追踪领
域,本节主要阐述原始的PMF算法如何应用于知识追踪任务.
KPT:一个基于PMF的解释性的概率知识熟练度追踪模型,通过用教育先验来追踪学生知识熟练程度.具体而,KFT首先将每个练习与知识向量组关联,其中每一个元素代一个显性的知谀点.
深度知识追踪(DKT
https://blog.csdn.net/qq_40367479/article/details/105737469
优势:
模型可以反映出长时间的知识掌握程度,相比传统贝BKT假设知识一旦掌握了就不再会被遗忘,深度知识追踪引入循环神经网络模型可以很好地模拟知识长时间不做会被遗忘的行为,更加符合人们的认知。
能够对复杂的知识点间的联系进行建模,从而发现不同知识点间的内在联系。
不同于BKT用0/1来表示学生知识点掌握状态,DKT输出的 yt 是连续值,DKT可以反映出学生连续的知识水平变化。
当然深度知识追踪模型也是存在着缺点的 [4]:
模型存在无法重构的可能性,比如学生在此刻做对 i 知识点,但是某些情况下,模型认为下一刻对 i 知识点的掌握水平反而下降。
在时间序列上,学生存在对知识点掌握程度不连续的情况,部分学生的波动可能过大。
上述两个缺点可以通过修改损失函数进行解决,已有相关的论文对深度知识追踪模型进行改良,提出了对应的解决方案,并获得精度上进一步提升,同时对上面缺点中提到的问题有了很好的提升与修复。
[1]刘恒宇,张天成,武培文,于戈.知识追踪综述[J].华东师范大学学报(自然科学版),2019(05):1-15.
https://blog.csdn.net/qq_40367479/article/details/10573746
[1]艾方哲. 基于知识追踪的智能导学算法设计[D].北京交通大学,2019.
***** https://www.cnblogs.com/jiangxinyang/p/9732447.html
https://www.cnblogs.com/vwvwvwgwg/p/12833451.html