Huggingface-NLP笔记7:使用Trainer API来微调模型
「Huggingface NLP笔记系列-第7集」
最近跟着Huggingface上的NLP tutorial走了一遍,惊叹居然有如此好的讲解Transformers系列的NLP教程,于是决定记录一下学习的过程,分享我的笔记,可以算是官方教程的精简+注解版。但最推荐的,还是直接跟着官方教程来一遍,真是一种享受。
- 官方教程网址:https://huggingface.co/course/chapter1
- 本期内容对应网址:https://huggingface.co/course/chapter3/3?fw=pt
- 本系列笔记的GitHub Notebook(下载本地可直接运行): https://github.com/beyondguo/Learn_PyTorch/tree/master/HuggingfaceNLP
使用Trainer API来微调模型
1. 数据集准备和预处理:
这部分就是回顾上一集的内容:
- 通过dataset包加载数据集
- 加载预训练模型和tokenizer
- 定义Dataset.map要使用的预处理函数
- 定义DataCollator来用于构造训练batch
import numpy as np
from transformers import AutoTokenizer, DataCollatorWithPadding
import datasets
checkpoint = 'bert-base-cased'
tokenizer = AutoTokenizer.from_pretrained(checkpoint)
raw_datasets = datasets.load_dataset('glue', 'mrpc')
def tokenize_function(sample):
return tokenizer(sample['sentence1'], sample['sentence2'], truncation=True)
tokenized_datasets = raw_datasets.map(tokenize_function, batched=True)
data_collator = DataCollatorWithPadding(tokenizer=tokenizer)
2. 加载我们要fine-tune的模型:
from transformers import AutoModelForSequenceClassification
model = AutoModelForSequenceClassification.from_pretrained(checkpoint, num_labels=2)
>>> (warnings)
Some weights of the model checkpoint at bert-base-cased were not used when initializing BertForSequenceClassification: ['cls.predictions.bias', 'cls.predictions.transform.dense.weight', 'cls.predictions.transform.dense.bias', 'cls.predictions.decoder.weight', 'cls.seq_relationship.weight', 'cls.seq_relationship.bias', 'cls.predictions.transform.LayerNorm.weight', 'cls.predictions.transform.LayerNorm.bias']
- This IS expected if you are initializing BertForSequenceClassification from the checkpoint of a model trained on another task or with another architecture (e.g. initializing a BertForSequenceClassification model from a BertForPreTraining model).
- This IS NOT expected if you are initializing BertForSequenceClassification from the checkpoint of a model that you expect to be exactly identical (initializing a BertForSequenceClassification model from a BertForSequenceClassification model).
Some weights of BertForSequenceClassification were not initialized from the model checkpoint at bert-base-cased and are newly initialized: ['classifier.weight', 'classifier.bias']
You should probably TRAIN this model on a down-stream task to be able to use it for predictions and inference.
不得不说,这个Huggingface很贴心,这里的warning写的很清楚。这里我们使用的是带ForSequenceClassification这个Head的模型,但是我们的bert-baed-cased虽然它本身也有自身的Head,但跟我们这里的二分类任务不匹配,所以可以看到,它的Head被移除了,使用了一个随机初始化的ForSequenceClassificationHead。
所以这里提示还说:"You should probably TRAIN this model on a down-stream task to be able to use it for predictions and inference."
3. 使用Trainer来训练
Trainer是Huggingface transformers库的一个高级API,可以帮助我们快速搭建训练框架:
from transformers import Trainer, TrainingArguments
training_args = TrainingArguments(output_dir='test_trainer') # 指定输出文件夹,没有会自动创建
trainer = Trainer(
model,
training_args,
train_dataset=tokenized_datasets["train"],
eval_dataset=tokenized_datasets["validation"],
data_collator=data_collator, # 在定义了tokenizer之后,其实这里的data_collator就不用再写了,会自动根据tokenizer创建
tokenizer=tokenizer,
)
我们看看TrainingArguments和Trainer的参数都有些啥:
- https://huggingface.co/transformers/master/main_classes/trainer.html
- https://huggingface.co/transformers/master/main_classes/trainer.html#trainingarguments
TrainingArguments(
output_dir: Union[str, NoneType] = None,
overwrite_output_dir: bool = False,
do_train: bool = False,
do_eval: bool = None,
do_predict: bool = False,
evaluation_strategy: transformers.trainer_utils.EvaluationStrategy = 'no',
prediction_loss_only: bool = False,
per_device_train_batch_size: int = 8, # 默认的batch_size=8
per_device_eval_batch_size: int = 8,
per_gpu_train_batch_size: Union[int, NoneType] = None,
per_gpu_eval_batch_size: Union[int, NoneType] = None,
gradient_accumulation_steps: int = 1,
eval_accumulation_steps: Union[int, NoneType] = None,
learning_rate: float = 5e-05,
weight_decay: float = 0.0,
adam_beta1: float = 0.9,
adam_beta2: float = 0.999,
adam_epsilon: float = 1e-08,
max_grad_norm: float = 1.0,
num_train_epochs: float = 3.0, # 默认跑3轮
...
Trainer(
model: Union[transformers.modeling_utils.PreTrainedModel, torch.nn.modules.module.Module] = None,
args: transformers.training_args.TrainingArguments = None,
data_collator: Union[DataCollator, NoneType] = None,
train_dataset: Union[torch.utils.data.dataset.Dataset, NoneType] = None,
eval_dataset: Union[torch.utils.data.dataset.Dataset, NoneType] = None,
tokenizer: Union[ForwardRef('PreTrainedTokenizerBase'), NoneType] = None,
model_init: Callable[[], transformers.modeling_utils.PreTrainedModel] = None,
compute_metrics: Union[Callable[[transformers.trainer_utils.EvalPrediction], Dict], NoneType] = None,
callbacks: Union[List[transformers.trainer_callback.TrainerCallback], NoneType] = None,
optimizers: Tuple[torch.optim.optimizer.Optimizer, torch.optim.lr_scheduler.LambdaLR] = (None, None), # 默认会使用AdamW
)
Docstring:
Trainer is a simple but feature-complete training and eval loop for PyTorch, optimized for Transformers.
可见,这个Trainer把所有训练中需要考虑的参数、设计都包括在内了,我们可以在这里指定训练验证集、data_collator、metrics、optimizer,并通过TrainingArguments来提供各种超参数。
默认情况下,Trainer和TrainingArguments会使用:
- batch size=8
- epochs = 3
- AdamW优化器
定义好之后,直接使用.train()来启动训练:
trainer.train()
输出:
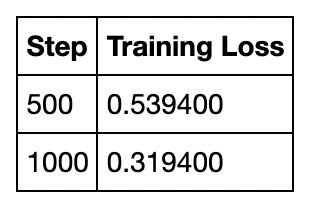
TrainOutput(global_step=1377, training_loss=0.35569445984728887, metrics={'train_runtime': 383.0158, 'train_samples_per_second': 3.595, 'total_flos': 530185443455520, 'epoch': 3.0})
然后我们用Trainer来预测:
trainer.predict()函数处理的结果是一个named_tuple(一种可以直接通过key来取值的tuple),类似一个字典,包含三个属性:predictions, label_ids, metrics
注意,这里的三个属性:
predictions实际上就是logitslabel_ids不是预测出来的id,而是数据集中自带的ground truth的标签,因此如果输入的数据集中没给标签,这里也不会输出metrics,也是只有输入的数据集中提供了label_ids才会输出metrics,包括loss之类的指标
其中metrics中还可以包含我们自定义的字段,我们需要在定义Trainer的时候给定compute_metrics参数。
文档参考: https://huggingface.co/transformers/master/main_classes/trainer.html#transformers.Trainer.predict
predictions = trainer.predict(tokenized_datasets['validation'])
print(predictions.predictions.shape) # logits
# array([[-2.7887206, 3.1986978],
# [ 2.5258656, -1.832253 ], ...], dtype=float32)
print(predictions.label_ids.shape) # array([1, 0, 0, 1, 0, 1, 0, 1, 1, 1, ...], dtype=int64)
print(predictions.metrics)
输出:
[51/51 00:03]
(408, 2)
(408,)
{'eval_loss': 0.7387174963951111, 'eval_runtime': 3.2872, 'eval_samples_per_second': 124.117}
然后就可以用preds和labels来计算一些相关的metrics了。
Huggingface datasets里面可以直接导入跟数据集相关的metrics:
from datasets import load_metric
preds = np.argmax(predictions.predictions, axis=-1)
metric = load_metric('glue', 'mrpc')
metric.compute(predictions=preds, references=predictions.label_ids)
>>>
{'accuracy': 0.8455882352941176, 'f1': 0.8911917098445595}
看看这里的metric(glue type)的文档:
Args:
predictions: list of predictions to score.
Each translation should be tokenized into a list of tokens.
references: list of lists of references for each translation.
Each reference should be tokenized into a list of tokens.
Returns: depending on the GLUE subset, one or several of:
"accuracy": Accuracy
"f1": F1 score
"pearson": Pearson Correlation
"spearmanr": Spearman Correlation
"matthews_correlation": Matthew Correlation
4.构建Trainer中的compute_metrics函数
前面我们注意到Trainer的参数中,可以提供一个compute_metrics函数,用于输出我们希望有的一些指标。
这个compute_metrics有一些输入输出的要求:
- 输入:是一个
EvalPrediction对象,是一个named tuple,需要有至少predictions和label_ids两个字段;经过查看源码,这里的predictions,就是logits - 输出:一个字典,包含各个metrics和对应的数值。
源码地址: https://huggingface.co/transformers/master/_modules/transformers/trainer.html#Trainer
from datasets import load_metric
def compute_metrics(eval_preds):
metric = load_metric("glue", "mrpc")
logits, labels = eval_preds.predictions, eval_preds.label_ids
# 上一行可以直接简写成:
# logits, labels = eval_preds 因为它相当于一个tuple
predictions = np.argmax(logits, axis=-1)
return metric.compute(predictions=predictions, references=labels)
总结一下这个过程:
- 首先我们定义了一个
compute_metrics函数,交给Trainer; Trainer训练模型,模型会对样本计算,产生 predictions (logits);Trainer再把 predictions 和数据集中给定的 label_ids 打包成一个对象,发送给compute_metrics函数;compute_metrics函数计算好相应的 metrics 然后返回。
看看带上了 compute_metrics 之后的训练:
training_args = TrainingArguments(output_dir='test_trainer', evaluation_strategy='epoch')
model = AutoModelForSequenceClassification.from_pretrained(checkpoint, num_labels=2) # new model
trainer = Trainer(
model,
training_args,
train_dataset=tokenized_datasets["train"],
eval_dataset=tokenized_datasets["validation"],
data_collator=data_collator, # 在定义了tokenizer之后,其实这里的data_collator就不用再写了,会自动根据tokenizer创建
tokenizer=tokenizer,
compute_metrics=compute_metrics
)
trainer.train()
输出:

TrainOutput(global_step=1377, training_loss=0.32063739751678666, metrics={'train_runtime': 414.1719, 'train_samples_per_second': 3.325, 'total_flos': 530351810395680, 'epoch': 3.0})
可见,带上了compute_metircs函数之后,在Trainer训练过程中,会把增加的metric也打印出来,方便我们时刻了解训练的进展。
前情回顾:
- Huggingface NLP笔记6:数据集预处理,使用dynamic padding构造batch
- Huggingface NLP笔记5:attention_mask在处理多个序列时的作用
- Huggingface NLP笔记4:Models,Tokenizers,以及如何做Subword tokenization
- Huggingface NLP笔记3:Pipeline端到端的背后发生了什么
- Huggingface NLP笔记2:一文看清Transformer大家族的三股势力
- Huggingface NLP笔记1:直接使用pipeline,是个人就能玩NLP