论文阅读《Momentum Contrast for Unsupervised Visual Representation Learning(MoCo)》
Background & Motivation
在 NLP 领域,无监督的学习方法已经取得了很大的成功,而在 CV 领域监督学习预训练的方法依然占主导地位。文中分析是因为语言任务是离散的信号空间(words,sub-word units),而视觉任务中原始信号是连续、高维的并且不像 words 那样是为人类交流构造的。
这是一篇用无监督的方法实现对比学习(contrastive learning)的文章, 此前的方法使用的代理任务(pretext task)都是都是 instance discrimination,将对比学习看作是查阅字典的操作(dictionary look-up)。
The term “pretext” implies that the task being solved is not of genuine interest, but is solved only for the true purpose of learning a good data representation.
pretext task 可以理解为代理任务,比如这篇文章里用的方法就是使用 instance discrimination 来作为代理任务。其他的代理任务比如最近凯明大神提出的 MAE 以及 denoising auto-encoding、context auto-encoding、colorization 等,代理任务的作用主要是为了学习出一个好的 data representation。
作者认为无监督方法,或者说自监督的方法包含两大方面:代理任务和目标函数。而 MoCo 主要是针对目标函数提出的创新。
如下图:

“正样本很多是正的相似,但是负样本却负的各有不同”,这句话虽然不太准确,但是描述了对比学习中的本质困难:如何去寻找合适并尽可能多的负样本去进行训练,从而让模型学习出足够能区分正负样本的特征?因此在对比学习中,对负样本有着海量的需求。
首先构建一个 dynamic dictionary,key 和 query 都是经过 encoder 编码后的特征,所有的 key 构成了这个 dictionary,需要用 query 进行对比学习。
Unsupervised learning trains encoders to perform dictionary look-up: an encoded “query” should be similar to its matching key and dissimilar to others. Learning is formulated as minimizing a contrastive loss.
文章希望构建足够 large 并且足够 consistent 的 dictionary,足够大才能够提取到 dictionary 中更具有判别性的特征,或者说那些可以将 key 和 query 辨别出来的特征。consistent 是指 key 应该由相同或者相似的 encoder 编码得来,因为如果 key 的编码器不是相似的是不同的,对比学习过程中 query 就有可能找到与其使用相似编码器编码出来的 key,而不是找到与其特征相似的 key。
此前两种经典的方法中对 dictionary 的处理方式不同。上图(a)中的方法将当前 batch 中的数据(key)作为 dictionary,但是 dictionary 的大小受 GPU 显存的限制,同样 large batch 的梯度更新也极具挑战性。上图(b)中的方法是构建一个 memory bank,这个 bank 里包含了数据集里所有的 key,每个 batch 随机采样一组 key,采样出来的 key 是需要被 updated 的。这就导致了 key 的编码是经过调整的,与上面说的 consistent 冲突。
Momentum Contrast
In this paper, we follow a simple instance discrimination task: a query matches a key if they are encoded views (e.g., different crops) of the same image.
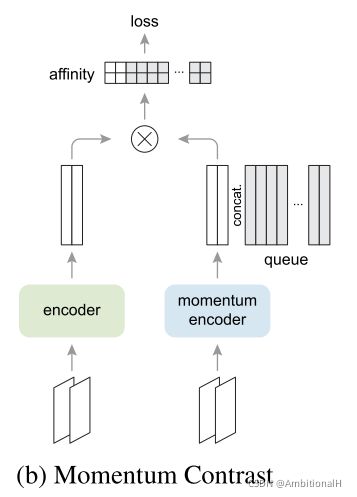
这里的 query 和与其匹配的 key+ 都是同一个 batch 中对每一张图片进行随机的增强后分别输入到 encoder 和 momentum encoder 中得到的,作为 positive pair,这样做的直觉是同一张图片经过不同增强后的特征差别是很小的。而 dictionary 中其他的 key 则是从 dictionary 保存的队列(即之前保存的 key,都是经过 momentum encoder 编码得到)中随机采样出来的,作为 negative pair。
Our hypothesis is that good features can be learned by a large dictionary that covers a rich set of negative samples.
backbone 可以采用 ResNet,其最后包含一个全连接层,并用 L2 泛化。使用 InfoNce contrastive loss:
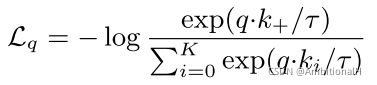
InfoNce 是从交叉熵损失函数发展而来,如果这里直接采用交叉熵损失函数,由于是无监督的方法,其分母上的 K 就为数据集中图像的数量,而不是监督学习方法中数据集的类别数。这样的话直接采用交叉熵损失函数就会带来巨大的计算开销。
于是考虑将其升级成 NCE loss,Noise Contrastive Estimation。将上述的多分类问题简化成二分类问题,即只包含 data sample 和 noise sample,这时模型只需要将 data 和 noise 进行对比学习即可。但是这里只解决了类别多的问题,如果将所有的数据都当作 noise sample,计算的复杂度依然没有降下来。所以只考虑采样一定的数据来近似整个数据集,这就是 Estimation 的含义,这里也是 MoCo 强调 dictionary 需要 large 的原因,越 large 对数据集的近似越好。
但 NCE loss 将所有的 noise sample 都看作负样本,但是 noise sample 中的 sample 很有可能不是一个类,如果采用这样简单的假设的话可能对模型的学习不友好,于是 NCE 就变成了 Info NCE。分母的 K 变为负样本的数量,dictionary 中负样本的数量。这里变成了基于 softmax 的 K+1 类的分类问题。
Dictionary as a queue
将每个 batch 中 momentum encoder 输出的 key 保存在一个队列中,当前 batch 进队,最早的 batch 出队,需要注意的是最早的 batch 与当前进队的 batch 是最不 consistent 的。这样就把 dictionary 的大小与 batch 的大小解耦,避免了 GPU 显存的限制。这是本文的第一个创新点,用以应对 large batch 的问题。
Momentum update
与 memory bank 类似的方法都无法使用梯度回传来更新 encoder 的参数,因为 bank 中的 key 过多。memory bank 采用的方法是更新 bank 中的 key,这就违反了 consistent。由于队列如何更新 momentum encoder 的参数,使其与 encoder 保持 consistent。一个最朴素直观的做法就是将 encoder 的梯度 copy 到 momentum encoder 上同时更新,但这样同样违反 consistent。因此提出了一个基于动量的 momentum update 的方法:

其中 m 是一个动量系数。encoder 的参数使用梯度下降更新,而 momentum encoder 的参数则使用上式更新。这样 momentum encoder 也保持了与 encoder 一致地更新,保持更新的 momentum encoder 是充分利用队列 dictionary 的核心。虽然队列中的 key 由不同的 momentum encoder 编码而成,但是每一个 batch 的 momentum encoder 之间的差异就尽可能的缩小了。这时本文的第二个创新点,用以应对 consistent 的问题。
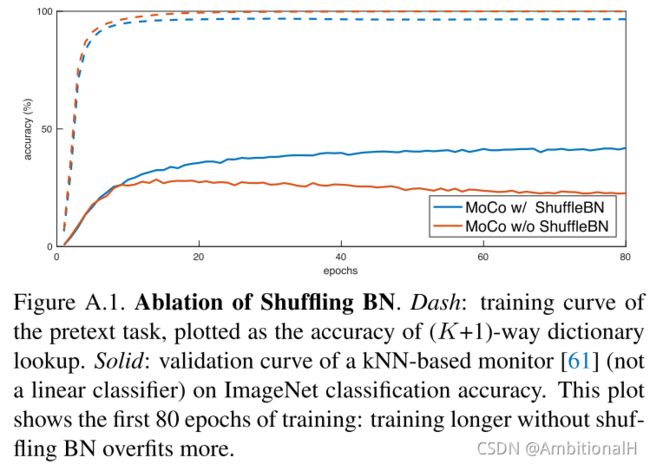
Shuffling BN
是本文经过实验提出的一个 trick,在实验中 Batch Normalization 妨碍了模型学习好的特征表征,文章解释可能是因为 intra-batch 的交流造成了信息的泄露。
The model appears to “cheat” the pretext task and easily finds a low-loss solution.
如下图,BN 是在 N*F(C 是通道,N 是 batch size,F 是特征)的通道上,因此 BN 可能会将负样本的信息“泄漏”到正样本中去。这样在后面进行 contrastive loss 计算的时候会导致模型不断地强化这种“泄露”,造成低损失的表象,但是特征学习的并不好。
另一种解释:the sub-batch statistics can serve as a “signature” to tell which sub-batch the positive key is in.
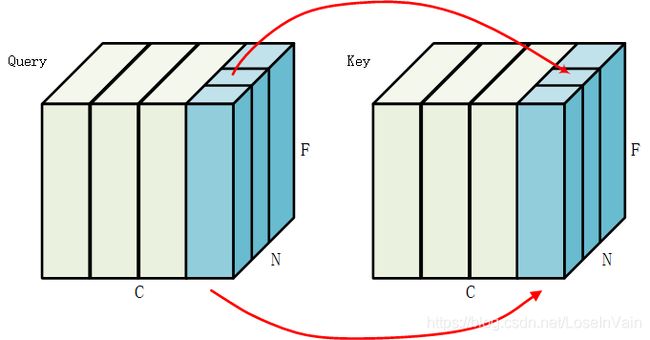
Shuffling BN 的做法是:对于 momentum encoder,在将当前 batch 中的数据分布到多卡之前将顺序打乱,在完成编码后再将其还原回原来的顺序。而 encoder 的数据顺序则没有改变。
This ensures the batch statistics used to compute a query and its positive key come from two different subsets.
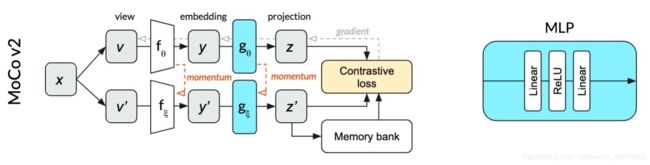
Momentum Contrast V2
模仿 SimCLR,将 backbone 中最后一层的全连接层换成了 MLP;并且加入了 SimCLR 中数据增强的方法。
Experiment
Linear Classification Protocol
使用 MoCo 的方法预训练模型,之后 freeze backbone,微调后面的 classifier。
ImageNet 上的分类准确率,三种方法:

值得注意的是这里使用的学习率竟然是30。。这似乎也暗示了监督学习的方法学到的特征和自监督方法学习到的特征有很大差异。
其中 K 是负样本数。对 Momentum update 中的 m 进行了消融实验:
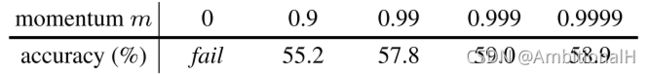
m 为 0.99 时精度最高,即缓慢更新 momentum update 时,取得的效果最好。参数与精度的关系:

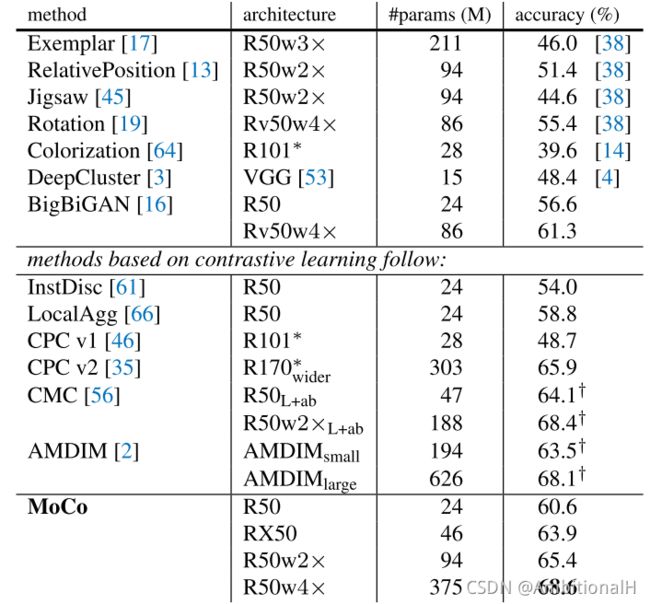
Transferring Features
这个实验是为了验证 MoCo 学习到的特征的可迁移度,即 transferrable。
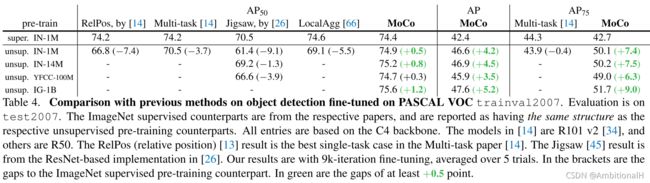
在检测任务上的精度,VOC:

R50-C4 的效果更好,高于监督学习的方法。R50-C4 即原始的 ResNet。
_BASE_: "../Base-RCNN-C4.yaml"
MODEL:
WEIGHTS: "detectron2://ImageNetPretrained/MSRA/R-50.pkl"
MASK_ON: True
RESNETS:
DEPTH: 50The relation between pre-training vs. detector structures has been veiled in the past, and should be a factor under consideration.
同时为了证明是 MoCo 的作用而不是 Faster Rcnn 的功劳,在另外两种方法上进行对照实验:
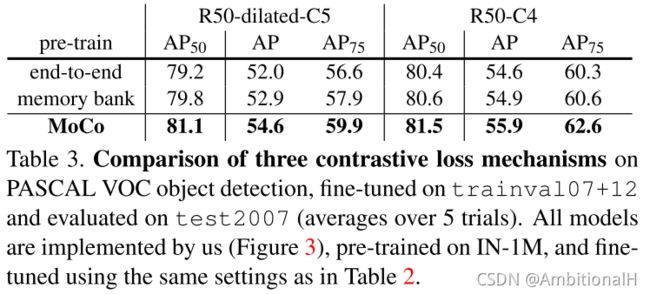
可以看到 MoCo 全面压制。
MS COCO:
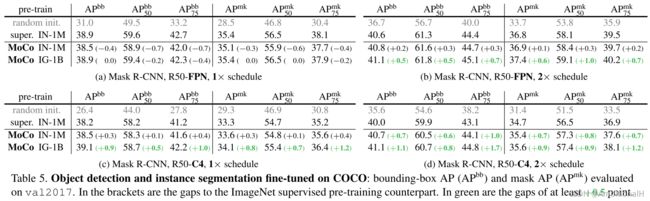
原始 ResNet 的效果比 ResNet+FPN 要好?大佬不辞辛苦,验证了 MoCo 在其他任务上的精度:
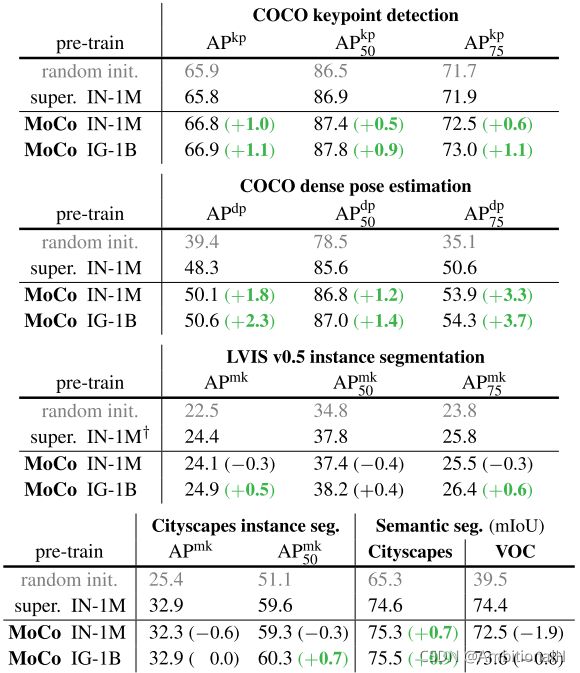
In sum, MoCo can outperform its ImageNet supervised pre-training counterpart in 7 detection or segmentation tasks.
Namely, object detection on VOC/COCO, instance segmentation on COCO/LVIS, keypoint detection on COCO, dense pose on COCO, and semantic segmentation on Cityscapes.
对 Shuffling BN 进行了消融实验:
对 MoCo V2 中的改进进行了消融实验:
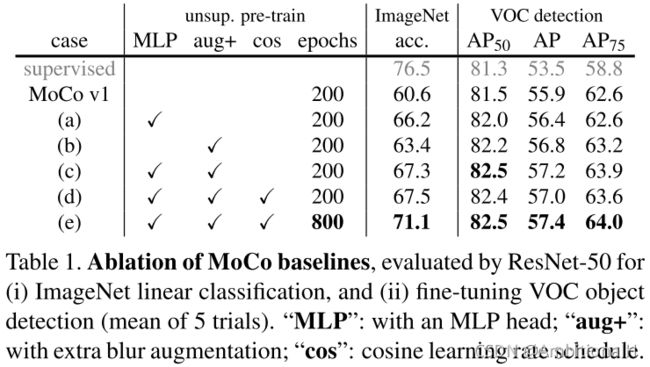
MoCo V2 在 ImageNet 上的分类精度:
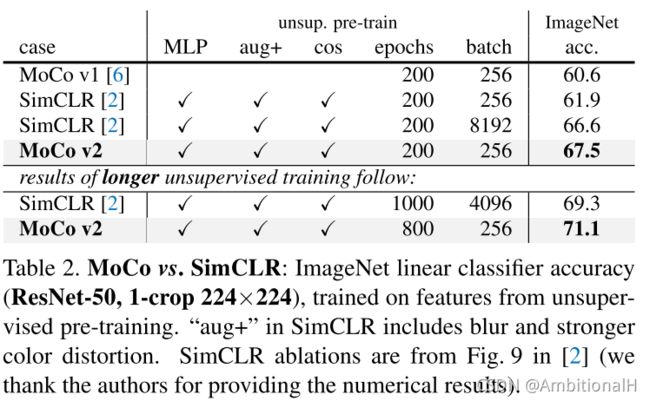
可见 V2 足足提了10个点。

Conclusion
按论文原话:MoCo has largely closed the gap between unsupervised and supervised representation learning in multiple vision tasks.
IG-1B 上的效果比 IN-1M 的效果并没有好很多,但是数据量前者是后者的倍数,说明 MoCo 并没有完全地利用大数据集内的特征。
真不是炼丹 务实敢为的 MoCo v3 【论文阅读】 - 知乎