深度学习(自监督:MoCo)——Momentum Contrast for Unsupervised Visual Representation Learning
文章目录
- 前言
- 自监督简述
- MoCo简述
-
- 如何产生正例
- 如何产生负例
- 如何更新momentum encoder
- 算法伪代码
- 思考
-
- 为什么要存在负例
- MoCo的负例通过queue提供有什么好处
- 为什么需要momentum encoder
前言
本篇文章是何凯明老师在CVPR 2020上的文章
文章地址:链接
代码地址:链接
本文前半部分将对自监督任务做一个简短介绍,包括自监督任务中常见的损失函数——InfoNCE、自监督的用途、自监督的评估方式,后半部分将对MoCo做一个介绍,具体的实验结果请自行查阅原论文。
如有错误,欢迎指正。
自监督简述
自监督无需人工标注标签,其让海量数据自身产生伪标签,将伪标签作为监督信号,训练特征提取器,训练得到的特征提取器将用于下游任务,例如图像分割、目标检测、图像分类等任务。
目前自监督领域有诸多流派,近年来的主流流派为对比学习(Contrastive Learning),一张图片经过不同的数据增强后产生的feature vector也应该是近似的,对比学习试图通过这种对应关系,让模型理解一张图片中的语义信息。
对比学习中,最常用的损失函数为InfoNCE,其数学形式为

其中, T T T为温度,是一个超参数, q q q表示样本的特征向量, k + k_{+} k+表示正例的特征向量。
每个训练样本,都有一个正例, K K K个负例,InfoNCE会计算样本与正负例之间的余弦相似度,通过softmax函数进行归一化,接着套入负对数函数中。
InfoNCE可以看成一个K+1类的分类问题(损失函数为交叉熵),我们希望样本能够被分为第 k + k_{+} k+类,即样本与正例的余弦相似度要高于与负例的余弦相似度。
自监督训练完一个特征提取器后,会将特征提取器冻结,接入一个线性分类器,依据线性分类器的性能好坏来判断特征空间的好坏,如果在分类问题中,特征提取器构建出的特征空间线性可分,则可认为该特征提取器性能优异,也可以将特征提取器用于其他下游任务中,依据下游任务的性能来判断特征提取器性能好坏。
MoCo简述
本论文提出的MoCo模型,是自监督算法的一种,本节将介绍MoCo是如何进行自监督训练的,并给出一些个人的思考
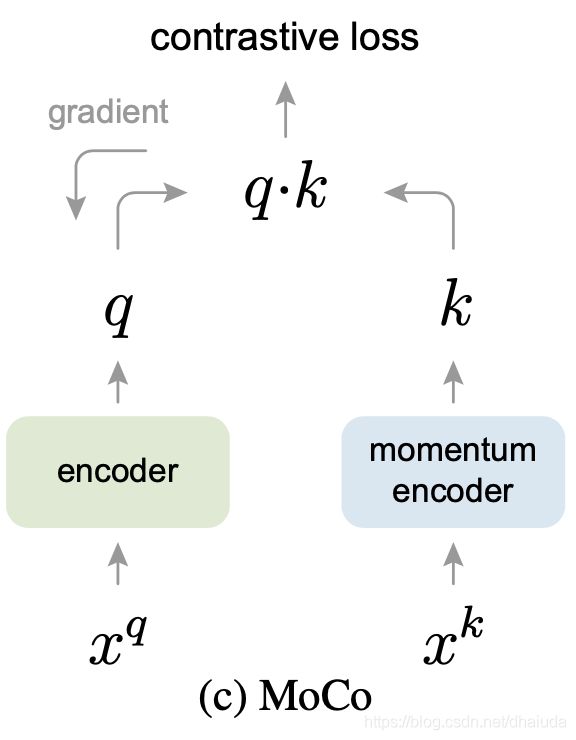
MoCo的网络结构如上,InfoNCE需要提供正、负例才可以计算,那么MoCo中正负例是如何产生的?
如何产生正例
在MoCo中,对一张图片进行不同的数据增强,得到 x q x^q xq和 x k x^k xk,两张图片分别输入到encoder和momentum encoder卷积神经网络中,momentum encoder的输出即为正例。背后的直觉为一张图片经过不同的数据增强后产生的feature vector也应该是近似的,对比学习试图通过这种对应关系,让模型理解一张图片中的语义信息。
如何产生负例
momentum encoder输出的feature vector会保存在一个queue中,queue的大小固定,当queue容量达到上限时,会抛弃队列头部的feature vector,存入新的feature vector。MoCo的负例来源于queue中保存的feature vector,应该是随机采样一部分feature vector作为负例。负例对不会产生更新梯度
如何更新momentum encoder
InfoNCE的梯度并不会回传至momentum encoder,momentum encoder采用动量方式进行更新,具体更新方式如下式
θ k = m θ k + ( 1 − m ) θ q (2.0) \theta_k=m\theta_k+(1-m)\theta_q \tag{2.0} θk=mθk+(1−m)θq(2.0)
θ k \theta_k θk为momentum encoder的参数, θ q \theta_q θq为encoder的参数,m的取值通常近似于1。
算法伪代码

思考
为什么要存在负例
一张图片经过不同的数据增强后产生的feature vector也应该是近似的,对比学习试图通过这种对应关系,让模型理解一张图片中的语义信息。从对比学习的motivation出发,似乎不需要负例,但在实际训练中,对比学习可能出现奔溃解,即不论输入任何数据,网络的输出均为一个常数,如果仅使用正例,奔溃解会存在于网络的解空间中,负例的引入会消除解空间中的奔溃解。
MoCo的负例通过queue提供有什么好处
类似于simCLR,负例可以由一个batch中的其他数据组成,但此时负例对只能来源于同一个batch的数据。通过queue提供负例,负例的来源范围更广,可以来自于不同batch的数据,并且负例不会产生梯度,计算量可以得到下降,使用的显存量会下降,同时训练模型的难度也会下降。
一句话概括,相比于simCLR,通过queue提供负例,可以减少负例增多导致的计算量增多。
对于使用负例的对比学习算法而言,负例越多通常性能会越好,因此对batch size大小较为敏感,如下图所示,K为负例的个数,三类算法都需要负例。

为什么需要momentum encoder
从对比学习的motivation出发,更本不需要momentum encoder,但实验表明momentum encoder可以提升自监督模型的性能,如下表所示:
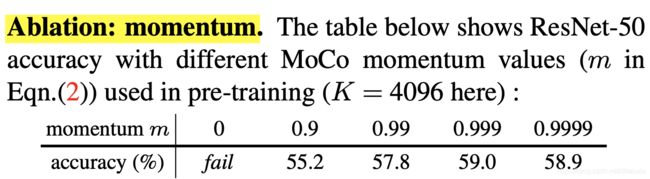
当m=0时(m即式2.0中的超参数),即不存在momentum encoder,此时无法训练,作者猜测若不存在momentum encoder,在特征空间中,负例的分布非常离散,网络难以进行优化,momentum encoder的更新方式,使得特征空间中,负例的分布更为集中(consistency),网络更容易优化,个人不是很认可,下面通过一个问题,谈谈我对momentum encoder的理解。
momentum encoder与encoder为两个模型,两者映射的特征空间是不一样的,同时由于参数的不断更新,不同负例所处的特征空间是不一致的,为什么两者产生的feature vector可以直接比较?
从上表可以看出,当m越趋近于1,性能越好,此时momentum encoder参数更新缓慢,特征空间的变化速度非常缓慢,queue中的不同负例可以近似看成位于一个特征空间中(注意到queue会丢弃头部的feature vector)。encoder输出的feature vector会经过一个fc层处理,进行特征空间转换,将样本转换到momentum encoder所处的特征空间中,从而使得样本、正例、负例之间可以相互比较。
当m趋近于0,性能变差,此时momentum encoder的参数变化剧烈将导致特征空间变化速度很快,queue中不同负例存在于不同的特征空间中,导致负例、正例之间不可以进行比较,从而难以优化。
一句话概括,如果我们想使用queue中的负例,就需要momentum encoder。