吃瓜教程task05 第6章 支持向量机
第6章 支持向量机
2022/6/2 雾切凉宫 至6.5节/视频P9
文章目录
- 第6章 支持向量机
-
- 6.1 间隔与支持向量
-
- p8 支持向量机
-
-
- 超平面
- 几何间隔
- 支持向量机
-
- 6.2 对偶问题
-
-
-
- 凸优化问题/拉格朗日对偶
- 解算支持向量机
-
-
- 6.4 软间隔与正则化
-
- p9 软间隔与支持向量回归
-
- p9.1 软间隔
- 6.5支持向量回归
-
-
- p9.1 支持向量回归
-
6.1 间隔与支持向量
p8 支持向量机
超平面
n维空间的超平面 :
w T x + b = 0 , 其 中 w , x ∈ R n w^Tx +b= 0,其中w,x∈R^n wTx+b=0,其中w,x∈Rn
●超平面方程不唯一
●法向量w和位移项b确定一个唯一超平面
●法向量w垂直于超平面(缩放w, b时,若缩放倍数为负数会改变法向量方向)
●法向量w指向的那一半空间为正空间,另一半为负空间
●任意点x到超平面的距离公式为
r = ∣ w T x + b ∣ ∣ ∣ w ∣ ∣ [ 证 明 ] : 对 于 任 意 一 点 x 0 = ( x 1 0 , x 2 0 . . . . , x n 0 ) T , 设 其 在 超 平 面 w T x + b = 0 上 的 投 影 点 为 x 1 = ( x 1 1 , x 2 1 . . . , x n 1 ) T 则 w T x 1 + b = 0 , 且 向 量 x 1 x 0 → 与 法 向 量 w 平 行 , 因 此 ∣ w ∗ x 1 x 0 → ∣ = ∣ ∣ ∣ w ∣ ∣ ∗ c o s π ∗ ∣ x 1 x 0 → ∣ = ∣ ∣ w ∣ ∣ ∗ r w ∗ x 1 x 0 → = w 1 ( x 1 0 − x 1 1 ) + w 2 ( x 2 0 − x 2 1 ) + . . . + w n ( x n 0 − x n 1 ) = w T x 0 − w T x 1 = w T x 0 + b 由 w T x 0 + b = ∣ ∣ w ∣ ∣ ∗ r 得 r = ∣ w T x + b ∣ ∣ ∣ w ∣ ∣ r=\frac{|w^Tx+b|}{||w||}\\\\ [证明] :对于任意一点x_0 = (x_1^0, x^0_2....,x^0_n)^T,设其在超平面w^Tx + b= 0上的投影点为x1 = (x_1^1,x^1_2...,x_n^1)^T\\ 则w^Tx_1+b=0,且向量\overrightarrow{x_1x_0}与法向量w平行,因此\\ |w*\overrightarrow{x_1x_0}|= | ||w||*cosπ*|\overrightarrow{x_1x_0}|\\ = ||w||*r\\ w*\overrightarrow{x_1x_0}= w_1(x_1^0-x_1^1) +w_2(x_2^0-x_2^1)+... + w_n(x_n^0-x_n^1)\\ =w^Tx_0-w^Tx_1=w^Tx_0+b\\ 由w^Tx_0+b=||w||*r得\\ r=\frac{|w^Tx+b|}{||w||}\\ r=∣∣w∣∣∣wTx+b∣[证明]:对于任意一点x0=(x10,x20....,xn0)T,设其在超平面wTx+b=0上的投影点为x1=(x11,x21...,xn1)T则wTx1+b=0,且向量x1x0与法向量w平行,因此∣w∗x1x0∣=∣∣∣w∣∣∗cosπ∗∣x1x0∣=∣∣w∣∣∗rw∗x1x0=w1(x10−x11)+w2(x20−x21)+...+wn(xn0−xn1)=wTx0−wTx1=wTx0+b由wTx0+b=∣∣w∣∣∗r得r=∣∣w∣∣∣wTx+b∣
几何间隔
对 于 给 定 的 数 据 集 X 和 超 平 面 w T x + b = 0 , 定 义 数 据 集 X 中 的 任 意 一 个 样 本 点 ( x i , y i ) , y i ∈ − 1 , 1 , i = 1 , 2.... m 关 于 超 平 面 的 几 何 间 隔 为 γ i = y i ( w T x i + b ) ∣ ∣ w ∣ ∣ 对于给定的数据集X和超平面w^Tx +b= 0,定义数据集X中的任意一个样本点 (x_i,y_i),y_i∈{-1,1},i= 1,2.... m关于超平面的几何间隔为\\ γ_i =\frac{yi(w^Tx_i + b)}{||w||} 对于给定的数据集X和超平面wTx+b=0,定义数据集X中的任意一个样本点(xi,yi),yi∈−1,1,i=1,2....m关于超平面的几何间隔为γi=∣∣w∣∣yi(wTxi+b)
正确分类时:γi > 0,几何间隔此时也等价于点到超平面的距离
没有正确分类时: γi < 0
对于给定的数据集X和超平面w^Tx +b= 0,定义数据集X关于超平面的几何间隔为:数据集X中所有样本点的几何间隔最小值
γ = min i = 1 , 2 , . . . , m γ i γ=\min_{i=1,2,...,m}γ_i γ=i=1,2,...,mminγi
支持向量机
模型:给定线性可分数据集X,支持向量机模型希望求得数据集X关于超平面的几何间隔y达到最大的那个超平面,然后套上一个sign函数实现分类功能
y = s i g n ( w T x + b ) y= sign(w^Tx+b) y=sign(wTx+b)
所以其本质和感知机一样,仍然是在求一个超平面。那么几何间隔最大的超平面就一定是我们前面所说的那个“距离正负样本都最远的超平面"吗?
答:是的,原因有以下两点:
●当超平面没有正确划分正负样本时:几何间隔最小的为误分类点,因此γ < 0
●当超平面正确划分超平面时: γ≥0,且越靠近中央γ越大
策略:给定线性可分数据集X,设X中几何间隔最小的样本为(xmin, Ymin),那么支持向量机找超平面的过程可以转化为以下带约束条件的优化问题:
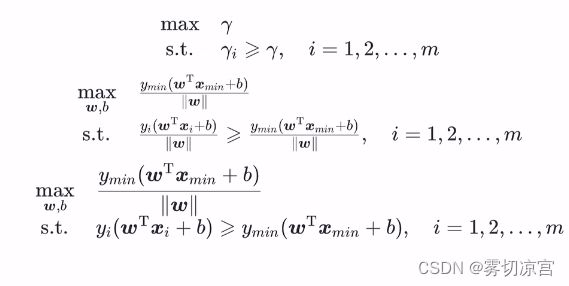
此优化问题为含不等式约束的优化问题,且为凸优化问题,因此可以直接用很多专门求解凸优化问题的方法求解该问题。在这里,支持向量机通常采用拉格朗日对偶来求解,具体原因待求解完后解释,下面先给出拉格朗日对偶相关知识。
6.2 对偶问题
凸优化问题/拉格朗日对偶
对于一般地约束优化问题:
m i n f ( x ) s . t . g i ( x ) ≤ 0 i = 1 , 2... , m h j ( x ) = 0 j = 1 , 2... , n min\quad f(x)\\ s.t.\quad g_i(x)≤0 \quad i= 1,2...,m \\ h_j(x)=0 \quad j= 1,2...,n minf(x)s.t.gi(x)≤0i=1,2...,mhj(x)=0j=1,2...,n
若目标函数f(x )是凸函数,约束集合是凸集,则称上述优化问题为凸优化问题,特别地,g;(x)是凸函数, hi(x)是线性函数时,约束集合为凸集,该优化问题为凸优化问题。显然,支持向量机的目标函数1/2||w||2是关于w的凸函数,对于上面的约束优化问题也是关于w的凸函数,因此支持向量机是一个凸优化问题。
对于上述优化问题有拉格朗日函数:
L ( x , μ , λ ) = f ( x ) + ∑ i = 1 m μ i g i ( x ) + ∑ j = 1 n λ i h i ( x ) 其 中 μ = ( μ 1 , μ 2 , . . . μ m ) T , λ = ( λ 1 , λ 2 , . . . , λ n ) T 为 拉 格 朗 日 乘 子 L(x,μ,λ)=f(x)+\sum^m_{i=1}μ_ig_i(x)+\sum^n_{j=1}λ_ih_i(x)\\ 其中μ=(μ_1,μ_2,...μ_m)^T,λ=(λ_1,λ_2,...,λ_n)^T为拉格朗日乘子 L(x,μ,λ)=f(x)+i=1∑mμigi(x)+j=1∑nλihi(x)其中μ=(μ1,μ2,...μm)T,λ=(λ1,λ2,...,λn)T为拉格朗日乘子
对于上述优化问题有拉格朗日对偶函数:
拉格朗日对偶函数为拉格朗日函数关于x的下确界
Γ ( μ , λ ) = inf x ∈ D L ( x , μ , λ ) = inf x ∈ D ( f ( x ) + ∑ i = 1 m μ i g i ( x ) + ∑ j = 1 n λ i h i ( x ) ) Γ(μ,λ)=\inf_{x∈D}L(x,μ,λ)=\inf_{x∈D}(f(x)+\sum^m_{i=1}μ_ig_i(x)+\sum^n_{j=1}λ_ih_i(x)) Γ(μ,λ)=x∈DinfL(x,μ,λ)=x∈Dinf(f(x)+i=1∑mμigi(x)+j=1∑nλihi(x))
- 对偶函数恒为凹函数
- μ≥0是,对偶函数Γ(μ,λ)构成上述最优化问题最优值的下界。
解算支持向量机
主问题:
min w , b 1 2 ∣ ∣ w ∣ ∣ 2 s . t . 1 − y i ( w T x i + b ) ≤ 0 , i = 1 , 2 , . . . , m \min_{w,b}\quad \frac{1}{2}||w||^2 \\ s.t.\quad 1-y_i(w^Tx_i+b)≤0,\quad i=1,2,...,m w,bmin21∣∣w∣∣2s.t.1−yi(wTxi+b)≤0,i=1,2,...,m
拉格朗日函数:
L ( w , b , α ) = 1 2 ∣ ∣ w ∣ ∣ 2 + ∑ i = 1 m a i ( 1 − y i ( w T x i + b ) ) = 1 2 ∣ ∣ w ∣ ∣ 2 + ∑ i = 1 m a i − ∑ i = 1 m α i y i w T x i − b ∑ i = 1 m α i y i 令 w ^ = ( w ; b ) 。 显 然 上 式 是 关 于 w ^ 的 凸 函 数 , 直 接 求 一 阶 导 令 其 等 于 0 , 然 后 带 回 即 可 得 到 最 小 值 , 也 即 拉 格 朗 日 对 偶 函 数 。 L(w,b,α)=\frac{1}{2}||w||^2+\sum_{i=1}^ma_i(1-y_i(w^Tx_i+b))\\ =\frac{1}{2}||w||^2+\sum_{i=1}^ma_i-\sum_{i=1}^mα_iy_iw^Tx_i-b\sum_{i=1}^mα_iy_i \\ 令\hat{w}=(w;b)。显然上式是关于\hat{w}的凸函数,直接求一阶导令其等于0,然后带回即可得到最小值,也即拉格朗日对偶函数。 L(w,b,α)=21∣∣w∣∣2+i=1∑mai(1−yi(wTxi+b))=21∣∣w∣∣2+i=1∑mai−i=1∑mαiyiwTxi−bi=1∑mαiyi令w^=(w;b)。显然上式是关于w^的凸函数,直接求一阶导令其等于0,然后带回即可得到最小值,也即拉格朗日对偶函数。
6.4 软间隔与正则化
p9 软间隔与支持向量回归
p9.1 软间隔
从数学角度来说,软间隔就是允许部分样本(但要尽可能少)不满足下式中的约束条件:
min w , b 1 2 ∣ ∣ w ∣ ∣ 2 s . t . y i ( w T x i + b ) ≥ 1 , i = 1 , 2 , . . . , m \min_{w,b}\quad \frac{1}{2}||w||^2 \\ s.t.\quad y_i(w^Tx_i+b)≥1,\quad i=1,2,...,m w,bmin21∣∣w∣∣2s.t.yi(wTxi+b)≥1,i=1,2,...,m
因此,可以将必须严格执行的约束条件转化为具有一定灵活性的“损失",合格的损失函数要求如下:
●当满足约束条件时,损失为0
●当不满足约束条件时,损失不为0,
●(可选)当不满足约束条件时,损失与其违反约束条件的程度成正比
只有满足以上要求,才能保证在最小化(min) 损失的过程中,保证不满足约束条件的样本尽可能的少。
min w , b 1 2 ∣ ∣ w ∣ ∣ 2 + C ∑ i = 1 m ι 0 / 1 ( y i ( w T x i + b ) − 1 ) 其 中 , ι 0 / 1 是 0 / 1 损 失 函 数 \min_{w,b}\frac{1}{2}||w||^2+C\sum_{i=1}^mι_{0/1}(y_i(w^Tx_i+b)-1)\\ 其中,ι_{0/1}是0/1损失函数\\ w,bmin21∣∣w∣∣2+Ci=1∑mι0/1(yi(wTxi+b)−1)其中,ι0/1是0/1损失函数
C > 0是一个常数,用来调节损失的权重,显然当C→+∞时,会迫使所有样本的损失为0,进而退化为严格执行的约束条件,退化为硬间隔,因此,本式子可以看作支持向量机的一般化形式。
由于0/1损失函数非凸、非连续,数学性质不好,使得上式不易求解,因此常用一些数学性质较好的“替代损失函数"来代替0/1损失函数,软间隔支持向量机通常采用的是hinge (合页)损失来代替0/1损失函数。
h i n g e 损 失 : h i n g e ( z ) = m a x ( 0 , 1 − z ) hinge损失:hinge(z)=max(0,1-z) hinge损失:hinge(z)=max(0,1−z)
替换进上式可得:
min w , b 1 2 ∣ ∣ w ∣ ∣ 2 + C ∑ i = 1 m m a x ( 0 , 1 − y i ( w T x i + b ) ) \min_{w,b}\frac{1}{2}||w||^2+C\sum_{i=1}^mmax(0,1-y_i(w^Tx_i+b)) w,bmin21∣∣w∣∣2+Ci=1∑mmax(0,1−yi(wTxi+b))
引入松弛变量ξi,上述优化问题便和下述问题等价:
令 ξ i = m a x ( 0 , 1 − y i ( w T x i + b ) ) min w , b 1 2 ∣ ∣ w ∣ ∣ 2 + C ∑ i = 1 m ξ i s . t . y i ( w T + b ) ≥ 1 − ξ i ξ i ≥ 0 , i = 1 , 2 , . . . , m 令ξ_i=max(0,1-y_i(w^Tx_i+b))\\ \min_{w,b}\frac{1}{2}||w||^2+C\sum_{i=1}^mξ_i \\ s.t. \quad y_i(w^T+b)≥1-ξ_i \\ ξ_i≥0,i=1,2,...,m 令ξi=max(0,1−yi(wTxi+b))w,bmin21∣∣w∣∣2+Ci=1∑mξis.t.yi(wT+b)≥1−ξiξi≥0,i=1,2,...,m
6.5支持向量回归
p9.1 支持向量回归
相比于线性回归用一条线来拟合训练样本,支持向量回归(SVR) 而是采用一一个以f(x)= w^Tx + b为中心,宽度为2e的间隔带, 来拟合训练样本。落在带子上的样本不计算损失(类比线性回归在线上的点预测误差为0),不在带子上的则以偏离带子的距离作为损失(类比线性回归的均方误差), 然后以最小化损失的方式迫使间隔带从样本最密集的地方(中心地带)穿过,进而达到拟合训练样本的目的。
因此SVR的优化问题可以写为:
min w , b 1 2 ∣ ∣ w ∣ ∣ 2 + C ∑ i = 1 m l ε ( f ( x i ) − y i ) \min_{w,b}\frac{1}{2}||w||^2+C\sum_{i=1}^ml_ε(f(x_i)-y_i) w,bmin21∣∣w∣∣2+Ci=1∑mlε(f(xi)−yi)
其中lε(z)为“ε不敏感损失函数”(类比均方误差损失)
l ε ( z ) = 0 , i f ∣ z ∣ ≤ ε ; ∣ z ∣ − ε , i f ∣ z ∣ > ε 1 2 ∣ ∣ w ∣ ∣ 2 为 L 2 正 则 项 , 此 处 引 入 正 则 项 除 了 起 正 则 化 本 身 的 作 用 外 , 也 是 为 了 和 ( 软 间 隔 ) 支 持 向 量 机 的 优 化 目 标 保 持 形 式 上 的 一 致 ( 在 这 里 不 用 均 方 误 差 也 是 此 目 的 ) , 这 样 就 可 以 导 出 对 偶 问 题 引 入 核 函 数 , C 为 调 节 损 失 权 重 的 常 数 。 l_ε(z)=0,\quad if |z|≤ε;\quad |z|-ε,\quad if|z|>ε\\ \frac{1}{2}||w||^2为L2正则项,此处引入正则项除了起正则化本身的作用外,也是为了和(软间隔)支持向量机的优化目标保持形式上的一致\\(在这里不用均方误差也是此目的), 这样就可以导出对偶问题引入核函数,C为调节损失权重的常数。 lε(z)=0,if∣z∣≤ε;∣z∣−ε,if∣z∣>ε21∣∣w∣∣2为L2正则项,此处引入正则项除了起正则化本身的作用外,也是为了和(软间隔)支持向量机的优化目标保持形式上的一致(在这里不用均方误差也是此目的),这样就可以导出对偶问题引入核函数,C为调节损失权重的常数。
SVR的优化问题可以改写为:
min w , b , ξ i 1 2 ∣ ∣ w ∣ ∣ 2 + C ∑ i = 1 m ξ i s . t . − ε − ξ i ≤ f ( x i ) − y i ≤ ε + ξ i ξ i ≥ 0 , i = 1 , 2 , . . . , m \min_{w,b,ξ_i}\frac{1}{2}||w||^2+C\sum_{i=1}^mξ_i \\ s.t. \quad -ε-ξ_i≤f(x_i)-y_i≤ε+ξ_i \\ ξ_i≥0,i=1,2,...,m w,b,ξimin21∣∣w∣∣2+Ci=1∑mξis.t.−ε−ξi≤f(xi)−yi≤ε+ξiξi≥0,i=1,2,...,m
如果考虑两边采用不同的松弛程度:
min w , b , ξ i , ξ i ^ 1 2 ∣ ∣ w ∣ ∣ 2 + C ∑ i = 1 m ( ξ i + ξ i ^ ) s . t . − ε − ξ ^ i ≤ f ( x i ) − y i ≤ ε + ξ ^ i ξ i ≥ 0 , ξ ^ i ≥ 0 , i = 1 , 2 , . . . , m \min_{w,b,ξ_i,\hat{ξ_i}}\frac{1}{2}||w||^2+C\sum_{i=1}^m(ξ_i+\hat{ξ_i}) \\ s.t. \quad -ε-\hatξ_i≤f(x_i)-y_i≤ε+\hatξ_i \\ ξ_i≥0,\hatξ_i≥0,i=1,2,...,m w,b,ξi,ξi^min21∣∣w∣∣2+Ci=1∑m(ξi+ξi^)s.t.−ε−ξ^i≤f(xi)−yi≤ε+ξ^iξi≥0,ξ^i≥0,i=1,2,...,m
如果考虑两边采用不同的松弛程度:
min w , b , ξ i , ξ i ^ 1 2 ∣ ∣ w ∣ ∣ 2 + C ∑ i = 1 m ( ξ i + ξ i ^ ) s . t . − ε − ξ ^ i ≤ f ( x i ) − y i ≤ ε + ξ ^ i ξ i ≥ 0 , ξ ^ i ≥ 0 , i = 1 , 2 , . . . , m \min_{w,b,ξ_i,\hat{ξ_i}}\frac{1}{2}||w||^2+C\sum_{i=1}^m(ξ_i+\hat{ξ_i}) \\ s.t. \quad -ε-\hatξ_i≤f(x_i)-y_i≤ε+\hatξ_i \\ ξ_i≥0,\hatξ_i≥0,i=1,2,...,m w,b,ξi,ξi^min21∣∣w∣∣2+Ci=1∑m(ξi+ξi^)s.t.−ε−ξ^i≤f(xi)−yi≤ε+ξ^iξi≥0,ξ^i≥0,i=1,2,...,m