【论文笔记】【CVPR2020】 (MoCo) Momentum Contrast for Unsupervised Visual Representation Learning
Kaiming He, Haoqi Fan, Yuxin Wu, Saining Xie, Ross Girshick
CVPR2020 Best Paper
Code: https://github.com/facebookresearch/moco
0 Contrast Learning
0.1 Pretext Task
正样本之间拉近,负样本推远
对比学习的优势在于非常灵活,只要能用合适的方法找到正样本和负样本就可以
Instance Discrimination
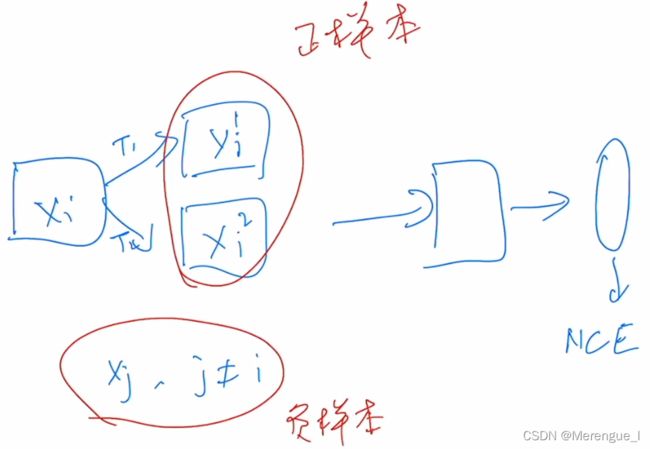
一张图像 X i X_i Xi经过两种不同变换得到的图像( X i 1 {X_i}^1 Xi1称为anchor和 X i 2 {X_i}^2 Xi2称为positive),其他图像 X j X_j Xj( i ≠ j i {\neq} j i=j)是负样本(negetive)
1 Intro
把对比学习看成dictionary look-up,动态字典包含一个队列(queue)和一个 moving-averaged encoder。
在结果方面,ImageNet 分类任务(under linear protocol)可以与之前无监督学习方法差不多或更好。
更重要的是,学到的表征可以很好地迁移到下游任务,在7个分割/检测任务达到sota,比之前使用的有监督预训练的效果还好
挖坑了MAE,自挖自填
dictionary look-up
把anchor的特征比作query( q q q),positive和negetive的特征当做key( k 0 , k 1 , . . . k_0, k_1, ... k0,k1,...),让 q q q与 k 0 k_0 k0尽可能接近
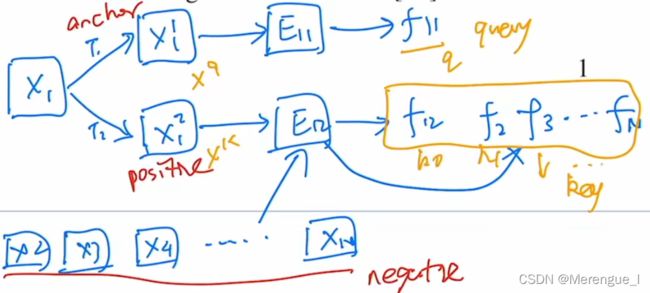
MoCo框架
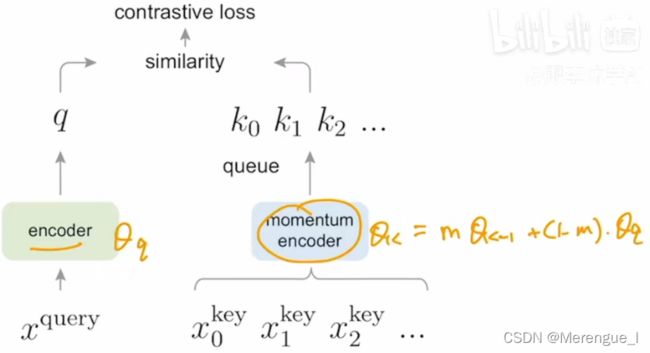
使用queue和momentum的 好处
主要还是受限于GPU显存,当前minibatch入队,最老的minibatch出队,动态维护整个dictionary,这样dictionary的长度就不会受限于batchsize。为了保持key encoder输出一致性,所以又引入了动量(Momentum)去更新 encoder
2 Method
2.1 Contrastive Learning as Dictionary Look-up
对比学习可以被看成是训练一个encoder用于dictionary look-up任务。
考虑有一个encoded query q q q和一组encoded sample { k 0 , k 1 , k 2 , . . . } \{k_0, k_1, k_2, ...\} {k0,k1,k2,...},假定只有一个key( k + k_+ k+)与 q q q配对。那么loss函数应该当 q q q与 k + k_+ k+配对时小,于其他keys配对时小。
InfoNCE
NCE(Noise Contrastive Estimation)将多分类转化为二分类问题,解决了softmax的计算困难问题
但是如果只做二分类又好像不那么友好,所以提出了InfoNCE
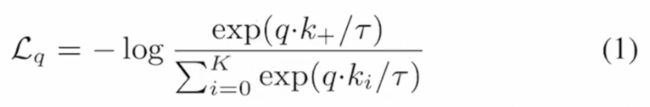
τ τ τ是个temerature超参数,可以改变数据的分布, K K K表示负样本的数量,分母其实是在1个正样本和 K K K个负样本上(dictionary中所有的key)做的。
其实InfoNCE就是一个( K K K+1)分类任务,目的就是把 q q q分类成 k + k_+ k+。
2.2 Momentum Contrast (MoCo)
在对比学习中,dictionary是动态的,key encoder也是在训练过程中变化的。
学习到好的表征的前提是:
(1)、dictionary足够大,包含足够的负样本信息;
(2)、key encoder尽可能保持一致
基于以上动机,提出了MoCo:
2.2.1 Dictionary as a queue
用于扩大dictionary大小
把一个queue(拥有FIFO的特性)当做dictionary,当新的batch入队,最老的batch出队,这样就把batch size和dictionary size解耦,dictionary size可以远大于batch size,可以反复利用在队列中的那些key。
2.2.2 Momentum update
因为字典很大,所以无法通过反向传播来更新key encoder(因为梯度应该计算queue中所有key)。
一种简单的方法是每次把query encoder的权重直接复制到key encoder,但这样效果不好,原因是key encoder变化太快,key特征一致性不好保持。所以提出了Momentum update:
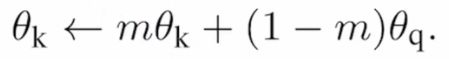
只有 θ q θ_q θq是通过反向传播更新, θ k θ_k θk通过动量(动量取值相对较大,default m = 0.999 m=0.999 m=0.999)更新,这样key encoder的更新就变得很小,保持了key之间的一致性
2.2.3 Relations to previous mechanisms
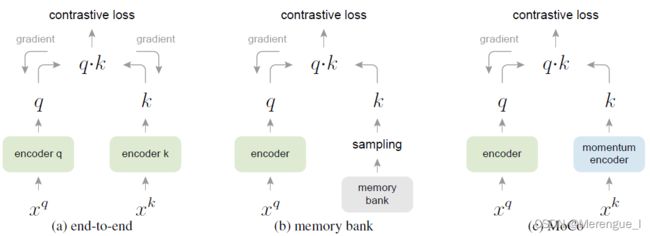
之前的对比学习方法,要么受限于dictionary大小,要么受限于特征一致性
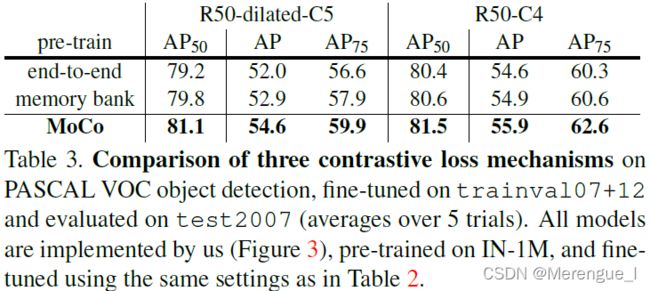
end-to-end
这种方式解决了特征一致性,但没有解决dictionary大小,dictionary size = batch size
memory bank
这种方法解决了dictionary大小问题,但是在特征一致性上做的不好
MoCo
用queue解决了dictionary大小问题,momentum解决了特征一致性问题。其实更像memory bank方法
2.3 PseidoCode( ⭐)

很巧妙地使用全0的lebel去计算CE loss,因为正样本都在0-th的位置上
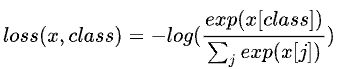
返回的logits是一个(N,K+1)的矩阵,每一行对应一个样本,每一行的第0列是q与正样本的计算值,第1到第k列是q与负样本的值,那么对于这个损失函数来说,对每一个样本x[class]就是x[0],因为我们传入的label是一个n*1的全为0的向量。上面就是q与k的乘积求exp,下面是q与负样本的乘积求exp再求和,最后求负对数就是我们的损失函数。
3 Experiment
3.1 Linear Classification Protocol
在ImageNet上预训练后,freeze住权重只作为feature extractor,然后只训练一个全连接层作为分类头。
根据Grid search,最佳的学习率为30,这很不常见,说明无监督和有监督方法学到的特征分布很不一样。
Ablation 1: contrastive loss mechanisms.
证明动态dictionary的方式有效

Ablation 2: momentun

证明momentun有效,说明一个稳定的key encoder是必要的
Comparison under the linear classification protocol on ImageNet.

3.2 Transferring Features
无监督学习的主要目标是学习可以迁移的特征
Normalization
使用BN对整个网络进行finetune,这样就可以使用有监督学习用的那些超参数(e.g. 学习率)
3.2.1 Downstream task
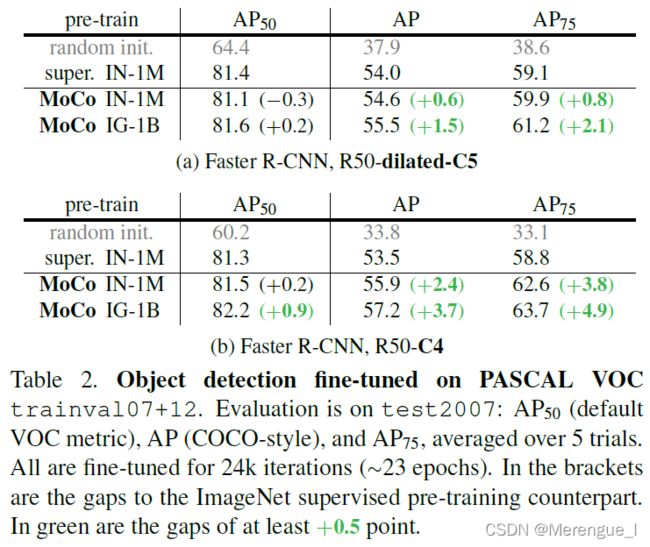


在这里插入图片描述
3.2.2 Summary
在大多数下游任务上,MoCo都超过了有监督训练,除了在某些语义分割、实例分割上。
填上了有监督和无监督预训练之间的gap。
而且,无监督学习可以在更大的数据集上进行训练以达到更好的效果,达到了无监督预训练的初衷
Reference
ZhuYi大佬讲解
Pytorch文档
源代码