客户体验:结合NLP分析客户评论情绪,生成净推荐值(NPS)
Guofu 第 65⭐️ 篇原创干货分享

写在前面
随着数字化转型的浪潮席卷,客户体验的接触点变得愈发离散。
传统的净推荐值(NPS)采取问卷调查为载体进行,填答率通常在 5-8% 左右,即便是在抽样之前进行了配比控制,小样本的调研还是会造成抽样偏差。
对净推荐值(NPS)不了解的朋友,可以先阅读:
净推荐值(NPS)完整行动指南
如何在 Excel 中计算 NPS
NPS如何在企业进行应用实践
NPS 3.0:净推荐值的补充性财务指标 - "赢得性增长率(EGR)"
我在想,是不是可以通过把散落在各处的客户反馈进行整合,以评论数据去理解和分析客户体验,而不必局限于询问客户:你有多大可能性将 [品牌/产品/服务] 推荐给朋友或同事?
在最近企业咨询的项目中,我对净推荐值(NPS)的使用进行了新的尝试。
以客户评论数据切入,通过 NLP 分析客户的情绪倾向,量化计算生成净推荐值(NPS),以此划分推荐者和贬损者。
这种方法解决问卷调查在“数据样本获取成本、样本覆盖率、分析标准一致性,以及缺乏定性信息解释原因”等问题,可以更有效率获取到客户体验的态度数据,并从中找到发力点。
这或许是净推荐值(NPS)使用的新趋势,一起来了解一下。
1、为什么选择评论数据?
相比于问卷调查,客户其实更加倾向于对所消费的产品或服务进行评论。在线客户评论作为线下口碑的网络延展形式,具有信源可信度高、获取成本低且不受时间和空间限制等特点,这些评论也在客户决策参考信息中发挥着巨大的作用。
研究发现,客户的在线评论会影响客户的决策以及企业的销售量,这会给企业带来间接的价值(赵萌&齐佳音,2014)。像去逛线上购物会先去看评论、买家秀,去线下吃饭会先去看大众点评,去看电影先去看豆瓣评分等,潜在客户会受到这些评论的影响,做出消费行为。
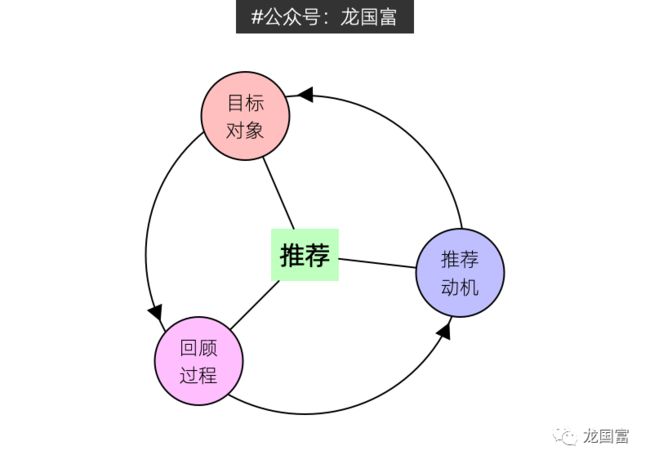
相比之下,虽然客户并未直接回答净推荐值(NPS)的问题,但是在进行评价的过程中,同时满足了「回顾过程+目标对象+推荐动机」的推荐行为三要素。(“三要素”概念解读请阅读:问卷设计:NPS/CSAT要先问还是后问?)
1) 回顾过程:客户评论是历经了一个完整的回顾,即思考这个产品或服务哪里好(坏)。
2) 目标对象:由于大家消费大多会去浏览评论,那么客户在评价的过程,其实是有目标对象的,就是那些未来准备购买的人。
3) 推荐动机:从这一层关系上推论,客户在描绘对产品或服务态度的同时,在当下社会的消费语境中,自我增强(利己/声誉/经济激励)、维权、负面情绪发泄等动机会助推客户评论,让间接推荐的行为得以顺利发生。
此外,在 Dellarocas,C. & Narayan(2005)的研究中发现,客户对产品的满意度和口碑传播呈 U 形关系,即客户会对产品或服务「非常满意」或「非常不满意」会积极给与反馈评论,这与净推荐值(NPS)在理念上也是一致的。
因此我认为,反馈评论数据可以用作询问净推荐值(NPS)问题的替代品。
2、评论的情绪分析
我们知道人类自然语言中的情感色彩非常丰富,一般会包括情绪(悲伤/快乐)、心情(自在/郁闷)、喜好(喜欢/讨厌)、个性(张扬/腼腆)、立场(刚正/摇摆)等等。
情绪分析也称为“意见挖掘”,主要通过技术手段去自动分析客户评论中隐含的情绪倾向,并通过数值化方式表达。目的是帮助企业了解客户对产品/服务的感受,为产品/服务改进提供依据,更好地进行商业决策。

情绪分析的目标就是从客户评论的非结构化的文本抽取出「实体、属性、观点、观点持有者、时间」这五个要素,并且对它们的关系进行分析,最终得出评论内容表达的情绪倾向性。其中实体和属性合并称为评价对象(target),而观点持有者与时间这两个要素可依分析需要加入。
而评论要实践净推荐值(NPS)理念的话,需要用到的是情绪分析中的极性分类(Polarity Classification)能力。即在客户评论的内容中,通过情绪极性分析归类为正面、负面和中性。

正面:表示正面积极的情绪,如高兴,幸福,惊喜,期待等。
中性:表示客观的陈述事实,不涉及个人情绪色彩的表态,或者是不相关、包含愿望的信息。
负面:表示负面消极的情绪,如难过,伤心,愤怒,惊恐等。
以某手表商家评论为例:
客户 A:手表外观看着就大气,功能很多,一直都相信 XX 品牌,而且还是防水的,充电速度也快,喜欢。
客户 B:这是我买来给给家里弟弟使用,还没开始用。
客户 C:信用很差,说好的送太空人表盘,需要自己先买,然后再把钱退回来,说好 3 天退,到第 6 天都还没退,要一直催。
通过情绪分析的极性分类:
客户 A 的评论为: 正面情绪
客户 B 的评论为: 中性情绪
客户 C 的评论为: 负面情绪
人工的判断可以判别情绪极性,但是计算净推荐值(NPS)是需要具体的数值进行计算的,可以怎么做,接着往下看。
3、如何从情绪分析中计算NPS?
得益于自然语言处理 (NLP, Natural Language Processing) 技术的发展,从之前 AI2 的 ELMo,到 OpenAI 的 fine-tune transformer,再到 Google 发布的 BERT 模型。NLP 库的进步使得从评论内容中提取信息更容易、更准确。

我尝试利用 NLP 通过 4 个步骤,分析客户评论的正负面评论比例以及情绪值,结合 NPS 的方法,从而识别推动者和反对者。
具体操作步骤如下。
步骤 1:采集已购买客户的评论数据,依据客户 ID 进行评论汇总。
| 客户ID | 评论 |
| 客户 A | 距离川沙公路较近,但是公交指示不对,如果是"蔡陆线"的话,会非常麻烦。建议用别的路线,房间较为简单。 |
| 客户 B | 商务大床房,房间很大,床有2M宽,整体感觉经济实惠不错! |
| ··· | ··· |
| 客户 Z | CBD中心,周围没什么店铺,说5星有点勉强.不知道为什么卫生间没有电吹风。 |
原则上是可以把所有的客户评论都进行分析。由于我们更加希望关注购买频繁客户的声音,在实际的应用上,可以设定适用于分析的基准值。比如,一年内最低消费次数为 3 次,作为分析目标对象。
通过数据汇总,你大概可以得到下面的表格。
| 客户ID | 评论数 |
| 客户 A | 100 |
| 客户 B | 40 |
| ··· | ··· |
| 客户 Z | 55 |
通过这个表格,可以筛选出需要进行分析的客户范围。或者,还可以依据客户评论数量设定不同客户群,分别进行。
步骤 2:把评论进行 NLP 情绪分析,依据客户 ID 汇总正面/负面评论数。
接下来,需要使用到 NLP ,来帮助我们完成极性分类的评分环节。对于想要体验 NLP 情绪分析的小伙伴,可以使用中国传媒大学的“语言智能开放平台”体验一下。(http://ling.cuc.edu.cn/cucNLPTools/cucnlp/cuc_ui/index.html#/pc_emotion)
我是使用谷歌的 AutoML Natural Language 创建分析模型,搭建完成后把你需要分析的评论文本信息导入,模型就可以根据文本内容,给出相应的极性分类。
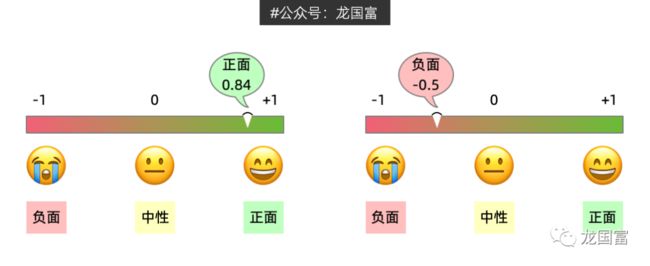
情绪值的区间为 [-1,1],越靠近 +1,情绪越正面;越靠近 -1,情绪越负面;0 则为中性情绪。比如,TT 同学的评论为正面情绪(0.84),DD 同学的评论为负面情绪(-0.5)。
下面是评论内容情绪分析-极性分类的示例。
| 客户ID | 评论 | 极性分类 |
情绪值 |
| 客户 A | 距离川沙公路较近,但是公交指示不对,如果是"蔡陆线"的话,会非常麻烦。建议用别的路线,房间较为简单。 | 负面 |
-0.054 |
| 客户 B | 商务大床房,房间很大,床有2M宽,整体感觉经济实惠不错! | 正面 | 0.4 |
| ··· | ··· | ··· | ··· |
| 客户 Z | CBD中心,周围没什么店铺,说5星有点勉强。不知道为什么卫生间没有电吹风。 | 负面 | -0.38 |
经过 NLP 情绪分析-极性分类之后,再依据客户 ID 进行正面评论数和负面评论数汇总。
| 客户ID | 评论数 | 正面评论数 | 负面评论数 |
| 客户 A | 100 | 50 | 50 |
| 客户 B | 40 | 20 | 20 |
| ··· | ··· | ··· | ··· |
| 客户 Z | 55 | 50 | 5 |
步骤 3:计算正面/负面评论的平均分,计算评论得分。
为了识别客户属于「推荐者、中立者、贬损者」的类型,把该客户的评论情绪值依据「正面」和「负面」区分,分别计算平均数。
得到平均数后,参照净推荐值(NPS)的理念,找出该客户在整个购买历程当中,正面和负面的差值占比,以此得到该客户对于品牌的整体情绪倾向。
计算公式如下:
评论得分 = ((正面评论数 x 正面评论分) + (负面评论数 x 负面评论分) )/评论总数
注意:由于负面评论的情绪值为「负数」,所以这里使用的是加号。概念上,是正面情绪总得分减去负面情绪总得分。
| 客户ID | 正面评论数 | 平均分 | 负面评论数 | 平均分 | 总评论数 | 平均得分 |
| A | 41 | 0.9 | 1 | -0.92 | 42 | 0.86 |
| B | 15 | 0.97 | 2 | -0.92 | 17 | 0.75 |
| C |
2 | 0.98 | 24 | -0.97 | 26 | -0.82 |
| D | 33 | 0.85 | 1 | -0.88 | 34 | 0.8 |
| D |
46 |
0.91 |
22 |
-0.98 |
68 |
0.3 |
| D | 44 | 0.99 | 2 | -0.75 | 46 | 0.91 |
| D | 77 | 0.82 | 3 | -0.81 | 80 | 0.76 |
| D | 59 | 0.78 | 3 | -0.93 | 62 | 0.7 |
| D | 1 | 1 | 11 | -0.82 | 12 | -0.67 |
| D | 6 | 0.9 | 8 | -0.86 | 64 | 0.68 |
| D | 63 | 0.76 | 5 | -0.65 | 68 | 0.66 |
| D | 17 | 0.97 | 2 | -0.66 | 19 | 0.64 |
比如,客户 A,总评论数为 42,其中正面评论数为 41,正面评论平均得分为 0.9。负面评论数为 1,负面评论平均得分为 -0.92。
客户 A 评论得分 = ((41 x 0.9) + (1 x (-0.9))) / 42
经由计算可以知道,客户 A 的整体评论情绪值为:0.86。
步骤 4:转化为 NPS 分数,划分客户类型,计算 NPS 得分。
为了消除评论得分之间的量纲影响,需要进行数据标准化处理,以解决数据指标之间的可比性。这里 NPS 的计算通过把各评论得分转化为 [0-10] 的量级,进行客户类型的划分。
计算公式如下:
客户NPS = (评论得分 + 1) x 5
品牌NPS = 推荐者% - 贬损者%
计算示例:
| 客户 ID |
正面评论数 | 平均分 | 负面评论数 | 平均分 | 总评论数 | 平均得分 | NPS | 客户类型 |
| A | 41 | 0.9 | 1 | -0.92 | 42 | 0.86 | 9.28 | 推荐者 |
| B | 15 | 0.97 | 2 | -0.92 | 17 | 0.75 | 8.74 | 推荐者 |
| C |
2 | 0.98 | 24 | -0.97 | 26 | -0.82 | 0.9 | 贬损者 |
| D | 33 | 0.85 | 1 | -0.88 | 34 | 0.8 | 9 | 推荐者 |
| E |
46 |
0.91 |
22 |
-0.98 |
68 |
0.3 |
6.49 |
中立者 |
| F | 44 | 0.99 | 2 | -0.75 | 46 | 0.91 | 9.57 | 推荐者 |
| G | 77 | 0.82 | 3 | -0.81 | 80 | 0.76 | 8.79 | 推荐者 |
| H | 59 | 0.78 | 3 | -0.93 | 62 | 0.7 | 8.49 | 推荐者 |
| I | 1 | 1 | 11 | -0.82 | 12 | -0.67 | 1.66 | 贬损者 |
| J | 6 | 0.9 | 8 | -0.86 | 64 | 0.68 | 8.4 | 推荐者 |
| K | 63 | 0.76 | 5 | -0.65 | 68 | 0.66 | 8.28 | 推荐者 |
| L | 17 | 0.97 | 2 | -0.66 | 19 | 0.64 | 8.19 | 推荐者 |
可公众号后台回复【计算器】获取此 Excel 计算表
注意:在净推荐值(NPS)的评分方式上是不存在小数的分数值,这里会将 X≤6 划分为贬损者, 8≥X>6 划分为中立者, X>8 划分为推荐者。
比如,客户 A 的评论得分是 0.86 分,那么她的 NPS 得分就是 (0.86 + 1) x 5 = 9.28,属于推荐者。
根据计算,可以知道有 9 位推荐者,2 位贬损者,那么品牌的 NPS 得分为:= (9 - 2) / 12 x 100 = 58.3。
4、如何从结果中下钻分析,找到需改进痛点?
我们知道 NPS 的得分并不能为企业带来价值,得分背后原因的挖掘才是真正意义所在。同样,依此方法同样可以达成。
以某酒店的客户评论为例,通常酒店在消费者视角,会关心「服务、价格、设施、位置、餐饮、卫生」六大维度。
从上面分析所划分的推荐者和贬损者,依据这六大维度以及继续下钻。通过划定的维度,借由 NLP 技术,分别对于不同维度进行极性分类,获得情绪值。
| 评论 | 服务 | 价格 | 设施 | 位置 | 餐饮 | 卫生 |
| CBD中心,周围没什么店铺,说5星有点勉强。不知道为什么卫生间没有电吹风。 | 中立 |
负面 -0.3 |
负面 -0.6 |
正面 +0.8 |
中立 |
中立 |
另外,可以通过词云的方式,找到对于推荐者、贬损者客户群来说,都是哪些接触点在发挥作用。
以此,寻找对于不同客户类型来说,分别可以优化改善的发力点是哪些,并从中找到产品或服务改善的优先次序,帮助你快速掌握客户的脉搏并采取行动。
总的来说,不同维度转化为数值之后,后续的分析等同于常规的 NPS 分析步骤。
写在最后
这是一种新的净推荐值(NPS)实践思路,结合 NPS 的核心理念和 NLP 技术,可以确定品牌的推荐者者、贬损者者和中立者,亦可以下钻通过多维度拆解评论(定性数据)找到背后具体的原因。
在数据样本获取成本、样本覆盖率、分析标准一致性,以及缺乏定性信息解释原因等问题上,该思路基本可以解决上述挑战。
客户体验伴随着业务的进行,同步进行监测,可持续性观测客户对于品牌长期以来的态度变化趋势。
当然,目前这个模型度量概念还处于需要不断探讨验证的阶段,像不同领域语料库的完整程度,会直接影响 NLP 的输出结果,从而影响整体的数据表现。
以上,是我最近关于净推荐值(NPS)的实践总结,希望对你有所启发。
欢迎有不同想法的朋友交流学习。
来一起唠唠客户体验 ♂️
点击这里,可以加我微信,进入客户体验交流群~

本文完.
⭕️⭕️ 如何领取读者专属资源?
先将“龙国富”公众号设为⭐️星标,然后在后台回复以下关键词,即可领取。
NPS NPS(净推荐值)资料包
RFM RFM(客户分群)资料包
KANO KANO(需求优先级)分析资料包
计算器 Excel计算体验指标模板
体验地图 200+真实用户体验旅程地图案例
服务蓝图 服务蓝图模板(OmniGraffle)
IPA IPA(用户需求与期待)分析资料包
统计 统计分析工具安装包
喜欢就点个“赞”和“在看”呗