无人驾驶虚拟仿真(十三)--图像处理之交通标志牌识别1
简介:在实际交通地图环境中,我们预设了交通标志牌,可以通过交通标志牌对小车进行更加细致丰富的控制,标志牌形式如下:


每个交通标志牌都是由功能图片+编码图片结合的方式生成(虚拟仿真环境下功能图片和编码图片位置相反,不影响识别),每一个标志牌代表一种对车辆行为的指示,比如:
停止:车辆需要在指示牌范围内停止形式
人行横道:车辆需观察行人
前方慢形:车辆需要减速
避让:车辆需要避让一段道路
路口标识:按照设定是否转弯或者直行
......
用户可以按照实际需求,自行拟定交通标志牌,此类编码图片有500多种,用户可以指定编码图片与车辆行为来进行匹配,当检测到标志牌时,对车辆进行相应的功能指示。
在虚拟仿真环境中,我们也可以加入交通标志牌,从而实现与车辆的交互,在这一节中,我们将学习如何识别交通标志牌,以及通过上图交通标志牌对车辆进行控制。
目录
1、制作地图
2、截取含交通标志牌的图片
3、安装dt-apriltags库
4、摄像头标定
4.1 截取棋盘格图片
4.2 初始化参数及图片导入
4.3 寻找角点
4.4 计算相机矩阵
4.5 查看相机矩阵
5、识别标志牌
1、制作地图
首先,我们需要制作含有交通标志牌的虚拟仿真地图(test.yaml,保存路径参考第一章):
tiles:
- [floor , floor , floor , floor , floor , floor , floor , floor ]
- [floor , curve_left/W, straight/W, 3way_left/W, straight/W , straight/W , curve_left/N , floor ]
- [floor , straight/S , floor , straight/N , floor , floor , straight/N , floor ]
- [floor , 3way_left/S , straight/W, 4way , straight/E , straight/E , 3way_left/N , floor ]
- [floor , straight/S , floor , straight/S , floor , floor , straight/N , floor ]
- [floor , straight/S , floor , straight/S , floor , curve_right/N , curve_left/E , floor ]
- [floor , curve_left/S, straight/E, 3way_left/E, straight/E , curve_left/E , floor , floor ]
- [floor , floor , floor , floor , floor , floor , floor , floor ]
objects:
trafficlight1:
kind: trafficlight
place:
tile: [3,4]
relative:
~SE2Transform:
p: [-0.18,-0.18]
theta_deg: 135
height: 0.3
optional: true
trafficlight2:
kind: trafficlight
place:
tile: [6,4]
relative:
~SE2Transform:
p: [-0.18,-0.18]
theta_deg: 135
height: 0.3
optional: true
trafficlight3:
kind: trafficlight
place:
tile: [1,4]
relative:
~SE2Transform:
p: [-0.18,-0.18]
theta_deg: 135
height: 0.3
optional: true
trafficlight4:
kind: trafficlight
place:
tile: [3,6]
relative:
~SE2Transform:
p: [-0.18,-0.18]
theta_deg: 135
height: 0.3
optional: true
trafficlight5:
kind: trafficlight
place:
tile: [3,1]
relative:
~SE2Transform:
p: [-0.18,-0.18]
theta_deg: 135
height: 0.3
optional: true
sign1:
kind: sign_stop
pos: [5, -0.05]
rotate: 0
height: 0.18
sign2:
kind: sign_left_T_intersect
pos: [3, -0.05]
rotate: 0
height: 0.18
sign3:
kind: sign_yield
pos: [0.95, 3.4]
rotate: -90
height: 0.18
sign4:
kind: sign_duck_crossing
pos: [2.5, 5.95]
rotate: 180
height: 0.18
sign5:
kind: sign_T_intersect
pos: [0.95, 2]
rotate: 0
height: 0.18
tile_size: 0.585地图中包含了T型路口,避让、慢行、停止标志牌。
2、截取含交通标志牌的图片
$ cd gym-duckietown
$ python3 manual_control.py --env-name Duckietown --map-name test通过方向键控制车辆,移动到标志牌附近,按enter键截图

3、安装dt-apriltags库
$ pip3 install dt-apriltags
4、摄像头标定
当我们在一张图片中识别到编码图片(类似二维码)可以计算出编码图片的相对于整体图片的大小(像素)、位置(像素)、旋转情况,另外编码图片实际大小是已知的,要计算摄像头与编码图片的距离还需要一些摄像头本身的参数,包括焦距、光学中心等,所以我们需要先计算摄像头的参数,摄像头参数相关名词有以下几种:
1)相机矩阵:包括焦距(fx,fy),光学中心(Cx,Cy),完全取决于相机本身,是相机的固有属性,只需要计算一次,可用矩阵表示如下:[fx, 0, Cx; 0, fy, cy; 0,0,1];
2)畸变系数:畸变数学模型的5个参数 D = (k1,k2, P1, P2, k3);
3)相机内参:相机矩阵和畸变系数统称为相机内参,在不考虑畸变的时候,相机矩阵也会被称为相机内参;
4)相机外参:通过旋转和平移变换将3D的坐标转换为相机2维的坐标,其中的旋转矩阵和平移矩阵就被称为相机的外参;描述的是将世界坐标系转换成相机坐标系的过程。
摄像头的标定过程实际上就是在4个坐标系转化的过程中求出相机的内参和外参的过程。这4个坐标系分别是:世界坐标系(描述物体真实位置),相机坐标系(摄像头镜头中心),图像坐标系(图像传感器成像中心,图片中心,影布中心,单位mm),像素坐标系(图像左上角为原点,描述像素的位置,单位是多少行,多少列)。
(1)世界坐标系 -->相机坐标系:求解摄像头外参(旋转和平移矩阵);
(2)相机坐标系 -->图像坐标系:求解相机内参(摄像头矩阵和畸变系数);
(3)图像坐标系 -->像素坐标系:求解像素转化矩阵(可简单理解为原点从图片中心到左上角,单位厘米变行列)
在虚拟仿真环境中,摄像头不存在畸变,所以我们只需要求解摄像头的相机矩阵,具体流程如下:
4.1 截取棋盘格图片
虚拟仿真环境中有相机标定专用环境,通过手动控制脚本打开,用enter键截图,因为需要截取多张图片,每截取一张都需要修改文件名,否则会覆盖先前截取的。
$ cd gym-duckietown
$ python3 manual_control.py --env-name Duckietown --map-name calibration_map_int
需要截取多张图片(10张以上),需要包含7个角度(可以多截几张):居中、较远、较近、偏左、偏右、偏上、偏下,要求截图中棋盘格角点完整,不能缺行:

注:如果出现地图全黑色没有棋盘格的情况,请查看calibration_map_int.yaml地图文件,如果地图图块配置如下图:

则修改为:

4.2 初始化参数及图片导入
OpenCV使用棋盘格板进行标定,为了标定相机,我们需要输入一系列三维点和它们对应的二维图像点。在黑白相间的棋盘格上,二维图像点很容易通过角点检测找到。而对于真实世界中的三维点,由于我们采集中,是将相机放在一个地方,而将棋盘格定标板进行移动变换不同的位置,然后对其进行拍摄,所以我们需要知道(X,Y,Z)的值。但是简单来说,我们定义棋盘格所在平面为XY平面,即Z=0。对于定标板来说,我们可以知道棋盘格的方块尺寸,例如30mm,这样我们就可以把棋盘格上的角点坐标定义为(0,0,0),(30,0,0),(60,0,0),···,这个结果的单位是mm。
#!/usr/bin/env python3
import cv2
import numpy as np
nx = 5 #棋盘格角点行数
ny = 7 #棋盘格角点列数
#世界坐标系中的三维点
objp = np.zeros((nx*ny,3), np.float32)
objp[:,:2] = np.mgrid[0:nx,0:ny].T.reshape(-1,2)
#依据棋盘上单个黑白矩阵的大小,计算出(初始化)每一个内角点的世界坐标
#我们使用的棋盘格方块尺寸是31mm
objp = objp*31
objpoints = [] #三维点列表
imgpoints = [] #二维点列表
#求角点的迭代过程的终止条件,采用的停止准则是最大循环次数31和最大误差容限0.001
criteria = (cv2.TERM_CRITERIA_EPS + cv2.TERM_CRITERIA_MAX_ITER, 31, 0.001)
#循环读取图片并显示
for i in range(1,8):
imageFile = 'images/13-'+str(i)+'.png'
img = cv2.imread(imageFile)
cv2.imshow(imageFile,img)
cv2.waitKey(0)
cv2.destroyAllWindows()4.3 寻找角点
寻找角点我们需要使用findChessboardCorners函数提取角点,这里的角点专指的是标定板上的内角点,这些角点与标定板的边缘不接触,涉及到以下几个opencv函数:
retval, corners = cv.findChessboardCorners(image, patternSize[, corners[, flags]])第一个参数Image,传入拍摄的棋盘图Mat图像,必须是8位的灰度或者彩色图像;
第二个参数patternSize,每个棋盘图上内角点的行列数,一般情况下,行列数不要相同,便于后续标定程序识别标定板的方向;
第三个参数corners,用于存储检测到的内角点图像坐标位置,一般是数组形式;
第四个参数flage:用于定义棋盘图上内角点查找的不同处理方式,有默认值。
为了提高标定精度,需要在初步提取的角点信息上进一步提取亚像素信息,降低相机标定偏差,常用的方法是cornerSubPix函数:
cv2.cornerSubPix(image, corners, winSize, zeroZone, criteria)第一个参数image,输入图像的像素矩阵,最好是8位灰度图像,检测效率更高;
第二个参数corners,初始的角点坐标向量,同时作为亚像素坐标位置的输出,所以需要是浮点型数据;
第三个参数winSize,大小为搜索窗口的一半;
第四个参数zeroZone,死区的一半尺寸,死区为不对搜索区的中央位置做求和运算的区域。它是用来避免自相关矩阵出现某些可能的奇异性。当值为(-1,-1)时表示没有死区;
第五个参数criteria,定义求角点的迭代过程的终止条件,可以为迭代次数和角点精度两者的组合;
找到角点信息后,我们可以用 drawChessboardCorners函数用绘制被成功标定的角点:
cv2.drawChessboardCorners(image, patternSize, corners, patternWasFound)第一个参数image,8位灰度或者彩色图像;
第二个参数patternSize,每张标定棋盘上内角点的行列数;
第三个参数corners,初始的角点坐标向量,同时作为亚像素坐标位置的输出,所以需要是浮点型数据;
第四个参数patternWasFound,标志位,用来指示定义的棋盘内角点是否被完整的探测到,true表示别完整的探测到,函数会用直线依次连接所有的内角点,作为一个整体,false表示有未被探测到的内角点,这时候函数会以(红色)圆圈标记处检测到的内角点;
def findConner(image):
#转化为灰度图
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
#寻找角点
ret, corners = cv2.findChessboardCorners(gray, (nx, ny), None)
if ret==True:
#寻找亚像素角点
cv2.cornerSubPix(gray,corners,(11,11),(-1,-1),criteria)
#存储三维点和二维点矩阵
objpoints.append(objp)
imgpoints.append(corners)
#绘制寻找到的角点
cv2.drawChessboardCorners(image, (nx, ny), corners, True)
cv2.imshow("corners",image)
4.4 计算相机矩阵
获取到棋盘标定图的内角点图像坐标之后,就可以使用calibrateCamera函数进行标定,计算相机内参和外参系数:
retval, cameraMatrix, distCoeffs, rvecs, tvecs = cv2.calibrateCamera(objectPoints, imagePoints, imageSize, cameraMatrix, distCoeffs[, rvecs[, tvecs[, flags[, criteria]]]])第一个参数objectPoints,为世界坐标系中的三维点。需要依据棋盘上单个黑白矩阵的大小,计算出(初始化)每一个内角点的世界坐标;
第二个参数imagePoints,为每一个内角点对应的图像坐标点;
第三个参数imageSize,为图像的像素尺寸大小,在计算相机的内参和畸变矩阵时需要使用到该参数;
第四个参数cameraMatrix为相机的内参矩阵;
第五个参数distCoeffs为畸变矩阵;
第六个参数rvecs为旋转向量;
第七个参数tvecs为位移向量;
第八个参数flags为标定时所采用的算法。有如下几个参数:
CV_CALIB_USE_INTRINSIC_GUESS:使用该参数时,在cameraMatrix矩阵中应该有fx,fy,u0,v0的估计值。否则的话,将初始化(u0,v0)图像的中心点,使用最小二乘估算出fx,fy。
CV_CALIB_FIX_PRINCIPAL_POINT:在进行优化时会固定光轴点。当CV_CALIB_USE_INTRINSIC_GUESS参数被设置,光轴点将保持在中心或者某个输入的值。
CV_CALIB_FIX_ASPECT_RATIO:固定fx/fy的比值,只将fy作为可变量,进行优化计算。当CV_CALIB_USE_INTRINSIC_GUESS没有被设置,fx和fy将会被忽略。只有fx/fy的比值在计算中会被用到。
CV_CALIB_ZERO_TANGENT_DIST:设定切向畸变参数(p1,p2)为零。
CV_CALIB_FIX_K1,…,CV_CALIB_FIX_K6:对应的径向畸变在优化中保持不变。
CV_CALIB_RATIONAL_MODEL:计算k4,k5,k6三个畸变参数。如果没有设置,则只计算其它5个畸变参数。
第九个参数criteria是最优迭代终止条件设定。
标定的结果是生成相机的内参矩阵cameraMatrix、相机的5个畸变系数distCoeffs(本节只需要内参矩阵),另外每张图像都会生成属于自己的平移向量和旋转向量。
def getMatrix():
ret, mtx, dist, rvecs, tvecs = cv2.calibrateCamera(objpoints, imgpoints, (640,480), None, None)
print("mtx:", mtx)
print("dist:", dist)
return mtx, dist4.5 查看相机矩阵
附以上内容整理后的源码(getCamMatrix.py):
#!/usr/bin/env python3
import cv2
import numpy as np
def findConner(image):
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
ret, corners = cv2.findChessboardCorners(gray, (nx, ny), None)
if ret==True:
cv2.cornerSubPix(gray,corners,(11,11),(-1,-1),criteria)
objpoints.append(objp)
imgpoints.append(corners)
cv2.drawChessboardCorners(image, (nx, ny), corners, True)
cv2.imshow("corners",image)
def getMatrix():
ret, mtx, dist, rvecs, tvecs = cv2.calibrateCamera(objpoints, imgpoints, (640,480), None, None)
print("mtx:", mtx)
print("dist:", dist)
return mtx, dist
nx = 5
ny = 7
objp = np.zeros((nx*ny,3), np.float32)
objp[:,:2] = np.mgrid[0:nx,0:ny].T.reshape(-1,2)
objp = objp*31
objpoints = []
imgpoints = []
criteria = (cv2.TERM_CRITERIA_EPS + cv2.TERM_CRITERIA_MAX_ITER, 31, 0.001)
for i in range(1,8):
imageFile = 'images/13-'+str(i)+'.png'
img = cv2.imread(imageFile)
cv2.imshow(imageFile,img)
findConner(img)
cv2.waitKey(0)
cv2.destroyAllWindows()
mtx, dist = getMatrix()$ python3 getCamMatrix.py
其中的mtx即我们需要的摄像头内参矩阵。
5、识别标志牌
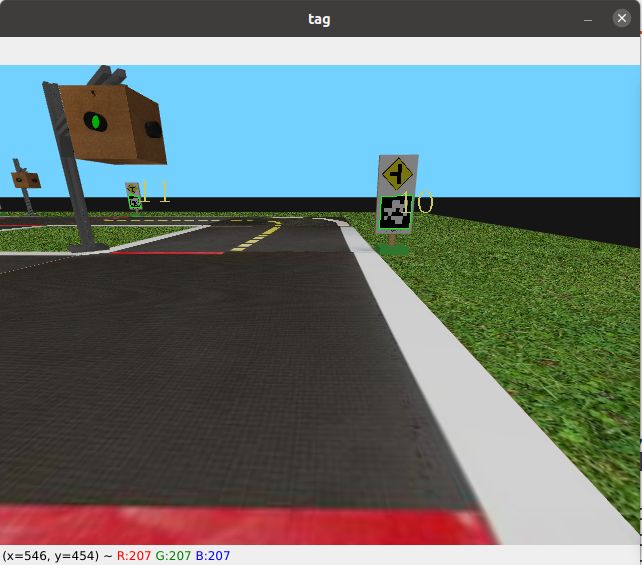
截取两张带标签的图片:

#!/usr/bin/env python3
import cv2
from dt_apriltags import Detector
import numpy as np
#读取图片
image = cv2.imread("images/tag1.png")
#创建识别器
at_detector = Detector(families='tag36h11',
nthreads=1,
quad_decimate=1.0,
quad_sigma=0.0,
refine_edges=1,
decode_sharpening=0.25,
debug=0)
#图像转灰度图
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
#摄像头内参矩阵
matrix = np.array([[397.06923648, 0, 319.53462827], [0, 409.40521919, 246.53066753], [0, 0, 1]])
#识别标志牌
tags = at_detector.detect(gray, True, (matrix[0][0],matrix[1][1],matrix[0][2],matrix[1][2]), 0.06)
#在图中画出标志牌位置
for tag in tags:
cv2.line(image,tag.corners[0].astype(int),tag.corners[1].astype(int),(0,255,0))
cv2.line(image,tag.corners[1].astype(int),tag.corners[2].astype(int),(0,255,0))
cv2.line(image,tag.corners[2].astype(int),tag.corners[3].astype(int),(0,255,0))
cv2.line(image,tag.corners[3].astype(int),tag.corners[0].astype(int),(0,255,0))
cv2.putText(image, str(tag.tag_id), tag.center.astype(int), cv2.FONT_HERSHEY_COMPLEX, 1.0, (100, 200, 200), 1)
print("识别到的标志牌ID:", tag.tag_id, " 标志牌与车的距离:",tag.pose_t[2][0])
cv2.imshow("tag",image)
cv2.waitKey(0)
cv2.destroyAllWindows()