画图分析Dual Attention(CAM、PAM)、non-local、CCNet、Relation-Aware Global Attention关系矩阵的具体含义--附代码)
初衷:在读代码时,只知道要对于non-local,PAM,CAM要 求出相应的关系矩阵,但这个关系矩阵是怎么求的,以及为什么要这样做就有效果,一直是云里雾里,所以本篇根据tensor数据流,将重点tensor的生成过程以及所表示的含义,画了出来,方便理解其物理意义。
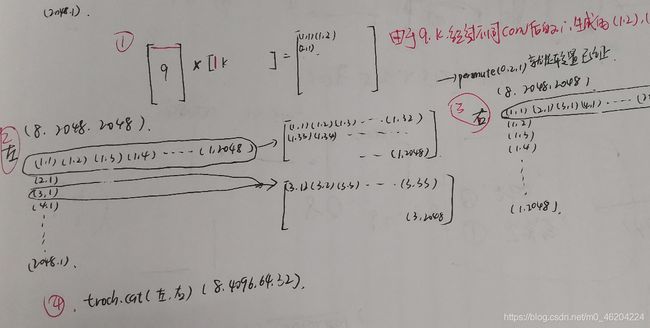
细读一下代码,nolocal和下面的PAM,CAM原理一样,nolocal和PAM获取的是空间元素的关系,CAM获取的是通道间的关系
关系矩阵的具体含义表示:精彩部分看下面PAM,CAM的描述
文章目录
- Non-local
-
- 表达式
- 实验结论
- PAM
- CAM
-
- 代码
- CCNet
- Relation-Aware Global Attention
Non-local
- Local & non-local
Local这个词主要是针对感受野(receptive field)来说的。以卷积操作为例,它的感受野大小就是卷积核大小,而我们一般都选用33,55之类的卷积核,它们只考虑局部区域,因此都是local的运算。同理,池化(Pooling)也是。相反的,non-local指的就是感受野可以很大,而不是一个局部领域。 捕捉长距离特征之间依赖关系,为后边的层带来更为丰富的语义信息。 - why need non-local
卷积层的堆叠可以增大感受野,但是如果看特定层的卷积核在原图上的感受野,它毕竟是有限的。这是local运算不能避免的。然而有些任务,它们可能需要原图上更多的信息,比如attention。如果在某些层能够引入全局的信息,就能很好地解决local操作无法看清全局的情况,为后面的层带去更丰富的信息。 - 神经网络中还有一个常见的操作也是利用的全局信息,那就是Linear层,non-local block利用两个点的相似性对每个位置的特征做加权,而全连接层则是利用position-related(对每一个点的信息都进行了融合)的weight对每个位置做加权。

表达式



说明:
4. 归一化系数C(x)保证对任意尺寸的输入,不会产生数值上的尺度伸缩。
5. Embedding的实现方式,在文章中都采用1*1的卷积操作。
实验结论
a. 计算量偏大:在高阶语义层引入non local layer, 也可以在具体实现的过程中添加pooling层来进一步减少计算量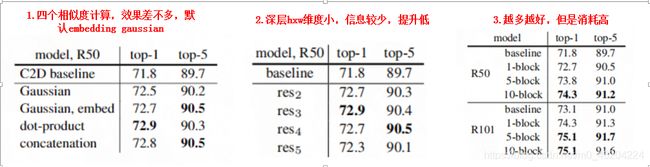
参考A
参考B
代码
8. NONLocalBlock1D(in_channels=1,inter_channels=1, sub_sample=False, bn_layer=True)
#sub_sample由于特征hxw过大,可用pool减少维度
#bn_layer控制是否经过bn
PAM
PAPER
获取空间上的关系(要保证c一样)
获取通道上的关系(要保证hxw一样)
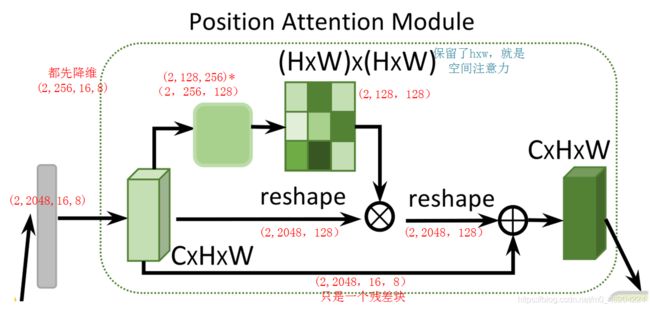
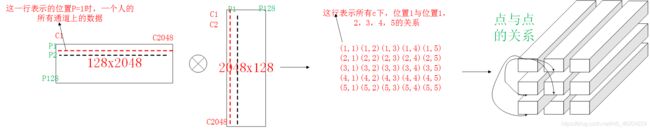

CAM
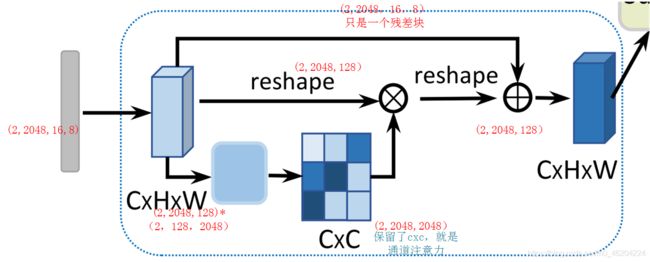
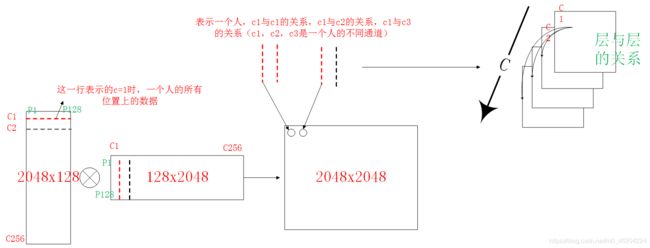

代码
A
import numpy as np
import torch
import math
from torch.nn import Module, Sequential, Conv2d, ReLU,AdaptiveMaxPool2d, AdaptiveAvgPool2d, \
NLLLoss, BCELoss, CrossEntropyLoss, AvgPool2d, MaxPool2d, Parameter, Linear, Sigmoid, Softmax, Dropout, Embedding
from torch.nn import functional as F
from torch.autograd import Variable
torch_ver = torch.__version__[:3]
__all__ = ['PAM_Module', 'CAM_Module']
class PAM_Module(Module):
""" Position attention module"""
#Ref from SAGAN
def __init__(self, in_dim):
super(PAM_Module, self).__init__()
self.chanel_in = in_dim
self.query_conv = Conv2d(in_channels=in_dim, out_channels=in_dim//8, kernel_size=1)
self.key_conv = Conv2d(in_channels=in_dim, out_channels=in_dim//8, kernel_size=1)
self.value_conv = Conv2d(in_channels=in_dim, out_channels=in_dim, kernel_size=1)
self.gamma = Parameter(torch.zeros(1))
self.softmax = Softmax(dim=-1)
def forward(self, x):
"""
inputs :
x : input feature maps( B X C X H X W)
returns :
out : attention value + input feature
attention: B X (HxW) X (HxW)
"""
m_batchsize, C, height, width = x.size()
#(2,2048,16,8)->(2,256,16,8)->(2,256,128)->(2,128,256)
proj_query = self.query_conv(x).view(m_batchsize, -1, width*height).permute(0, 2, 1)
proj_key = self.key_conv(x).view(m_batchsize, -1, width*height)#(2,256,128)
energy = torch.bmm(proj_query, proj_key)#(2,128,128)
attention = self.softmax(energy)#(2,128,128)
proj_value = self.value_conv(x).view(m_batchsize, -1, width*height)#torch.Size([2, 2048, 128])
out = torch.bmm(proj_value, attention.permute(0, 2, 1))#torch.Size([2, 2048, 128])
out = out.view(m_batchsize, C, height, width)
out = self.gamma*out + x
return out
class CAM_Module(Module):
""" Channel attention module"""
def __init__(self, in_dim):
super(CAM_Module, self).__init__()
self.chanel_in = in_dim
self.gamma = Parameter(torch.zeros(1))
self.softmax = Softmax(dim=-1)
def forward(self,x):
"""
inputs :
x : input feature maps( B X C X H X W)
returns :
out : attention value + input feature
attention: B X C X C
"""
m_batchsize, C, height, width = x.size()
proj_query = x.view(m_batchsize, C, -1)#torch.Size([2, 2048, 128])
proj_key = x.view(m_batchsize, C, -1).permute(0, 2, 1)#torch.Size([2, 128, 2048])
energy = torch.bmm(proj_query, proj_key)#(2,2048,2048)
energy_new = torch.max(energy, -1, keepdim=True)[0].expand_as(energy)-energy
attention = self.softmax(energy_new)#torch.Size([2, 2048, 2048])
proj_value = x.view(m_batchsize, C, -1)#(2,2048,128)
out = torch.bmm(attention, proj_value)#torch.Size([2, 2048, 128])
out = out.view(m_batchsize, C, height, width)
out = self.gamma*out + x
return out
if __name__ == '__main__':
x=torch.Tensor(2,2048,16,8)
# model = PAM_Module(2048)
# print(model(x).shape)
model1=CAM_Module(2048)
model1(x)
# print(model1(x).shape)
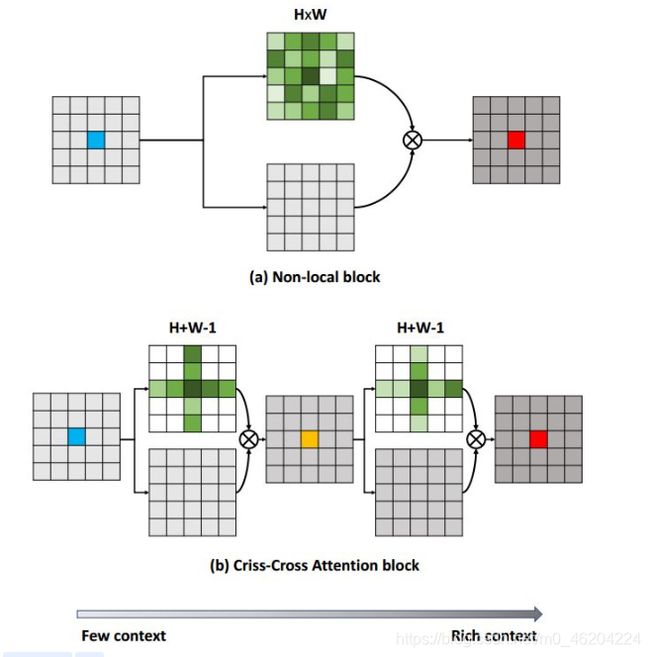
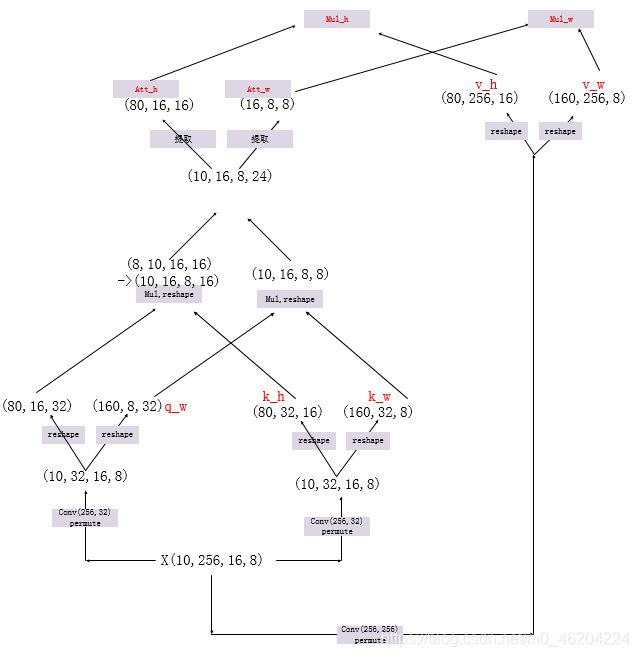
CCNet
参考
Relation-Aware Global Attention
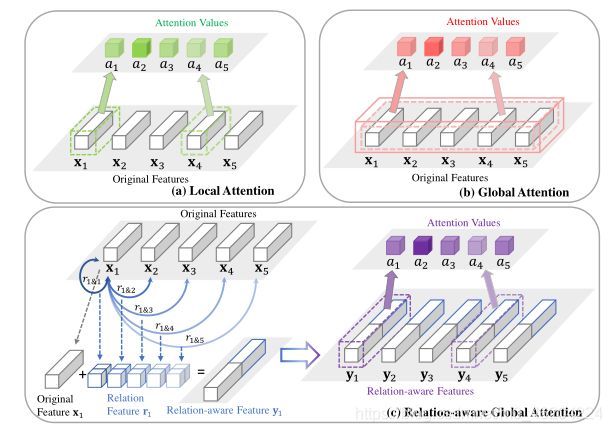
由于Q,K不一样,所以得到的(1,2),(2,1)的关系是有区分的,也就是这篇文章的创新之处
如有不合理的地方,希望大家指正!
