T-C3D 实时行为识别时序卷积网络
论文名称:T-C3D:TemporalConvolutional3D NetworkforReal-TimeActionRecognition
论文地址:https://aaai.org/ocs/index.php/AAAI/AAAI18/paper/view/17205
代码地址:https://github.com/tc3d
最近忙于写论文,也没有时间写博客,今天,我给大家带来一篇行为识别文章《T-C3D:TemporalConvolutional3D NetworkforReal-TimeActionRecognition 》,这篇文章是2018年发表在ECCV上的一篇经典文章,文章出自于北京邮电大学。T3D网络在baseline数据集UCF-101和HMDB-51数据集上精度分别达到了91.8%和62.8%。这篇文章的贡献如下:
- 提出了一个基于3D-CNN的实时动作识别架构,来学习多种粒度的视频表示。学习的特征不仅能够模拟短视频片段之间随时间变化,而且能够模拟整个视频的时间动态;
- 提出了一种具有聚合函数的时间编码技术来模拟整个视频的特征,这大大提高了识别性能;
- 只使用RGB帧作为CNN的输入来实时处理动作识别,同时取得了与现有方法相当的性能。
在开始文章讲解之前,我想简单介绍一些当下行为识别和语义分割的研究热点。其实行为识别和语义分割都属于分类任务,其区别在于分类的关注点不同,但是在随着这两个方向的不断发展,出现了很多要解决的问题,比如语义分割中的FCN网络存在对小目标分割丢失的问题或大目标分割不全的问题。对于行为识别,对于短动作的行为识别,目前的方法已经达取得的很好的结果,但是对于长时序的动作,目前方法还存在问题。其实对于分割和行为识别面临问题属于同一类问题,解决该问题的思路是:局部特征提取,最后进行局部特征融合形成全局的特征。典型网络代表:语义分割PSPNet,行为识别T-C3D。本段话纯属个人理解,如有问题请留言。
按照我写博客的一贯作风,我首先介绍文章的创作灵感,之后当下的一些研究状况,紧接着是研究方法(文章的灵魂),最后是实验部分。
本文创作的的目的是为了解决行为识别网络不实时问题和长时序动作识别问题。那么什么是实时呢?在行为识别领域,具体实时是指端到端的训练,而对于双流网络,由于其结合的光流信息,需要额外时间计算光流图,导致网络不能端到端训练。对于

图1 长短时序动作
长时序动作,为了直观理解,看图1,“弹钢琴”和“射箭”可以很容易地通过静态画面或连续画面之间的小动作的外观信息来识别,然而,有时短剪辑不足以区分类似的类别(跳高和跳远),这时候需要考虑全局的时序特征来进行判别。同时该网络也可以在提取局部时序特征时候,几个卷积共享参数,所以可以大大减低参数量,这个后续用网络结构图来进行解释。
接下来介绍一下行为识别的研究领域最新情况和面临的问题。面临的挑战具体有,视频尺度的变化,杂乱的背景,视点的变化,相机的移动等对网络判别行为有很大的影响,这也是行为识别精度上不去的原因之一,同时,和静态图片识别相比,行为识别是一个序列问题,动作要通过多帧结合来进行有效的识别。在过去的十年中,基于视频的行为识别一直在研究中,开始是基于手工设计的方式来获取视频局部的时空特征,然而,手工特征方式面临设计繁琐,存在大量冗余的特征,具体代表方法有IDT,HOG3D,SIFT-3D。之后随着深度学习的发展,利用卷积来自动提取时空特征成为了主流,这也是现阶段发展的主要方向,具体代表网络有C3D,双流网络。
现在我们介绍本文的重点网络结构,具体如图2,输入为整个视频,分成多个片段作为网络的输入,之后每个片段通多3D CNN来提取局部的时空特征,这些3D CNN共享权重,之后将多个片段进行融合行为对整个视频的表示,最后通过softmax进行行为判别。为了详细阐述这个结构,文章引入了几个部分,具体由Temporal Encoding Model(时序编码模型),Video Components Generation(视频成分产生),3D Convolution Neural Network(3D卷积网络),Aggregation Functions(聚合函数)。接下来对每个部分进行详细介绍:

图2 T-C3D网络结构
Temporal Encoding Model
为了刻画视频的整体特征,引入了Temporal Encoding Model。形式上,给定一个视频V,在时间维上把它统一划分为S部分{P1,P2,P3,…,Ps},然后从Pi中选择一系列帧组成片段Ci。接下来,通过将每个片段经过3D-CNN的作用,获得S个特征图。将S个clips通过聚合函数作用得到视频级特征。最后,根据视频级特征得出最终的类别分数。不同于以往的工作,T-C3D通过视频级而非帧级预测来优化和更新其参数。具体公式如图3,W表示3D CNN的权重,F:表示激活函数,Q:表示聚合函数,H:表示预测函数,用来产生每个类别的概率得分。关于分段损失函数如图4,其中 G = Q(F(C1; W); F(C2; W); ...;F(Cs; W)) ,模型参数导数计算如图5,用于参数更新。

图3 视频最终的类别得分

图4 损失函数
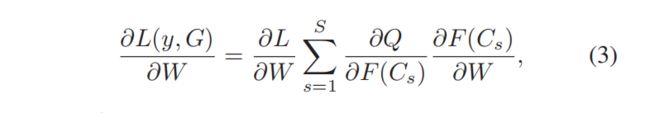
图5 权重导数
Video Components Generation
与静止图像不同,视频是动态的,并且具有不同的序列。为了利用良好的方式对整个视频进行建模,作者首先在时间维度上将视频统一划分为几个部分。然后用两种常用的抽样方案从每个部分抽取多个帧,构成一个clip。第一种方案将前一步生成的视频片段统一划分为一定数量的fragments,并从每个fragments中随机选择一帧构成最终的片段。第二种方法从fragments中随机选择一定数量的连续帧来构造最终片段。实质上,第一采样方法随机选择均匀分布在整个视频中的非连续帧来表示整个视频。第二种方法从整个视频中均匀地选择S个片段,每个片段由一定数量的连续帧组成。后续实验部分给出了两种不同的下采样方法的分类精度。
3D Convolution Neural Network
首先,受深度残差CNN所获得的惊人的图像分类精度的启发,文章采用了一种带有残差块的深度3D-CNN网络。更特别的是,根据ConvNet架构搜索的工作,采用了17个卷积层和一个完全连接层的3D ResNet。实验表明,在给定的多帧图像中,深度残差的3D-CNN可以提取出更丰富、更强的时空特征层次。其次,对CNN的参数进行预训练在大规模数据集上,已被证明对各种视觉任务非常关键,例如目标检测、图像分类、语义分割等。对于3D-CNN,先前的工作如LTC已经表明,在Sprots-1M上预先训练的3D模型比从头训练的模型具有更高的分类精度。本文首先按照C3D中的策略,对Sports-1M模型进行了预训练,虽然Sports-1M有超过100万个视频,但由于没有人工标注,因此含有大量的噪声。最近,Kay(Kay等人。2017)等人提出了一个大规模、干净的数据集,称为Kinetics,涵盖400个人类行为类别,每个行为至少有400个视频clips。为了尽可能地激活3D-CNN中的神经元,作者采用时间编码的方法对3D-CNN进行了Kinetics数据集上训练,实验表明,Kinetics预训练显著提高了训练效果。
Aggregation Functions
聚合函数是T-C3D框架中非常重要的组件。文章详细描述和深入分析四个聚合函数,包括平均池、最大池、加权池和注意力池。接下来我进行一一阐述,这很重要。
- 平均池:平均池的基本假设是利用所有片段的激活进行动作识别,并将其平均响应作为整体视频预测。从这个角度来看,平均池能够联合描述视频片段序列并从整个视频中获得视觉特征。然而,一些视频可能包含与动作无关的噪声序列,在这种情况下,对这些噪声片段进行平均无法准确地建模动作特征,可能导致识别性能的下降。
- 最大池:max pooling的基本直觉是为每个动作类别选择最具辨别力的clip,并以这种最强的响应来表示整个视频,直观地说,它专注于单个clip,而不考虑其他剪辑的激活。在某些情况下,单个clip的辨别力不足以捕获整个视频信息。在某种程度上,T-C3D退化到了以前的工作,即在使用最大池时,用每个视频一个clip来训练网络。因此,这种聚合功能驱动T-C3D仅用一个片段来表示整个视频,这违背了T-C3D对整个视频建模的假设。
- 加权池:此聚合函数的目标是生成一组线性权重,以便在每个clip的输出之间执行元素加权线性融合。实验中,网络权值W和融合权值ω同时优化。该聚合函数根据动作总是由多个阶段组成,这些不同的阶段在识别动作类时可能有不同的影响而产生,同时该聚合函数结合了最大池和均匀池的优点,能够同时减少相关片段的序和噪声片段的不良影响。具体是采用了以S×1为核的卷积层来实现该功能。具体函数定义为如图6.
- 注意力池:此聚合函数的目标与加权池方法相同。它借用了一种端到端可训练记忆网络的记忆注意机制。直觉是利用一个神经模型通过一个可辩别的处理/注意方案读取外部记忆。具体作者将每个片段的输出视为记忆,将特征权重视为记忆处理程序。形式上,让Fs作为第s个片段的经过3D-CNN的特征图,然后聚合模块通过点积用核q对其进行过滤,生成相应的权值序列。具体如图7.

图6 加权池作用机理

图7 注意力池作用机理
最后是实验部分,这部分主要是说明T-C3D最优性和探索实验。图8是T-C3D和一些主流方法的对比。图9帧两种采样方式对比,前面有阐述。图10不同聚合方式对比。图11不同训练方式比较,其中多尺度表示对输入进行裁剪和采用镜像(图像增强)。

图8 和一些主流模型对比

图9 不同采样方式对比

图10 不同聚合函数对比

图11 对于T-C3D不同训练方式比较