Matlab 实现两种读取文件夹内所有图像的方法
使用matlab进行文件夹内所有图片的顺序读取
文件夹:RBG25

在此,使用两种不同的方法来进行文件的读取,以及验证读取的顺序。(方法1符合大多数人的需求)
方法1:使用[路径,特定前缀,序号,后缀]
file_path = '.\RGB25\';% 图像文件夹路径
img_path_list = dir(strcat(file_path,'25_*.tif'));
%dir 列出当前文件夹中的文件信息
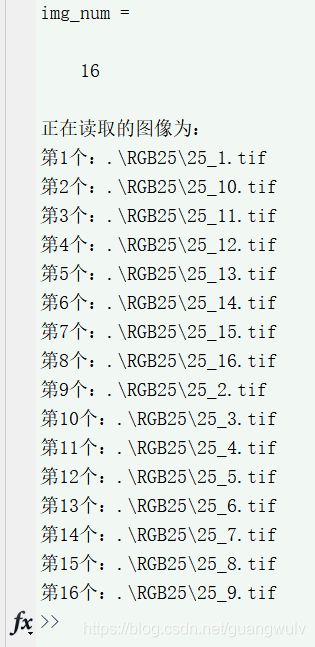
img_num = length(img_path_list)%获取图像总数量
fprintf('正在读取的图像为:\n');
if img_num > 0 %有满足条件的图像
for j = 1:img_num %逐一读取图像
img_name = [file_path,'25_',int2str(j),'.tif'];
pitch=imread(img_name);%4色通道的
fprintf('第%02d个:%s\n',j,img_name);
end
end
运行结果1为:

方法2:使用strcat和.name方法
file_path = '.\RGB25\';% 图像文件夹路径
img_path_list = dir(strcat(file_path,'25_*.tif'));
%dir 列出当前文件夹中的文件信息
img_num = length(img_path_list)%获取图像总数量
fprintf('正在读取的图像为:\n');
if img_num > 0 %有满足条件的图像
for j = 1:img_num %逐一读取图像
image_name = img_path_list(j).name;% 图像名
image = imread(strcat(file_path,image_name));
fprintf('第%d个:%s\n',j,strcat(file_path,image_name)); %显示正在处理的图像名
end
end
运行结果2为:
==========分界线哦~~=
问题:如果采用第二种方法(.name)来对图像进行自然排序读取可不可以呢?
答案是可以的。
先做个测试:试试.name的读序。
file_path = '.\RGB25\';
img_path_list = dir(strcat(file_path,'*.tif'));
img_num = length(img_path_list)
img_path_list.name
结果如下所示:

也就是说:
采用img_path_list.name的读取方法,会先进行所有范围内最高位的最低数值读取;
什么意思呢?
1-29的所有图像,会先读取由1 开头的,故而顺序是:1-10-11-12-…-19-2-20-21…-29。
要怎么才能使得.name可以按人类思维一样,1-2-3-4…顺序读取呢?、
很简单,排序就好了。
通过编写一个排序函数sort_net.m,调用它来对文件夹内的图像进行排序。
img_name =sort_nat({img_path_list.name})
排序函数为:
function [cs,index] = sort_nat(c,mode)
%sort_nat: Natural order sort of cell array of strings.
% usage: [S,INDEX] = sort_nat(C)
%
% where,
% C is a cell array (vector) of strings to be sorted.
% S is C, sorted in natural order.
% INDEX is the sort order such that S = C(INDEX);
%
% Natural order sorting sorts strings containing digits in a way such that
% the numerical value of the digits is taken into account. It is
% especially useful for sorting file names containing index numbers with
% different numbers of digits. Often, people will use leading zeros to get
% the right sort order, but with this function you don't have to do that.
% For example, if C = {'file1.txt','file2.txt','file10.txt'}, a normal sort
% will give you
%
% {'file1.txt' 'file10.txt' 'file2.txt'}
%
% whereas, sort_nat will give you
%
% {'file1.txt' 'file2.txt' 'file10.txt'}
%
% See also: sort
% Version: 1.4, 22 January 2011
% Author: Douglas M. Schwarz
% Email: dmschwarz=ieee*org, dmschwarz=urgrad*rochester*edu
% Real_email = regexprep(Email,{'=','*'},{'@','.'})
% Set default value for mode if necessary.
if nargin < 2
mode = 'ascend';
end
% Make sure mode is either 'ascend' or 'descend'.
modes = strcmpi(mode,{'ascend','descend'});
is_descend = modes(2);
if ~any(modes)
error('sort_nat:sortDirection',...
'sorting direction must be ''ascend'' or ''descend''.')
end
% Replace runs of digits with '0'.
c2 = regexprep(c,'\d+','0');
% Compute char version of c2 and locations of zeros.
s1 = char(c2);
z = s1 == '0';
% Extract the runs of digits and their start and end indices.
[digruns,first,last] = regexp(c,'\d+','match','start','end');
% Create matrix of numerical values of runs of digits and a matrix of the
% number of digits in each run.
num_str = length(c);
max_len = size(s1,2);
num_val = NaN(num_str,max_len);
num_dig = NaN(num_str,max_len);
for i = 1:num_str
num_val(i,z(i,:)) = sscanf(sprintf('%s ',digruns{i}{:}),'%f');
num_dig(i,z(i,:)) = last{i} - first{i} + 1;
end
% Find columns that have at least one non-NaN. Make sure activecols is a
% 1-by-n vector even if n = 0.
activecols = reshape(find(~all(isnan(num_val))),1,[]);
n = length(activecols);
% Compute which columns in the composite matrix get the numbers.
numcols = activecols + (1:2:2*n);
% Compute which columns in the composite matrix get the number of digits.
ndigcols = numcols + 1;
% Compute which columns in the composite matrix get chars.
charcols = true(1,max_len + 2*n);
charcols(numcols) = false;
charcols(ndigcols) = false;
% Create and fill composite matrix, comp.
comp = zeros(num_str,max_len + 2*n);
comp(:,charcols) = double(s1);
comp(:,numcols) = num_val(:,activecols);
comp(:,ndigcols) = num_dig(:,activecols);
% Sort rows of composite matrix and use index to sort c in ascending or
% descending order, depending on mode.
[unused,index] = sortrows(comp);
if is_descend
index = index(end:-1:1);
end
index = reshape(index,size(c));
cs = c(index);
这时候可以看看采用自然排序函数对文件名的读取:
file_path = '.\RGB25\';
img_path_list = dir(strcat(file_path,'*.tif'));
img_num = length(img_path_list);
img_path_list.name;
DirCell = struct2cell(img_path_list);
Dir = sort_nat(DirCell(1,:))
显示结果如下,为cell数组型。

读取为cell数据:
Dir1 = Dir(1)
读取结果为:(cell)

读取为string数据:
Dir1 = Dir{1}
读取结果为:

将sort_net.m与string方式读取结合
最终代码为:
% 文件部分
file_path = '.\RGB25\';
img_path_list = dir(strcat(file_path,'*.tif'));
img_num = length(img_path_list);
% 文件名的数据类型处理
DirCell = struct2cell(img_path_list);%把结构体数组转换成元胞数组
Dir = sort_nat(DirCell(1,:)) %DirCell(1,:)表示第一1列(文件名)
% 读取部分
if img_num > 0
for j = 1:img_num
Dir1 = Dir{j}
image = imread(strcat(file_path,Dir1));
fprintf('第%d个:%s\n',j,strcat(file_path,Dir1));
end
end
最终效果为:
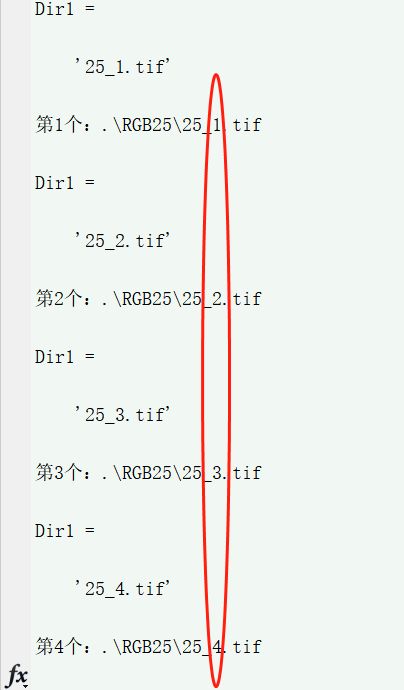
实现了对第2种读取方法的改写,使之能够按照自然排序方式读取。即1-2-3-4…
======END=
写在最后:*
你要相信大多数人与人之间的差距并不大,但是0.99的N次方和1.1的N次方差距是随着N多增多而越来越大的;坚定的目标和持久的努力一定会成功!
你偷过的每一个懒,都会成为你日后最深的遗憾。
我是通信不二,一个积极努力,乐观向上的程序猿!!!