系列教程 | 用Jina搭建PDF搜索引擎Part 3
前两篇文章讲解了PDF搜索的操作方法,本期推送将讲解构建PDF搜索引擎的经验和教训。
之前我们以一个案例为代表讲述的PDF搜索引擎的构建,并不能包揽全部PDF搜索的种类和情况。
我们的初始版本如下:
https://github.com/alexcg1/example-pdf-search/
它旨在:
01具有通用性,并能很好地处理任何类型的PDF数据(强调工作良好 - 仅仅返回结果并不意味着它是好的 - 它需要返回高质量的结果)。
02跨模态搜索,因此你可以使用图像/文本作为输入/输出。
初始版本结果
结果是次优的。我将一些从维基百科下载的 PDF 文件作为示例数据集,从那儿我们可以找到任何事物的维基百科搜索页面。
但数据科学的基本规则是:绝大部分的工作都在于根据用例做数据预处理。由于每个潜在的使用案例都有截然不同的数据,因此花费数小时将维基百科 PDF 整理好没有多大意义。
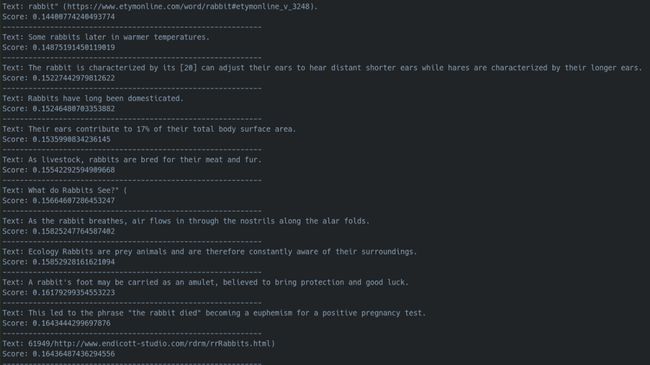
例如,在搜索“兔子耳朵”时:
我们可以得到简短的无序列表的文本片段,这些文本片段只有URL链接或者是只有几个单词长的字符串。
尽管关于兔子耳朵的句子被索引了,但是其中大多数只是关于兔子的,没有提到耳朵。
与一些不太相关的匹配结果相比,最相关的匹配得分较低(在余弦中,分数越低意味着相关性越高)。
尽管键入了所述图像的描述且被索引,但是都无法返回图像。
✦
结果失败原因
01
编码器或模型本身不够好(反驳:CLIP 虽然不适合文本,但是至少是可用的。)
02
也许数据集本身太小了(反驳:虽然它只是几个PDF,但被分解成几千块,其中许多是完整的句子或图像。)
03
索引(*尾注,文本片段,对书页的引用)不是“真实内容”,编码器无法解读其中的大部分内容。(解释:可能是主要问题)
如何调整PDF搜索以适应他人建立的PDF?
到目前为止,在PDF搜索中大多数人都希望只关注文本,这并非坏事。
以前我们试图搜索文本和图像,需要一个编码器可以将两者都嵌入到一个公共向量空间中。即 CLIPEncoder(如下所示):
https://hub.jina.ai/executor/29r2b26t https://hub.jina.ai/executor/29r2b26t
https://hub.jina.ai/executor/29r2b26t
CLIP 非常擅长图像搜索,但是文本搜索体验较为一般!
我们可以用什么来代替CLIP?
如果我们只处理文本,我们可以使用其他编码器,例如:
01
SpacyTextEncoder:支持多种语言,速度快,适合通用文本。
参考链接:
https://hub.jina.ai/executor/u7h7cuh2https://hub.jina.ai/executor/u7h7cuh2
02
TransformerTorchEncoder:支持多种语言和特殊例子(例如医学文本搜索)。
参考链接:
https://hub.jina.ai/executor/u9pqs8ebhttps://hub.jina.ai/executor/u9pqs8eb
我们将建造什么样的搜索引擎?
移动部件更少就能够更清楚地看到工作细节,我们可以采用这种策略构建搜索引擎。
因此,我们我们将为简单文本PDF构建一个搜索引擎,文本不需要太多预处理:
1、删除页码。
2、删除尾注、脚注。
3、处理大量引用和意外标点符号(如 )。Fly-fishing for Dummies, 1988 Penguin Press, A.Albrechtson et al, pp.3–8. http://penguin.com/flyfishing
4、在分页符之间合并文本块。
简而言之,剥离所有可能使编码器无法运作的事物。启动运行后,我们就可以开始考虑:
1、更复杂的 PDF(逐渐增加)。
2、多语言搜索(已经存在用于此的模型)。
3、搜索文本和图像。
欢迎提出对 PDF 搜索的想法!如果您有任何想法,通过https://slack.jina.ai/加入我们的Slack,并在#projects-pdf 频道和我们进一步探讨。