卷积神经网络(CNN)入门总结-基于tensorflow2-含有垃圾分类实战
说明
本项目包含:
1.基本理论知识总结
2.tf2代码使用总结
3.完整实例(以垃圾分类数据集作为例子)
完整代码和数据集请点击下方链接跳转,fork后可以下载完整代码(jupyter notebook),也可在线运行
完整代码点这里下载
基本理论知识总结
一、卷积层
卷积层作为输入层后的第一层,主要目的是提取输入的特征表示。卷积层是由多个特征图组成,每个特征图由多个神经元组成,每个神经元通过卷积核与上一层特征图的局部区域相连。卷积核是一个带权值的矩阵,用于提取和计算不同的特征映射。
1.1 卷积核
卷积核,又叫滤波器,给定输入图像,输入图像中一个小区域中像素,加权后成为输出图像中的每个对应像素,其中权值即为卷积核。也就是说,卷积核实际上可以理解为是一个权值矩阵。
卷积所得的输出的计算公式为:
y i = ∑ w i j ∗ x i + b j y_i = \sum{w_{ij}*x_i+b_j} yi=∑wij∗xi+bj
式中:Xi为输入特征图,Yj为输出特征图,权值记为Wij,bj是其偏置参数。
1.2 卷积运算
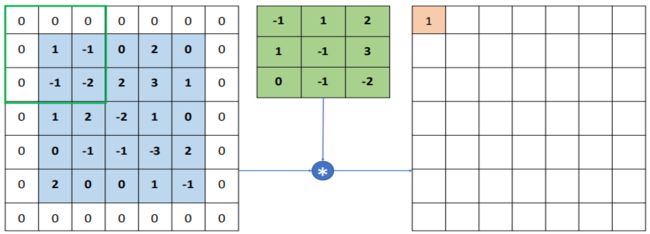
如图所示,对应相乘:-1x1+1x(-1)+2x0+1x(-1)+(-1)x(-2)+2x3+0x1+(-1)x2+(-2)x(-2)=7,完成了一次卷积运算,可以将卷积核作为一个权值矩阵,对图片不同位置进行运算时,共享权值。卷积神经网络每一层输出的特征图上的像素点在输入图片上映射的区域大小叫做感受野(绿色框)。

1.3 多通道卷积运算
1.3.1 彩色图片和灰度图像
灰度图:灰度图像只有一个通道,把白色与黑色之间按对数关系分为若干等级,称为灰度。灰度分为256阶(0-255),数字越大越接近白色,越小越接近黑色 。
RGB图:彩色图有三个通道,是通过对红R、绿(G)、蓝(B)三个颜色通道的变化以及它们相互之间的叠加来得到各式各样的颜色的,RGB即是代表红、绿、蓝三个通道的颜色。(每像素颜色16777216(256 * 256 * 256)种)其中R、G、B由不同的灰度级来描述,每个分量有256级灰度(0-255)
1.3.2 多通道卷积运算
多通道输入,单核卷积,卷出来之后相加(以三通道,单核卷积为例子)

简单说,卷积是乘法,通道间是加法
1.4 padding
以下图为例,5x5的图片矩阵,经过3x3的卷积核,滑动步长为1的卷积运算,得到的特征图大小为:(5-3+1)x(5-3+1)
很明显,随着卷积次数的增加,卷积后的矩阵会越变越小,而且图像的边缘计算次数会小于图像的内部。
所以进行padding操作,即边缘补0,如下图所示,变成了(7-3+1)x(7-3+1)=5x5,得到的特征图大小个原来一样
这样解决了图像越卷越小和边缘计算次数少的问题
二、池化层
2.1 原理和计算方法
基于局部相关性的思想,通过从局部相关的一组元素中进行采样或信息聚合,从而得到新的元素值。
平均池化层:从局部相关元素集中计算平均值并返回
x = avg({1,0,-2,1})=0
最大池化层:从局部相关元素集中选取最大的一个元素值
x = max({1,0,-2,1})=1

2.2 池化层选择
特征提取的误差主要来自两个方面:
(1)邻域大小受限造成的估计值方差增大;
(2)卷积层参数误差造成估计均值的偏移。
平均池化层能减小第一种误差,更多的保留图像的背景信息,最大池化层能减小第二种误差,更多的保留纹理信息。
三、Flatten层
用于将输入层的数据压成一维的数据,因为卷积层处理的是二维数据,全连接层只能接收一维数据,所以用在卷积层和全连接层之间,
四、激活函数
激活函数的主要作用是提供网络的非线性建模能力。如果没有激活函数,那么该网络仅能够表达线性映射,此时即便有再多的隐藏层,其整个网络跟单层神经网络也是等价的。因此也可以认为,只有加入了激活函数之后,深度神经网络才具备了分层的非线性映射学习能力。
4.1 RELU
4.1.1 函数和图像
Relu函数:
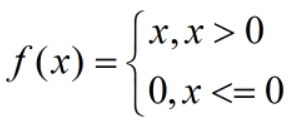
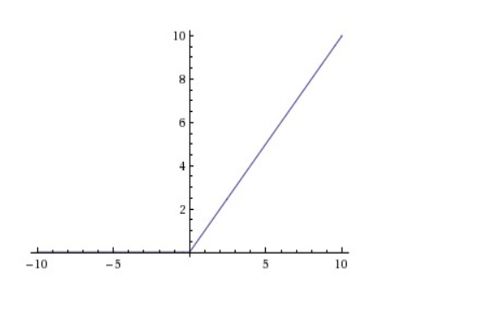
函数图像:
4.1.2 原理
ReLU函数是分段线性函数,会把所有的负值都变为0,而正值不变,被称为单侧抑制。有了单侧抑制,才使得神经网络中的神经元也具有了稀疏激活性。尤其体现在深度神经网络模型(如CNN)中,当模型增加N层之后,理论上ReLU神经元的激活率将降低2的N次方倍。通过ReLU实现稀疏后的模型能够更好地挖掘相关特征,拟合训练数据。
查了相关资料,说是仿生学原理:
“相关大脑方面的研究表明生物神经元的讯息编码通常是比较分散及稀疏的。通常情况下,大脑中在同一时间大概只有1%-4%的神经元处于活跃状态。”不是很能理解,但感觉很厉害。一般在一个使用ReLU的神经网络中大概有50%的神经元处于激活态。
4.1.3 优点
1.相比起Sigmoid和tanh,ReLU 在SGD中能够快速收敛。
2.ReLU导数计算方便。
3.有效缓解了梯度消失的问题。
梯度消失:
在梯度下降中, 随着算法反向的反馈,预测值与真实值之间的误差每传播一层会衰减一次,将导致模型收敛停滞不前,最终没有变化,此时并没有收敛到比好的解
4.2 Sigmoid
4.2.1 函数及其图像
Sigmoid函数:

Sigmoid函数图像:

4.2.2 介绍及优缺点
sigmoid 是使用范围最广的一类激活函数,具有指数函数形状,它在物理意义上最为接近生物神经元,是一个在生物学中常见的S型的函数,也称为S型生长曲线。
优点:
1.Sigmoid函数的输出映射在[0,1]之间,单调连续,输出范围有限,优化稳定,可以用作输出层。
2.求导容易。
缺点:
1.由于其饱和性,容易产生梯度消失,导致训练 出现问题。
2.其输出并不是以0为中心的
4.3 其他激活函数
常用的激活函数还有tanh、RELU、P-ReLU, Leaky-ReLU、ELU、Maxout等等
五、Drop层
5.1 过拟合原因
神经网络层的神经元的参数代表了学到的特征,但是这些特征是被多个神经元共同表征的,当模型复杂度高(神经元过多或者层数过多)且数据集少,就会出现过拟合,即同一个特征被过多的神经元表示,出现了特征冗余。
5.2 Dropout的机制
在每次的神经网络的反向传播中,会随机选择一些神经元,设定其反向传播对应的参数为0,然后对于被改变后的神经网络进行反向传播,相当于在反向传播时有一些"神经元"被移除了(与L1正则化效果相同)
主要参数:dropout( rate=丢弃率) 设置为 0.1,则意味着会丢弃 10% 的神经元
六、其他相关
6.1 为什么使用归一化
6.1.1 归一化
归一化是一种简化计算的方式,即将有量纲的表达式,经过变换,化为无量纲的表达式
6.1.1 对图像进行归一化处理
在深度学习中,对数据进行归一化是为了将特征值尺度调整到相近的范围,特征尺度不同,梯度也不同,
而梯度更新时的学习率是相同的。如果学习率小,梯度小的就更新慢,如果学习率大,梯度大的方向不稳定,不易收敛,
通过归一化,把不同维度的特征值范围调整到相近的范围内,就能统一使用较大的学习率加速学习
输入图像的像素值数值范围是0~255之间,一般是将像素值除以255
6.2 图像尺寸选择
查阅相关资料后,此处目前没有发现很详细和准确的答案和说明,更多是一些经验和实验结果:
1.一般输入图像都会令图像长=宽,即取正方形,可以使得卷积结果更好,且方便后续处理。一般取32× 32, 64× 64, 224× 224, 227× 227, 256× 256, 299×299等
2.图片尺寸越大,其包含的纹理特征和判别特征会更容易被捕捉。
3.图片尺寸大到一定程度,效果反而会变差,因为卷积核目前大部分还是以3x3为主,捕捉的特征可能会不完整,而且大尺寸图片意味着更大的计算开销。
tensorflow2.X代码使用详解
数据集说明
该数据集包含了2527个生活垃圾图片。数据集的创建者将垃圾分为了6个类别,分别是:
玻璃(glass)共501个图片
纸(paper)共594个图片
硬纸板(cardboard)共403个图片
塑料(plastic)共482个图片
金属(metal)共410个图片
一般垃圾(trash)共137个图片
物品都是放在白板上在日光/室内光源下拍摄的,压缩后的尺寸为512 * 384。
有GPU使用,若无使用cpu
from tensorflow import keras
from tensorflow.keras import layers,models
import os, PIL, pathlib
import matplotlib.pyplot as plt
import tensorflow as tf
gpus = tf.config.list_physical_devices("GPU")
if gpus:
gpu0 = gpus[0] #如果有多个GPU,仅使用第0个GPU
tf.config.experimental.set_memory_growth(gpu0, True) #设置GPU显存用量按需使用
tf.config.set_visible_devices([gpu0],"GPU")
gpus
一、加载数据集
data_dir = "/home/mw/input/trash_div7612/trash-classification/dataset-resized/"
data_dir = pathlib.Path(data_dir)
1.1 加载数据集的方法:tf.keras.preprocessing.image_dataset_from_directory
image_dataset_from_directory函数及参数含义,参考官网说明
tf.keras.preprocessing.image_dataset_from_directory(
directory, #数据所在目录,本项目labels按照默认,所以应该路径应该包含子目录,每个子目录包含一种类型的文件
labels=“inferred”, #标签从目录结构生成,或者是整数标签的列表/元组,本项目中是按照给出的目录结构生成,参数按照默认值
label_mode=“int”, #标签类型:1.int,默认值,标签将被编码成整数,2.categorical:标签将被编码为分类向量 3.binary:二值化标签,值为0或1的float32标量 4.None:无标签
class_names=None, #仅当labels为inferred时有效。这是类名称的明确列表(必须与子目录的名称匹配)。用于控制类的顺序(否则使用字母数字顺序)
color_mode=“rgb”, #grayscale(1通道)、rgb(3通道)、rgba(4通道),默认值:rgb。
batch_size=32, #批次大小
image_size=(256, 256), #读取数据后将其重新调整大小,必要参数。
shuffle=True, #是否打乱,默认打乱
seed=None, #随机种子
validation_split=None, #数据划分,0~1之间,保留验证集
subset=None, #要返回的数据的子集。“训练集”或“验证集”之一。仅当设置了validation_split时才使用。
interpolation=“bilinear”, #当调整图像大小时使用的插值方法
follow_links=False, #是否访问符号链接指向的子目录
)
备注
1)label_mode=“int”(默认值),表示标签被编码成整数,使用的损失函数应为:sparse_categorical_crossentropy loss。
2)label_mode=“categorical”,标签将被编码为分类向量,使用的损失函数应为:categorical_crossentropy loss。
1.2 对应代码
train_ds = tf.keras.preprocessing.image_dataset_from_directory(
"/home/mw/input/trash_div7612/trash-classification/dataset-resized/", #数据集目录
label_mode="categorical", #标签模式,根据目录生成
validation_split=0.2, # 验证集比例为20%
subset="training", #这是个训练集
seed=42 , #随机种子,保证划分一致
image_size=(img_height, img_width), #图像大小
batch_size=batch_size)
val_ds = tf.keras.preprocessing.image_dataset_from_directory(
"/home/mw/input/trash_div7612/trash-classification/dataset-resized/",
label_mode="categorical",
validation_split=0.2,
subset="validation",
seed=123,
image_size=(img_height, img_width),
batch_size=batch_size)
1.3 数据准备和加速
主要设计的参数和函数有4个:
cache、shuffle、prefetch、buffer_size
这里一个个介绍
1.3.1 Shuffle
Dataset-API文档:
API文档
参数
shuffle(
buffer_size, seed=None, reshuffle_each_iteration=None, name=None
)
随机洗牌此数据集的元素。
参数说明
参数buffer_size:
一个 tf.int64 标量 tf.张量,表示此数据集中新数据集将从中采样的元素数
API文档说明:
This dataset fills a buffer with elements, then randomly samples elements from this buffer, replacing the selected elements with new elements. For perfect shuffling, a buffer size greater than or equal to the full size of the dataset is required
此数据集用元素填充缓冲区,然后从此缓冲区中随机采样元素,用新元素替换所选元素。为了进行完美的随机排序,需要缓冲区大小大于或等于数据集的完整大小。
For instance, if your dataset contains 10,000 elements but is set to 1,000, then will initially select a random element from only the first 1,000 elements in the buffer. Once an element is selected, its space in the buffer is replaced by the next (i.e. 1,001-st) element, maintaining the 1,000 element buffer
例如,如果您的数据集包含 10,000 个元素,但设置为 1,000 个,则最初将仅从缓冲区中的前 1,000 个元素中选择一个随机元素。选择元素后,其在缓冲区中的空间将被替换为下一个(即 1,001-st)元素,从而保留 1,000 元素缓冲区。
reshuffle_each_iteration
控制每个epoch的顺序是否不同
buffer_size个人理解:
先看官方文档说明,‘a buffer size greater than or equal to the full size of the dataset is required’这句话说参数 buffer size需要大于或等于数据集的大小,但是用例里面, buffer size<数据集的大小,貌似有些许的冲突
eg1:buffer size小于数据集
我们有5个球命名为1-5,按顺序放置在一个有5个格子的盒子A里(全量数据),我们需要打乱它,取出3个球作为训练集,首先要准备另一个3个格子的盒子B(缓冲区)然后进行以下操作:
1.从A取1-3号球放置在盒子B;
2.随机从B中取出一个球,假设是2号;
3.4号球放置在盒子B的2号位,此时盒子B填充满(球编号为1-4-3),再随机取出一个球,比如1号球。
4.5号球放置在盒子B的1号位,此时盒子B填充满(球编号为5-4-3),再随机取出一个球,比如5号球。
5.随机抽取从B(3-4)中抽取3号;
6.随机抽取从B(4)中抽取4号;
7.最终会形成一个新的序列,即2-1-5-3-4
eg2:buffer size大于数据集
可以看作,每次随机不放回的抽走一个球,最终排出一个新的序列,少了顺序插值替换这一步
下面进行三组测试查看一下区别
buffer_size=3 #盒子B大小为3
data = np.array([1, 2, 3, 4, 5]) #五个球排排坐
label = np.array([1, 1, 1, 0, 0]) #随便搞得标签
dataset = tf.data.Dataset.from_tensor_slices((data, label))
dataset = dataset.shuffle(buffer_size)
it = dataset.__iter__()
for i in range(5):
x, y = it.next()
print(x, y)
测试1:buffer_size=3
某次运行结果
输出为:
tf.Tensor(2, shape=(), dtype=int64) tf.Tensor(1, shape=(), dtype=int64)
tf.Tensor(1, shape=(), dtype=int64) tf.Tensor(1, shape=(), dtype=int64)
tf.Tensor(5, shape=(), dtype=int64) tf.Tensor(0, shape=(), dtype=int64)
tf.Tensor(3, shape=(), dtype=int64) tf.Tensor(1, shape=(), dtype=int64)
tf.Tensor(4, shape=(), dtype=int64) tf.Tensor(0, shape=(), dtype=int64)
测试2:buffer_size=6
某次运行结果
tf.Tensor(5, shape=(), dtype=int64) tf.Tensor(0, shape=(), dtype=int64)
tf.Tensor(4, shape=(), dtype=int64) tf.Tensor(0, shape=(), dtype=int64)
tf.Tensor(3, shape=(), dtype=int64) tf.Tensor(1, shape=(), dtype=int64)
tf.Tensor(1, shape=(), dtype=int64) tf.Tensor(1, shape=(), dtype=int64)
tf.Tensor(2, shape=(), dtype=int64) tf.Tensor(1, shape=(), dtype=int64)
测试3:buffer_size=1
运行结果:
tf.Tensor(1, shape=(), dtype=int64) tf.Tensor(1, shape=(), dtype=int64)
tf.Tensor(2, shape=(), dtype=int64) tf.Tensor(1, shape=(), dtype=int64)
tf.Tensor(3, shape=(), dtype=int64) tf.Tensor(1, shape=(), dtype=int64)
tf.Tensor(4, shape=(), dtype=int64) tf.Tensor(0, shape=(), dtype=int64)
tf.Tensor(5, shape=(), dtype=int64) tf.Tensor(0, shape=(), dtype=int64)
一些总结
1.在shuffle中,buffer size是一个必要的参数,查了一些博客,一般来说都是将buffer size设置为小于数据集大小,即和官方用例相同。(测试1)
2.尽管官方文档有冲突,但是如果buffer size需要大于数据集,就等于是一个普通的不放回抽样(测试2)
3.上述二者最明显的区别:测试2中,4和5号球可能会被首次抽中,而测试1则不行。
4.buffer 不能太小,比如测试3,极端情况下,数据等于没打乱。
增加一个buffer的意义在于:
1.数据量足够大时,有了buffer 之后可以增加随机性,随着数据的抽取,buffer 会变得越来越混乱,新的序列也会越来越混乱
2.还有一个是从打乱数据的储存来着手,即eg1中,第一次取出的2号小球放在哪里,第一种是放在新的数据集的第一个位置,第二种就是放在原数据集的1号位置,即放在盒子A的一号位,因为此时盒子A前三个储存位置是空置的。个人更倾向于第二种情况,因为这样避免了生成一个空置的新序列,也就是说将buffer作为一个置换空间。
1.3.2 prefetch
函数及参数
prefetch(
buffer_size, name=None
)
参数buffer_size
一个 tf.int64 标量 tf.张量,表示预取时将缓冲的最大元素数。如果使用值 tf.data.AUTOTUNE,则会动态调整缓冲区大小。
简单说:
CPU处理数据,GPU做运算,不用prefetch,可以理解为串行,帮厨洗菜大厨玩手机,洗完大厨才切菜炒菜,这个时候帮厨就玩手机;
用了之后,变成并行了,大厨炒菜的时候,帮厨就不能玩手机了,得去洗第二道菜需要的菜,然后等大厨炒完菜发现菜又快洗好了。
这样看,如果只用CPU,这个参数应该就没有作用了。
1.3.3 cache
cache(
filename=‘’, name=None
)
filename=:一个 tf.string 标量 tf.张量,表示文件系统上用于缓存此数据集中的元素的目录的名称。如果未提供文件名,则数据集将缓存在内存中。
缓存此数据集中的元素。
首次迭代数据集时,其元素将缓存在指定的文件或内存中。后续迭代将使用缓存的数据
1.4 代码
AUTOTUNE = tf.data.AUTOTUNE
train_ds = train_ds.cache().shuffle(1200).prefetch(buffer_size=AUTOTUNE)
val_ds = val_ds.cache().prefetch(buffer_size=AUTOTUNE)
二、模型构建
2.1 卷积网络构造代码简要说明
1.models.Sequential():
Sequential()方法是一个容器,描述了神经网络的网络结构,在Sequential()的输入参数中描述从输入层到输出层的网络结构,可以在()中自定义搭建神经网络的网络结构,类比在桌面上拼积木的话,Sequential()相当于放置积木的桌面。
2.Conv2D():
卷积层,动态提取图片局部特征,
tf.keras.layers.Conv2D(
input_shape = (高, 宽, 通道数), #仅在第一层有
filters = 卷积核个数,对应输出的维数
kernel_size = 卷积核尺寸,(n,k),如果为一个整数则宽和高相同
strides = 卷积横向和纵向的步长,如果为一个整数则横向和纵向相同
padding = ‘SAME’ or ‘VALID’,valid:表示不够卷积核大小的块,则丢弃;same表示不够卷积核大小的块就补0,所以输出和输入形状相同
activation = ‘relu’ or ‘sigmoid’ or ‘tanh’ or ‘softmax’等
)
3.Dropout():
drop层,为了减少过拟合。Dropout的机制:在每次的神经网络的反向传播中,会随机选择一些神经元,设定其反向传播对应的参数为0,然后对于被改变后的神经网络进行反向传播,相当于在反向传播时有一些"神经元"被移除了(与L1正则化效果相同)
主要参数:dropout( rate=丢弃率) 设置为 0.1,则意味着会丢弃 10% 的神经元
4.MaxPooling2D():
layers.MaxPooling2D((2, 2))
主要参数:pool_size:2个整数的整数或元组/列表:(pool_height,pool_width),用于指定池窗口的大小;可以是单个整数,以指定所有空间维度的相同值.
平均池化层为AvgPooling2D()
5.Flatten(): 用于将输入层的数据压成一维的数据
6.Dense(): 全连接层
主要参数: layers.Dense(units, activation), #全连接层,特征进一步提取
units:输出的维度大小,即神经元的个数
activation:激活函数
7.model.summary(): 打印模型结构
2.2 代码
model = models.Sequential([
layers.experimental.preprocessing.Rescaling(1./255, input_shape=(img_height, img_width, 3)),
layers.Conv2D(16, (3, 3), activation='relu', input_shape=(img_height, img_width, 3)), # 卷积层1,卷积核3*3
layers.MaxPooling2D((2, 2)), # 池化层1,2*2采样
layers.Conv2D(32, (3, 3), activation='relu'), # 卷积层2,卷积核3*3
layers.MaxPooling2D((2, 2)), # 池化层2,2*2采样
layers.Conv2D(64, (3, 3), activation='relu'), # 卷积层3,卷积核3*3
layers.Dropout(0.2),
layers.Flatten(), # Flatten层,连接卷积层与全连接层
layers.Dense(128, activation='relu'), # 全连接层,特征进一步提取
layers.Dense(len(class_names)) # 输出层,输出预期结果
])
model.summary() # 打印网络结构

三、模型编译
3.1 学习率
3.1.1 学习率选择
1)大的学习率,可以加快学习速度,快速到达最优解附近,但是过大的学习率,也会导致无法收敛,在最优解附近震荡。
比如本次项目的学习率设置为0.1时效果就很差,acc处于0.5附近,无法进一步收敛。
2)小的学习率,会以更小的步长来进行学习,更加靠近最优解,但是容易陷入局部最优解。
总的来说。合适的学习率能够使目标函数在合适的时间和轮次内收敛到局部最小值,具体取值还需要进行一定的尝试。
3.1.2 动态学习率
对学习率应用指数衰减
官方文档链接
官方文档
函数及参数
tf.keras.optimizers.schedules.ExponentialDecay(
initial_learning_rate, # 最初学习率
decay_steps,# 喂入多少轮BATCH-SIZE以后,更新一次学习率。一般为总样本数量/BATCH_SIZE
decay_rate, # 学习率的衰减
staircase=False, # 如果staircase=True,那就表明每decay_steps次计算学习速率变化,更新原始学习速率,如果是False,那就是每一步都更新学习速率。
name=None
)
计算公式
1.当staircase=False时
计算公式(函数)
def decayed_learning_rate(step):
return initial_learning_rate * decay_rate ^ (step / decay_steps)
衰减后的学习率 = 初始学习率x衰减系数^(全局步数/衰减步数)
学习率是每次逐渐衰减的
2.当staircase=True时, (step / decay_steps)会向下取整,即阶梯型向下衰减,是突然衰减的
例子
比如这是staircase为True的情况,比如给定初始学习率为1e-3,学习率衰减率为0.95,decay_steps为54,训练数据量为1714(1714/32=54,即每个eopch学习率衰减一次)。
则随着迭代次数从1到2,第二轮的学习率变为0.001*0.95(54/54)=9.5e-4,第三轮是0.001*0.95(108/54)=9.025e-4
如果是False,学习率变动就是指数型0.001*0.95(1/54),0.001*0.95(2/54).。。。。。。。0.001*0.95^(54/54)
3.2 损失函数
3.2.1 函数具体参数
1)SparseCategoricalCrossentropy------API文档
tf.keras.losses.SparseCategoricalCrossentropy(
from_logits=False, #主要参数:默认为False,表示输出的logits需要经过激活函数的处理,True则不需要
reduction=losses_utils.ReductionV2.AUTO,
name=‘sparse_categorical_crossentropy’
)
2)CategoricalCrossentropy------API文档
tf.keras.losses.CategoricalCrossentropy(
from_logits=False,#主要参数:同上
label_smoothing=0.0,
axis=-1,
reduction=losses_utils.ReductionV2.AUTO,
name=‘categorical_crossentropy’
)
3.2.2 区别
1)对于CategoricalCrossentropy来说,labels必须是是one-hot编码,即[1, 0, 0],[0, 1, 0],[0, 0, 1]],计算预测标签值与真实标签值的多类交叉熵.
2)对于SparseCategoricalCrossentropy来说,labels需要时整数,即[1,2,3]。sparse是稀疏的意思,labels稀疏指的是label有很多类别,在one-hot编码后,会出现大量的0,这个时候的标签矩阵就是高维稀疏矩阵了。
initial_learning_rate = 1e-3
lr_schedule = tf.keras.optimizers.schedules.ExponentialDecay(
initial_learning_rate, #设置初始学习率
decay_steps=64, #每隔多少个step衰减一次
decay_rate=0.94, #衰减系数
staircase=True)
# 将指数衰减学习率送入优化器
optimizer = tf.keras.optimizers.Adam(learning_rate=lr_schedule)
model.compile(optimizer=optimizer,
# loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
loss=tf.keras.losses.CategoricalCrossentropy(from_logits=True),
metrics=['accuracy'])
四、保存最佳参数、设置过早停
4.1 过早停
使用早停可以节约训练时间、防止可能发生的过拟合(训练次数太多,拟合到了噪声)
1)函数调用及说明
tf.keras.callbacks.EarlyStopping(
monitor=‘val_loss’,
min_delta=0,
patience=0,
verbose=0,
mode=‘auto’,
baseline=None,
restore_best_weights=False
)
2)EarlyStopping()参数说明:
● monitor: 被监测的指标数值,即选择一个评价指标,本项目中选择的时验证集的acc
● min_delta: 在被监测的数据中被认为是提升的最小变化, 例如本项目中,min_delta=0.001,即验证集acc的绝对变化小于0.001,会被认为没有提升。
● patience: 没有进步的训练轮数,在这之后训练就会被停止,patient不宜设置过小,防止因为一些局部震荡导致过早停止训练,无法取得最优解。当然,设置的过大,EarlyStopping的意义就没了。比如下面设置为30个epochs之后没有变化就会停止训练。
● verbose: 详细信息模式。默认为0,选择1将在回调执行操作时显示消息。
● mode: {auto, min, max} 其中之一。 在 min 模式中, 当被监测的数据停止下降,训练就会停止;在 max 模式中,当被监测的数据停止上升,训练就会停止;在 auto 模式中,方向会自动从被监测的数据的名字中判断出来。比如监听loss就会按照下降,acc就会按照上升。
● baseline: 要监控的数量的基准值。 如果模型没有显示基准的改善,训练将停止。
● restore_best_weights: 是否从具有监测数量的最佳值的时期恢复模型权重。 如果为 False,则使用在训练的最后一步获得的模型权重。设置为True,则自动查找最优的monitor指标时的模型参数进行恢复。
4.2 保存最优模型
1)函数及参数
tf.keras.callbacks.ModelCheckpoint(
filepath, #文件地址及名称
monitor: str = ‘val_loss’, #监控指标
verbose: int = 0, #是否打印信息,0是否,1是打印
save_best_only: bool = False, #仅保存最优
save_weights_only: bool = False, #仅保存权重
mode: str = ‘auto’,
save_freq=‘epoch’, 每个几个epoch保存一次
options=None,
initial_value_threshold=None,
**kwargs
)
from tensorflow.keras.callbacks import ModelCheckpoint, EarlyStopping
epochs = 20
# 保存最佳模型参数
checkpointer = ModelCheckpoint('best_model.h5',
monitor='val_accuracy',
verbose=1,
save_best_only=True,
save_weights_only=True)
# 设置早停
earlystopper = EarlyStopping(monitor='val_accuracy',
min_delta=0.001,
patience=10,
verbose=1)
五、模型训练
history = model.fit(train_ds,
validation_data=val_ds,
epochs=epochs,
callbacks=[checkpointer, earlystopper])
六、模型优化的方法
使用了这些方法不代表一定能够优化模型,解决过拟合等问题,具体是否使用、参数如何设置,更多是靠经验和尝试。
6.1 添加drop层
drop层原理在上面已经有说明,设置丢弃比例一般是靠经验和尝试,一般先设置为0,看效果,如果过拟合,设置0.4~0.6,欠拟合就降低,如此反复。
drop_rate = 0.1
model_test1 = models.Sequential([
layers.experimental.preprocessing.Rescaling(1./255, input_shape=(img_height, img_width, 3)),
layers.Conv2D(64, (3, 3),padding='same', activation='relu', input_shape=(img_height, img_width, 3)),
layers.Dropout(drop_rate),
layers.Conv2D(64, (3, 3), padding='same',activation='relu'),
layers.Dropout(drop_rate),
layers.AveragePooling2D(pool_size=(2,2),strides=(2,2)),
layers.Flatten(),
layers.Dense(128, activation='relu'),
layers.Dense(len(class_names))
])
model_test1.summary() # 打印网络结构
6.2 添加L2 正则化
from tensorflow.keras.regularizers import l2
weight_decay=0.005
model_test2 = models.Sequential([
layers.experimental.preprocessing.Rescaling(1./255, input_shape=(img_height, img_width, 3)),
layers.Conv2D(64, (3, 3),padding='same',kernel_regularizer=l2(weight_decay), activation='relu', input_shape=(img_height, img_width, 3)),
layers.Conv2D(64, (3, 3), padding='same',kernel_regularizer=l2(weight_decay),activation='relu'),
layers.AveragePooling2D(pool_size=(2,2),strides=(2,2)),
layers.Flatten(), # Flatten层,连接卷积层与全连接层
layers.Dense(128, activation='relu'), # 全连接层,特征进一步提取
layers.Dense(len(class_names)) # 输出层,输出预期结果
])
model_test2.summary() # 打印网络结构
6.3 添加BatchNormalization层
model_test3 = models.Sequential([
layers.experimental.preprocessing.Rescaling(1./255, input_shape=(img_height, img_width, 3)),
layers.Conv2D(64, (3, 3),padding='same', activation='relu', input_shape=(img_height, img_width, 3)),
layers.BatchNormalization(),
layers.Conv2D(64, (3, 3), padding='same',activation='relu'),
layers.BatchNormalization(),
layers.AveragePooling2D(pool_size=(2,2),strides=(2,2)),
layers.Flatten(), # Flatten层,连接卷积层与全连接层
layers.Dense(128, activation='relu'), # 全连接层,特征进一步提取
layers.Dense(len(class_names)) # 输出层,输出预期结果
])
model_test3.summary() # 打印网络结构
七、直接使用已有网络
目前有很多成熟网络,比如VGG系列,Resnet系列等等,都可以直接调用或者按照网络结构自行搭建
7.1 直接调用(以VGG16为例子)
VGG16直接调用文档
tf.keras.applications.vgg16.VGG16(
include_top=True, #是否使用顶层
weights=‘imagenet’,#是否加载imgenet预训练参数
input_tensor=None,
input_shape=None,#输入向量形状
pooling=None,#max或avg,最大或平均池化层
classes=1000,#如果使用顶层且使用预训练参数,分类数必须为1000,否则可以自己改动
classifier_activation=‘softmax’#分类激活函数
)
顶层就是全连接层和分类层
model_Vgg16 = tf.keras.applications.vgg16.VGG16(
include_top=True,
weights='imagenet',
input_tensor=None,
input_shape=None,
pooling=max,
classes=1000,
classifier_activation='softmax'
)
model_Vgg16.summary() # 打印网络结构
7.2 自己搭建
自己搭建的好处是灵活,可以选择对网络进行调优
VGG16_model2 = models.Sequential([
layers.experimental.preprocessing.Rescaling(1./255, input_shape=(224, 224, 3)),
#两次使用64个3*3的卷积核,采用l2正则化,池化后维度(112,112,64)
layers.Conv2D(64, (3, 3),padding='same', activation='relu', input_shape=(img_height, img_width, 3)),
layers.Conv2D(64, (3, 3), padding='same',activation='relu'),
layers.AveragePooling2D(pool_size=(2,2),strides=(2,2)),
#两次使用128个3*3的卷积核,池化后维度(56,56,128)
layers.Conv2D(128, (3, 3),padding='same',kernel_regularizer=l2(weight_decay),activation='relu'),
layers.Conv2D(128, (3, 3),padding='same',kernel_regularizer=l2(weight_decay),activation='relu'),
layers.AveragePooling2D(pool_size=(2,2),strides=(2,2)),
#三次使用256个3*3的卷积核,池化后维度(28,28,256)
layers.Conv2D(256, (3, 3), padding='same',kernel_regularizer=l2(weight_decay),activation='relu'),
layers.Conv2D(256, (3, 3), padding='same',kernel_regularizer=l2(weight_decay),activation='relu'),
layers.Conv2D(256, (3, 3),padding='same',kernel_regularizer=l2(weight_decay),activation='relu'),
layers.AveragePooling2D(pool_size=(2,2),strides=(2,2)),
#三次使用512个3*3的卷积核,池化后维度(14,14,512)
layers.Conv2D(512, (3, 3),padding='same',kernel_regularizer=l2(weight_decay),activation='relu'),
layers.Conv2D(512, (3, 3),padding='same',kernel_regularizer=l2(weight_decay),activation='relu'),
layers.Conv2D(512, (3, 3),padding='same',kernel_regularizer=l2(weight_decay),activation='relu'),
layers.AveragePooling2D(pool_size=(2,2),strides=(2,2)),
layers.Conv2D(512, (3, 3),padding='same',kernel_regularizer=l2(weight_decay),activation='relu'),
layers.Conv2D(512, (3, 3),padding='same',kernel_regularizer=l2(weight_decay),activation='relu'),
layers.Conv2D(512, (3, 3),padding='same',kernel_regularizer=l2(weight_decay),activation='relu'),
layers.AveragePooling2D(pool_size=(2,2),strides=(2,2)),
layers.Flatten(),
layers.Dense(4096, activation='relu'),
layers.Dense(4096, activation='relu'),
layers.Dense(len(class_names), activation="softmax")
])
VGG16_model2.summary() # 打印网络结构
7.3 加载预训练参数
VGG16_model_con = models.Sequential([
layers.experimental.preprocessing.Rescaling(1./255, input_shape=(224, 224, 3)),
#两次使用64个3*3的卷积核,池化后维度(112,112,64)
layers.Conv2D(64, (3, 3),padding='same', activation='relu', input_shape=(img_height, img_width, 3)),
layers.Conv2D(64, (3, 3), padding='same',activation='relu'),
layers.AveragePooling2D(pool_size=(2,2),strides=(2,2)),
#两次使用128个3*3的卷积核,池化后维度(56,56,128)
layers.Conv2D(128, (3, 3),padding='same',activation='relu'),
layers.Conv2D(128, (3, 3),padding='same',activation='relu'),
layers.AveragePooling2D(pool_size=(2,2),strides=(2,2)),
#三次使用256个3*3的卷积核,池化后维度(28,28,256)
layers.Conv2D(256, (3, 3), padding='same',activation='relu'),
layers.Conv2D(256, (3, 3), padding='same',activation='relu'),
layers.Conv2D(256, (3, 3),padding='same',activation='relu'),
layers.AveragePooling2D(pool_size=(2,2),strides=(2,2)),
#三次使用512个3*3的卷积核,池化后维度(14,14,512)
layers.Conv2D(512, (3, 3),padding='same',activation='relu'),
layers.Conv2D(512, (3, 3),padding='same',activation='relu'),
layers.Conv2D(512, (3, 3),padding='same',activation='relu'),
layers.AveragePooling2D(pool_size=(2,2),strides=(2,2)),
layers.Conv2D(512, (3, 3),padding='same',activation='relu'),
layers.Conv2D(512, (3, 3),padding='same',activation='relu'),
layers.Conv2D(512, (3, 3),padding='same',activation='relu'),
layers.AveragePooling2D(pool_size=(2,2),strides=(2,2)),
])
VGG16_model_con.summary() # 打印网络结构
# 加载模型参数
VGG16_model_con.load_weights('/home/mw/project/vgg16_weights_tf_dim_ordering_tf_kernels_notop.h5')
# 冻结前13层网络参数 保证加载的预训练参数不被改变
for layer in VGG16_model.layers[:13]:
layer.trainable = False
# 添加模型分类层(顶层)
VGG16_model_all = models.Sequential([
VGG16_model_con,
layers.Flatten(),
layers.Dense(1024, activation='relu'),
layers.Dense(128, activation='relu'),
layers.Dense(len(class_names), activation="softmax")
])
VGG16_model_all.summary() # 打印网络结构
八、数据增强
处理层文档
tensorflow.keras.layers.experimental.preprocessing自带几种数据增强
1.RandomFlip(mode):将输入的图片进行随机翻转, mode=“horizontal” ,代表水平旋转;而 mode=“vertical” 则代表随机进行上下翻转;horizontal_and_vertical水平+上下
2.RandomRotation(factor): 将输入的图片按照旋转角度(单位为弧度) factor 将输入的图片进行随机的旋转,正值表示逆时针旋转,而负值表示顺时针旋转;当表示为单个浮点数时,此值将同时用于上限和下限。例如, factor=(-0.2, 0.3) 导致输出旋转范围为 [-20% * 2pi, 30% * 2pi] 内的随机量。 factor=0.2 导致输出旋转范围为 [-20% * 2pi, 20% * 2pi] 的随机量;也有多种模式fill_mode=‘constant’, ‘reflect’, ‘wrap’, 'nearest’之一,具体可以查看上述文档;
3.RandomContrast(factor):按照 P 的概率将输入的图片进行随机的图像色相翻转;factor表示为值分数的正浮点数,或表示下限和上限的大小为 2 的元组。当表示为单个浮点数时,下限 = 上限。对比度因子将在区间内随机选取。对于通道中的任何像素 x,输出将是通道的平均值。[1.0 - lower, 1.0 + upper] (x - mean) * factor + mean
4.RandomCrop(height, width):随机裁剪,同一批次数据按照相同的随机位置裁剪
5.RandomHeight(factor)、RandomWidth(factor):用法和RandomRotation一样,设定范围内随机调整高和宽
6.RandomTranslation(height_factor,width_factor,):该层将在训练期间对每个图像应用随机平移(上下,左右),factor设置方法和上面一样
7.RandomZoom(height_factor,width_factor): 该层将独立地随机放大或缩小图像的每个轴。正值表示缩小,而负值表示放大,其他设置方法与上述一致
8.1 在模型中直接使用
自定义一个数据增强模型序列,然后和模型序列进行拼接就可以了,也可以直接写入
data_augmentation = tf.keras.Sequential([
layers.experimental.preprocessing.RandomFlip("horizontal_and_vertical"),
layers.experimental.preprocessing.RandomRotation(0.2),
layers.experimental.preprocessing.RandomContrast(0.3),
])
model_aug = models.Sequential([
layers.experimental.preprocessing.Rescaling(1./255, input_shape=(224, 224, 3)),
data_augmentation,
layers.Conv2D(64, (3, 3),padding='same', activation='relu'),
layers.Conv2D(64, (3, 3), padding='same',activation='relu'),
layers.AveragePooling2D(pool_size=(2,2),strides=(2,2)),
layers.Flatten(),
layers.Dense(128, activation='relu'),
layers.Dense(2, activation="softmax")
])
model_aug.summary()
8.2 在加载数据集时使用
AUTOTUNE = tf.data.AUTOTUNE
def prepare(ds):
ds = ds.map(lambda x, y: (data_augmentation(x, training=True), y), num_parallel_calls=AUTOTUNE)
return ds
train_ds = prepare(train_ds)
完整实例(垃圾分类)
整体代码较长,顺着粘贴可能会存在问题,且结果一点点截图挺麻烦的,请移步垃圾分类实战链接
fork后可以之间下载,本地或者线上运行都可以,环境配置没问题,保证可以运行,觉得有用的话点个赞就好了