一文读懂Go函数调用
 导读|Go的函数调用时参数是通过栈传递还是寄存器传递?使用哪个版本的Go语言能让程序运行性能提升5%?腾讯后台开发工程师涂明光将带你由浅入深了解函数调用,并结合不同版本Go进行实操解答。
导读|Go的函数调用时参数是通过栈传递还是寄存器传递?使用哪个版本的Go语言能让程序运行性能提升5%?腾讯后台开发工程师涂明光将带你由浅入深了解函数调用,并结合不同版本Go进行实操解答。
 函数调用基本概念
函数调用基本概念
1)调用者caller与被调用者callee
如果一个函数调用另外一个函数,那么该函数被称为调用者函数,也叫做caller,而被调用的函数称为被调用者函数,也叫做callee。比如函数main中调用sum函数,那么main就是caller,而sum函数就是callee。
2)函数栈和函数栈帧
函数执行时需要有足够的内存空间,供它存放局部变量、参数等数据,这段空间对应到虚拟地址空间的栈,也即函数栈。在现代主流机器架构上(例如x86)中,栈都是向下生长的。栈的增长方向是从高位地址到地位地址向下进行增长。
分配给一个个函数的栈空间被称为“函数栈帧”。Go语言中函数栈帧布局是这样的:先是调用者caller栈基地址,然后是调用者函数caller的局部变量、接着是被调用函数callee的返回值和参数。然后是被调用者callee的栈帧。
注意,栈和栈帧是不一样的。在一个函数调用链中,比如函数A调用B,B调用C,则在函数栈上,A的栈帧在上面,下面依次是B、C的函数栈帧。Go1.17以前的版本,函数栈空间布局如下:

 函数调用分析
函数调用分析
通过在centos8上安装gvm,可以方便切换多个Go版本测试不同版本的特性。
gvm地址:https://github.com/moovweb/gvm
执行:
gvm list显示gvm安装的go版本列表:
gvm gos (installed)
go1.14.2
go1.15.14
go1.15.7
go1.16.1
go1.16.13
go1.17.1
go1.18
go1.18.1
system1)Go15版本函数调用分析
执行
gvm use go1.15.14切换到 go1.15.14版本,我们定义一个函数调用:
package main
func main() {
var r1, r2, r3, r4, r5, r6, r7 int64 = 1, 2, 3, 4, 5, 6, 7
A(r1, r2, r3, r4, r5, r6, r7)
}
func A(p1, p2, p3, p4, p5, p6, p7 int64) int64 {
return p1 + p2 + p3 + p4 + p5 + p6 + p7
}使用命令打印出main.go汇编:
GOOS=linux GOARCH=amd64 go tool compile -S -N -l main.go接下来我们分析main函数的汇编代码:
"".main STEXT size=190 args=0x0 locals=0x80
0x0000 00000 (main.go:3) TEXT "".main(SB), ABIInternal, $128-0 #main函数定义, $128-0:128表示将分配的main函数的栈帧大小;0指定了调用方传入的参数,由于main是最上层函数,这里没有入参
0x0000 00000 (main.go:3) MOVQ (TLS), CX # 将本地线程存储信息保存到CX寄存器中
0x0009 00009 (main.go:3) CMPQ SP, 16(CX) # 栈溢出检测:比较当前栈顶地址(SP寄存器存放的)与本地线程存储的栈顶地址
0x000d 00013 (main.go:3) PCDATA $0, $-2 # PCDATA,FUNCDATA用于Go汇编额外信息,不必关注
0x000d 00013 (main.go:3) JLS 180 # 如果当前栈顶地址(SP寄存器存放的)小于本地线程存储的栈顶地址,则跳到180处代码处进行栈分裂扩容操作
0x0013 00019 (main.go:3) PCDATA $0, $-1
0x0013 00019 (main.go:3) ADDQ $-128, SP # 为main函数栈帧分配了128字节的空间,注意此时的SP寄存器指向,会往下移动128个字节
0x0017 00023 (main.go:3) MOVQ BP, 120(SP) # BP寄存器存放的是main函数caller的基址,movq这条指令是将main函数caller的基址入栈。
0x001c 00028 (main.go:3) LEAQ 120(SP), BP # 将main函数的基址存放到到BP寄存器
0x0021 00033 (main.go:3) FUNCDATA $0, gclocals·33cdeccccebe80329f1fdbee7f5874cb(SB)
0x0021 00033 (main.go:3) FUNCDATA $1, gclocals·33cdeccccebe80329f1fdbee7f5874cb(SB)
0x0021 00033 (main.go:4) MOVQ $1, "".r1+112(SP) # main函数局部变量r1入栈
0x002a 00042 (main.go:4) MOVQ $2, "".r2+104(SP) # main函数局部变量r2入栈
0x0033 00051 (main.go:4) MOVQ $3, "".r3+96(SP) # main函数局部变量r3入栈
0x003c 00060 (main.go:4) MOVQ $4, "".r4+88(SP) # main函数局部变量r4入栈
0x0045 00069 (main.go:4) MOVQ $5, "".r5+80(SP) # main函数局部变量r5入栈
0x004e 00078 (main.go:4) MOVQ $6, "".r6+72(SP) # main函数局部变量r6入栈
0x0057 00087 (main.go:4) MOVQ $7, "".r7+64(SP) # main函数局部变量r7入栈
0x0060 00096 (main.go:5) MOVQ "".r1+112(SP), AX # 将局部变量r1传给寄存器AX
0x0065 00101 (main.go:5) MOVQ AX, (SP) # 寄存器AX将局部变量r1加入栈头SP指向的位置
0x0069 00105 (main.go:5) MOVQ "".r2+104(SP), AX # 将局部变量r2传给寄存器AX
0x006e 00110 (main.go:5) MOVQ AX, 8(SP) # 寄存器AX将局部变量r2加入栈头SP+8指向的位置
0x0073 00115 (main.go:5) MOVQ "".r3+96(SP), AX # 将局部变量r3传给寄存器AX
0x0078 00120 (main.go:5) MOVQ AX, 16(SP) # 寄存器AX将局部变量r3加入栈头SP+16指向的位置
0x007d 00125 (main.go:5) MOVQ "".r4+88(SP), AX # 将局部变量r4传给寄存器AX
0x0082 00130 (main.go:5) MOVQ AX, 24(SP) # 寄存器AX将局部变量r4加入栈头SP+24指向的位置
0x0087 00135 (main.go:5) MOVQ "".r5+80(SP), AX # 将局部变量r5传给寄存器AX
0x008c 00140 (main.go:5) MOVQ AX, 32(SP) # 寄存器AX将局部变量r4加入栈头SP+32指向的位置
0x0091 00145 (main.go:5) MOVQ "".r6+72(SP), AX # 将局部变量r6传给寄存器AX
0x0096 00150 (main.go:5) MOVQ AX, 40(SP) # 寄存器AX将局部变量r6加入栈头SP+40指向的位置
0x009b 00155 (main.go:5) MOVQ "".r7+64(SP), AX # 将局部变量r7传给寄存器AX
0x00a0 00160 (main.go:5) MOVQ AX, 48(SP) # 寄存器AX将局部变量r7加入栈头SP+48指向的位置
0x00a5 00165 (main.go:5) PCDATA $1, $0
0x00a5 00165 (main.go:5) CALL "".A(SB) # 调用 A函数
0x00aa 00170 (main.go:6) MOVQ 120(SP), BP # 将栈上存储的main函数的调用方的基地址恢复到BP
0x00af 00175 (main.go:6) SUBQ $-128, SP # 增加SP的值,栈收缩,收回分配给main函数栈帧的128字节空间
0x00b3 00179 (main.go:6) RET从汇编代码的注释中,我们可以清楚的看到,main函数调用A函数的局部变量、入参在栈中的存储位置。main函数通过 ADDQ $-128, SP 指令,一共在栈上分配了128字节的内存空间:
SP+64~SP+112 指向的56个栈空间,存储的是r1~r7这7个main函数的局部变量;SP+56 该地址接收函数A的返回值;SP~SP+48 指向的56个字节空间,用来存放A函数的 7 个入参。

综上,在Go1.15.14版本的函数调用中:参数完全通过栈传递;参数列表从右至左依次压栈。当程序准备好函数的入参之后,会调用汇编指令CALL "".A(SB),这个指令首先会将 main 的返回地址 (8 bytes) 存入栈中,然后改变当前的栈指针 SP 并执行 A 函数的汇编指令。栈空间变为:

下面分析 A 函数:
"".A STEXT nosplit size=50 args=0x40 locals=0x0
0x0000 00000 (main.go:8) TEXT "".A(SB), NOSPLIT|ABIInternal, $0-64 #A函数定义, $0-64:0表示将分配的A函数的栈帧大小;64指定了调用方传入的参数和函数的返回值的大小,入参7个,返回值1个,都是8字节,共64字节
0x0000 00000 (main.go:8) FUNCDATA $0, gclocals·33cdeccccebe80329f1fdbee7f5874cb(SB)
0x0000 00000 (main.go:8) FUNCDATA $1, gclocals·33cdeccccebe80329f1fdbee7f5874cb(SB)
0x0000 00000 (main.go:8) MOVQ $0, "".~r7+64(SP) # 这里 SP+64就是上面main栈空间中用来接收返回值的地址
0x0009 00009 (main.go:9) MOVQ "".p1+8(SP), AX # A返回值和r1参数求和后,放入AX寄存器
0x000e 00014 (main.go:9) ADDQ "".p2+16(SP), AX # AX寄存器的值再和r2参数求和,结果放入AX
0x0013 00019 (main.go:9) ADDQ "".p3+24(SP), AX # AX寄存器的值再和r3参数求和,结果放入AX
0x0018 00024 (main.go:9) ADDQ "".p4+32(SP), AX # AX寄存器的值再和r4参数求和,结果放入AX
0x001d 00029 (main.go:9) ADDQ "".p5+40(SP), AX # AX寄存器的值再和r5参数求和,结果放入AX
0x0022 00034 (main.go:9) ADDQ "".p6+48(SP), AX # AX寄存器的值再和r6参数求和,结果放入AX
0x0027 00039 (main.go:9) ADDQ "".p7+56(SP), AX # AX寄存器的值再和r7参数求和,结果放入AX
0x002c 00044 (main.go:9) MOVQ AX, "".~r7+64(SP) # AX寄存器的值 写回main栈空间中用来接收返回值的地址SP+64中
0x0031 00049 (main.go:9) RET需要注意的是,"".~r7+64(SP)是上图中,main函数用来接收A函数返回值的地址SP+56,因为CALL "".A(SB)将main返回地址压栈后,SP向下移动了8字节。

从A函数的汇编分析,可以得到结论:Go1.17.1之前版本,callee函数返回值通过caller栈传递;如果我们让main接收A函数的返回值,会发现callee的返回值也是通过caller的栈空间传递。
2)Go17版本函数调用分析
执行
gvm use go1.17.1切换到 go1.17.1版本,修改main.go代码结构如下:
package main
func main() {
var r1, r2, r3, r4, r5, r6, r7, r8, r9, r10, r11 int64 = 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11
a, b := A(r1, r2, r3, r4, r5, r6, r7, r8, r9, r10, r11)
c := a + b
print(c)
}
func A(p1, p2, p3, p4, p5, p6, p7, p8, p9, p10, p11 int64) (int64, int64) {
return p1 + p2 + p3 + p4 + p5 + p6 + p7, p2 + p4 + p6 + p7 + p8 + p9 + p10 + p11
}使用命令打印出main.go汇编:
GOOS=linux GOARCH=amd64 go tool compile -S -N -l main.go分析main函数的汇编代码:
"".main STEXT size=362 args=0x0 locals=0xe0 funcid=0x0
0x0000 00000 (main.go:3) TEXT "".main(SB), ABIInternal, $224-0 #main函数定义, $224-0:224表示将分配的main函数的栈帧大小;0指定了调用方传入的参数,由于main是最上层函数,这里没有入参
0x0000 00000 (main.go:3) LEAQ -96(SP), R12
0x0005 00005 (main.go:3) CMPQ R12, 16(R14)
0x0009 00009 (main.go:3) PCDATA $0, $-2
0x0009 00009 (main.go:3) JLS 349
0x000f 00015 (main.go:3) PCDATA $0, $-1
0x000f 00015 (main.go:3) SUBQ $224, SP # 为main函数栈帧分配了224字节的空间,注意此时的SP寄存器指向,会往下移动224个字节
0x0016 00022 (main.go:3) MOVQ BP, 216(SP) # BP寄存器存放的是main函数caller的基址,movq这条指令是将main函数caller的基址入栈
0x001e 00030 (main.go:3) LEAQ 216(SP), BP # 将main函数的基址存放到到BP寄存器
0x0026 00038 (main.go:3) FUNCDATA $0, gclocals·33cdeccccebe80329f1fdbee7f5874cb(SB)
0x0026 00038 (main.go:3) FUNCDATA $1, gclocals·33cdeccccebe80329f1fdbee7f5874cb(SB)
0x0026 00038 (main.go:4) MOVQ $1, "".r1+168(SP) # main函数局部变量r1入栈
0x0032 00050 (main.go:4) MOVQ $2, "".r2+144(SP) # main函数局部变量r2入栈
0x003e 00062 (main.go:4) MOVQ $3, "".r3+136(SP) # main函数局部变量r3入栈
0x004a 00074 (main.go:4) MOVQ $4, "".r4+128(SP) # main函数局部变量r4入栈
0x0056 00086 (main.go:4) MOVQ $5, "".r5+120(SP) # main函数局部变量r5入栈
0x005f 00095 (main.go:4) MOVQ $6, "".r6+112(SP) # main函数局部变量r6入栈
0x0068 00104 (main.go:4) MOVQ $7, "".r7+104(SP) # main函数局部变量r7入栈
0x0071 00113 (main.go:4) MOVQ $8, "".r8+96(SP) # main函数局部变量r8入栈
0x007a 00122 (main.go:4) MOVQ $9, "".r9+88(SP) # main函数局部变量r9入栈
0x0083 00131 (main.go:4) MOVQ $10, "".r10+160(SP) # main函数局部变量r10入栈
0x008f 00143 (main.go:4) MOVQ $11, "".r11+152(SP) # main函数局部变量r11入栈
0x009b 00155 (main.go:5) MOVQ "".r2+144(SP), BX # 将局部变量r2传给寄存器BX
0x00a3 00163 (main.go:5) MOVQ "".r3+136(SP), CX # 将局部变量r3传给寄存器CX
0x00ab 00171 (main.go:5) MOVQ "".r4+128(SP), DI # 将局部变量r4传给寄存器DI
0x00b3 00179 (main.go:5) MOVQ "".r5+120(SP), SI # 将局部变量r5传给寄存器SI
0x00b8 00184 (main.go:5) MOVQ "".r6+112(SP), R8 # 将局部变量r6传给寄存器R8
0x00bd 00189 (main.go:5) MOVQ "".r7+104(SP), R9 # 将局部变量r7传给寄存器R9
0x00c2 00194 (main.go:5) MOVQ "".r8+96(SP), R10 # 将局部变量r8传给寄存器R10
0x00c7 00199 (main.go:5) MOVQ "".r9+88(SP), R11 # 将局部变量r9传给寄存器R11
0x00cc 00204 (main.go:5) MOVQ "".r10+160(SP), DX # 将局部变量r10传给寄存器DX
0x00d4 00212 (main.go:5) MOVQ "".r1+168(SP), AX # 将局部变量r1传给寄存器DX
0x00dc 00220 (main.go:5) MOVQ DX, (SP) # 将寄存器DX保存的r10传给SP指向的栈顶
0x00e0 00224 (main.go:5) MOVQ $11, 8(SP) # 将变量r11传给SP+8
0x00e9 00233 (main.go:5) PCDATA $1, $0
0x00e9 00233 (main.go:5) CALL "".A(SB) # 调用 A 函数
0x00ee 00238 (main.go:5) MOVQ AX, ""..autotmp_14+208(SP) # 将寄存器AX存的函数A的第一个返回值a赋值给SP+208
0x00f6 00246 (main.go:5) MOVQ BX, ""..autotmp_15+200(SP) # 将寄存器BX存的函数A的第二个返回值b赋值给SP+200
0x00fe 00254 (main.go:5) MOVQ ""..autotmp_14+208(SP), DX # 将SP+208保存的A函数第一个返回值a传给寄存器DX
0x0106 00262 (main.go:5) MOVQ DX, "".a+192(SP) # 将A函数第一个返回值a通过寄存器DX入栈到SP+192
0x010e 00270 (main.go:5) MOVQ ""..autotmp_15+200(SP), DX # 将SP+200保存的A函数第二个返回值b传给寄存器DX
0x0116 00278 (main.go:5) MOVQ DX, "".b+184(SP) # 将第二个返回值b通过寄存器DX入栈到SP+184
0x011e 00286 (main.go:6) MOVQ "".a+192(SP), DX # 将返回值a传给DX寄存器
0x0126 00294 (main.go:6) ADDQ "".b+184(SP), DX # 将a+b赋值给DX寄存器
0x012e 00302 (main.go:6) MOVQ DX, "".c+176(SP) # 将DX寄存器的值入栈到SP+176
0x0136 00310 (main.go:7) CALL runtime.printlock(SB)
0x013b 00315 (main.go:7) MOVQ "".c+176(SP), AX # 将SP+176存储的入参c赋值给AX
0x0143 00323 (main.go:7) CALL runtime.printint(SB) # 调用打印函数打印c
0x0148 00328 (main.go:7) CALL runtime.printunlock(SB)
0x014d 00333 (main.go:8) MOVQ 216(SP), BP
0x0155 00341 (main.go:8) ADDQ $224, SP
0x015c 00348 (main.go:8) RET通过上面汇编代码的注释,我们可以看到:main函数调用A函数的参数个数为11个,其中前 9 个参数分别是通过寄存器 AX、BX、CX、DI、SI、R8、R9、R10、R11传递,后面两个通过栈顶的SP,SP+8地址传递。
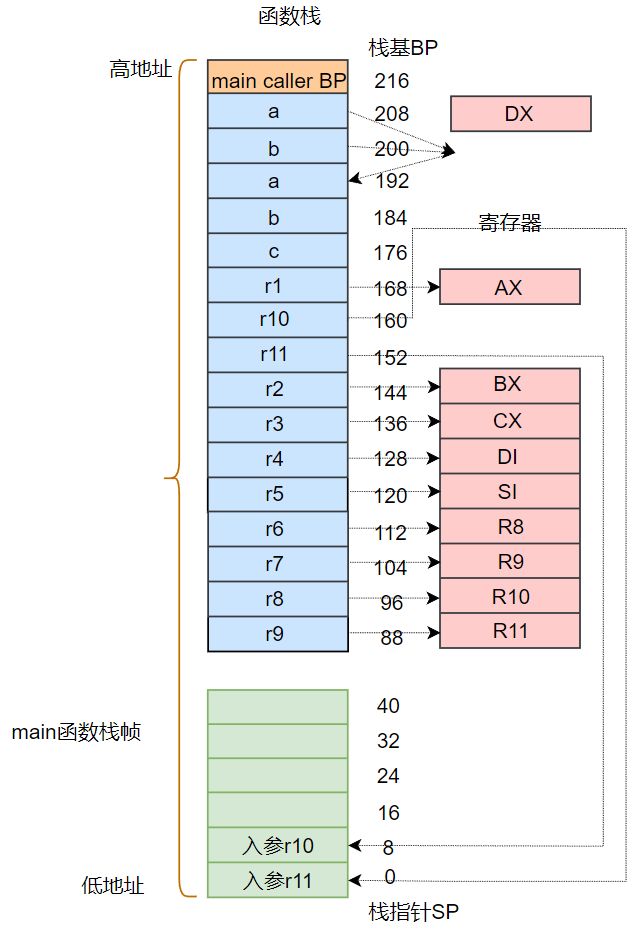
下面看 A 函数在Go1.17.1的汇编代码:
"".A STEXT nosplit size=175 args=0x58 locals=0x18 funcid=0x0
0x0000 00000 (main.go:10) TEXT "".A(SB), NOSPLIT|ABIInternal, $24-88
0x0000 00000 (main.go:10) SUBQ $24, SP # 为A函数栈帧分配了24字节的空间
0x0004 00004 (main.go:10) MOVQ BP, 16(SP)
0x0009 00009 (main.go:10) LEAQ 16(SP), BP
0x000e 00014 (main.go:10) FUNCDATA $0, gclocals·33cdeccccebe80329f1fdbee7f5874cb(SB)
0x000e 00014 (main.go:10) FUNCDATA $1, gclocals·33cdeccccebe80329f1fdbee7f5874cb(SB)
0x000e 00014 (main.go:10) FUNCDATA $5, "".A.arginfo1(SB)
0x000e 00014 (main.go:10) MOVQ AX, "".p1+48(SP) # 寄存器AX存储的r1赋值给SP+48
0x0013 00019 (main.go:10) MOVQ BX, "".p2+56(SP) # 寄存器BX存储的r2赋值给SP+56
0x0018 00024 (main.go:10) MOVQ CX, "".p3+64(SP) # 寄存器CX存储的r3赋值给SP+64
0x001d 00029 (main.go:10) MOVQ DI, "".p4+72(SP) # 寄存器DI存储的r4赋值给SP+72
0x0022 00034 (main.go:10) MOVQ SI, "".p5+80(SP) # 寄存器SI存储的r5赋值给SP+80
0x0027 00039 (main.go:10) MOVQ R8, "".p6+88(SP) # 寄存器R8存储的r6赋值给SP+88
0x002c 00044 (main.go:10) MOVQ R9, "".p7+96(SP) # 寄存器R9存储的r7赋值给SP+96
0x0031 00049 (main.go:10) MOVQ R10, "".p8+104(SP) # 寄存器R10存储的r8赋值给SP+104
0x0036 00054 (main.go:10) MOVQ R11, "".p9+112(SP) # 寄存器R11存储的r9赋值给SP+112
0x003b 00059 (main.go:10) MOVQ $0, "".~r11+8(SP) # 初始化第一个返回值a存放地址SP+8为0
0x0044 00068 (main.go:10) MOVQ $0, "".~r12(SP) # 初始化第二个返回值b存放地址SP为0
0x004c 00076 (main.go:11) MOVQ "".p1+48(SP), CX # SP+48存储的r1赋值给CX寄存器
0x0051 00081 (main.go:11) ADDQ "".p2+56(SP), CX # CX+r2赋值给CX寄存器
0x0056 00086 (main.go:11) ADDQ "".p3+64(SP), CX # CX+r3赋值给CX寄存器
0x005b 00091 (main.go:11) ADDQ "".p4+72(SP), CX # CX+r4赋值给CX寄存器
0x0060 00096 (main.go:11) ADDQ "".p5+80(SP), CX # CX+r5赋值给CX寄存器
0x0065 00101 (main.go:11) ADDQ "".p6+88(SP), CX # CX+r6赋值给CX寄存器
0x006a 00106 (main.go:11) ADDQ "".p7+96(SP), CX # CX+r7赋值给CX寄存器
0x006f 00111 (main.go:11) MOVQ CX, "".~r11+8(SP) # CX寄存器赋值给第一个返回值存放地址SP+8
0x0074 00116 (main.go:11) MOVQ "".p2+56(SP), BX # r2赋值给BX寄存器
0x0079 00121 (main.go:11) ADDQ "".p4+72(SP), BX # BX+r4赋值给BX寄存器
0x007e 00126 (main.go:11) ADDQ "".p6+88(SP), BX # BX+r6赋值给BX寄存器
0x0083 00131 (main.go:11) ADDQ "".p7+96(SP), BX # BX+r7赋值给BX寄存器
0x0088 00136 (main.go:11) ADDQ "".p8+104(SP), BX # BX+r8赋值给BX寄存器
0x008d 00141 (main.go:11) ADDQ "".p9+112(SP), BX # BX+r9赋值给BX寄存器
0x0092 00146 (main.go:11) ADDQ "".p10+32(SP), BX # BX+r11赋值给BX寄存器
0x0097 00151 (main.go:11) ADDQ "".p11+40(SP), BX # BX+r10赋值给BX寄存器
0x009c 00156 (main.go:11) MOVQ BX, "".~r12(SP) # BX寄存器赋值给第二个返回值存放地址SP
0x00a0 00160 (main.go:11) MOVQ "".~r11+8(SP), AX # 第一个返回值SP+8的值赋值给AX寄存器
0x00a5 00165 (main.go:11) MOVQ 16(SP), BP # main返回地址赋值给BP
0x00aa 00170 (main.go:11) ADDQ $24, SP # 回收A函数栈帧空间
0x00ae 00174 (main.go:11) RET在A函数栈中,我们可以看到:程序先把r1~r9参数分别从寄存器赋值到main栈帧的入参地址部分,即当前的SP+48~SP+112位。其实这跟GO1.15.14的函数调用参数传递过程差不多,只不过一个是在caller中做参数从寄存器拷贝到栈上,一个是在callee中做参数从寄存器拷贝到栈上。而且前者只使用了AX一个寄存器,后者使用了9个不同的寄存器。

很多开发者看到这里,估计会有一个疑问:Go1.15 与 Go1.17 在寄存器访问次数上和栈访问次数上,没有区别。只是寄存器上的参数拷贝到栈上的发生时机不同?那么为什么Go1.17会有较高的性能优势?
我们把打印汇编的命令GOOS=linux GOARCH=amd64 go tool compile -S -N -L main.go 中的-N -L禁用内联优化去掉(这才是性能对比的状态),我们再看,会发现Go17 的 A 函数会直接执行寄存器之间的加法,Go15版本的 A 函数不会。
对2.1节程序执行命令:
GOOS=linux GOARCH=amd64 go tool compile -S main.goGo1.15优化后的汇编代码是:
"".A STEXT nosplit size=59 args=0x40 locals=0x0
0x0000 00000 (main.go:8) TEXT "".A(SB), NOSPLIT|ABIInternal, $0-64
0x0000 00000 (main.go:8) FUNCDATA $0, gclocals·33cdeccccebe80329f1fdbee7f5874cb(SB)
0x0000 00000 (main.go:8) FUNCDATA $1, gclocals·33cdeccccebe80329f1fdbee7f5874cb(SB)
0x0000 00000 (main.go:9) MOVQ "".p1+8(SP), AX #参数从栈赋值到寄存器AX
0x0005 00005 (main.go:9) MOVQ "".p2+16(SP), CX #参数从栈赋值到寄存器CX
0x000a 00010 (main.go:9) ADDQ CX, AX
0x000d 00013 (main.go:9) MOVQ "".p3+24(SP), CX #参数从栈赋值到寄存器CX
0x0012 00018 (main.go:9) ADDQ CX, AX
0x0015 00021 (main.go:9) MOVQ "".p4+32(SP), CX
0x001a 00026 (main.go:9) ADDQ CX, AX
0x001d 00029 (main.go:9) MOVQ "".p5+40(SP), CX
0x0022 00034 (main.go:9) ADDQ CX, AX
0x0025 00037 (main.go:9) MOVQ "".p6+48(SP), CX
0x002a 00042 (main.go:9) ADDQ CX, AX
0x002d 00045 (main.go:9) MOVQ "".p7+56(SP), CX
0x0032 00050 (main.go:9) ADDQ CX, AX
0x0035 00053 (main.go:9) MOVQ AX, "".~r7+64(SP)
0x003a 00058 (main.go:9) RETgvm 切换到Go1.17.1版本。对2.1节程序执行命令:
GOOS=linux GOARCH=amd64 go tool compile -S main.goGo1.17优化后的汇编代码是:
"".A STEXT nosplit size=21 args=0x38 locals=0x0 funcid=0x0
0x0000 00000 (main.go:8) TEXT "".A(SB), NOSPLIT|ABIInternal, $0-56
0x0000 00000 (main.go:8) FUNCDATA $0, gclocals·33cdeccccebe80329f1fdbee7f5874cb(SB)
0x0000 00000 (main.go:8) FUNCDATA $1, gclocals·33cdeccccebe80329f1fdbee7f5874cb(SB)
0x0000 00000 (main.go:8) FUNCDATA $5, "".A.arginfo1(SB)
0x0000 00000 (main.go:9) LEAQ (BX)(AX*1), DX
0x0004 00004 (main.go:9) ADDQ DX, CX #直接在寄存器之间做加法
0x0007 00007 (main.go:9) ADDQ DI, CX #直接在寄存器之间做加法
0x000a 00010 (main.go:9) ADDQ SI, CX
0x000d 00013 (main.go:9) ADDQ R8, CX
0x0010 00016 (main.go:9) LEAQ (R9)(CX*1), AX
0x0014 00020 (main.go:9) RET对比发现:寄存器传参和栈传参,在编译器实际优化后的执行代码中,前者直接会在寄存器之间做加法,后者多了从栈拷贝数据到寄存器到动作,因此前者效率更高。
通过分析Go1.17.1函数调用过程,我们发现:
参数传递使用了多个寄存器,并且被调用方callee的返回值由callee本身的栈帧负责存放,而不是放在caller的栈帧上;当callee的栈帧被销毁时,其返回值通过AX,BX等寄存器传递给调用方caller。
9个以内的参数通过寄存器传递,9个以外的通过栈传递。如果将 A 函数的返回值个数设置大于9个,同样会发现,9个以内的返回值通过寄存器传递,9个以外的通过栈传递。

为何高版本Go要改用寄存器传参?
至于为什么Go1.17.1函数调用的参数传递开始基于寄存器进行传递,原因无外乎。
第一,CPU访问寄存器比访问栈要快的多。函数调用通过寄存器传参比栈传参,性能要高5%。
第二,早期Go版本为了降低实现的复杂度,统一使用栈传递参数和返回值,不惜牺牲函数调用的性能。
第三,Go从1.17.1版本,开始支持多ABI(application binary interface 应用程序二进制接口,规定了程序在机器层面的操作规范,主要包括调用规约calling convention),主要是两个ABI:一个是老版本Go采用的平台通用ABI0,一个是Go独特的ABIInternal,前者遵循平台通用的函数调用约定,实现简单,不用担心底层cpu架构寄存器的差异;后者可以指定特定的函数调用规范,可以针对特定性能瓶颈进行优化,在多个Go版本之间可以迭代,灵活性强,支持寄存器传参提升性能。
所谓“调用规约(calling convention)”是调用方和被调用方对于函数调用的一个明确的约定,包括:函数参数与返回值的传递方式、传递顺序。只有双方都遵守同样的约定,函数才能被正确地调用和执行。如果不遵守这个约定,函数将无法正确执行。

总结
综合上面的分析,我们得出结论:
Go1.17.1之前的函数调用,参数都在栈上传递;Go1.17.1以后,9个以内的参数在寄存器传递,9个以外的在栈上传递;Go1.17.1之前版本,callee函数返回值通过caller栈传递;Go1.17.1以后,函数调用的返回值,9个以内通过寄存器传递回caller,9个以外在栈上传递。
在Go 1.17的版本发布说明文档中有提到:切换到基于寄存器的调用惯例后,一组有代表性的Go包和程序的基准测试显示,Go程序的运行性能提高了约5%,二进制文件大小减少约2%。
由于CPU访问寄存器的速度要远高于栈内存,参数在栈上传递会增加栈内存空间,并且影响栈的扩缩容和垃圾回收,改为寄存器传递,这些缺点都得到了优化,Go程序在从低版本升级到17版本后,性能有一定的提升。在业务允许的情况下,这里建议各位开发者可以把自己程序的Go版本升级到17及以上。
后台回复“GO117”获得作者推荐GO相关作品
腾讯工程师技术干货直达:
1、H5开屏从龟速到闪电,企微是如何做到的
2、全网首次揭秘:微秒级“复活”网络的HARP协议及其关键技术
3、闰秒终于要取消了!一文详解其来源及影响
4、万字避坑指南!C++的缺陷与思考(下)
![]()
![]()
点个 在看展示你的技术态度
![]()