语义分割系列24-PointRend(pytorch实现)
PointRend: Image Segmentation as Rendering
论文链接:PointRend

本文将介绍:
- PointRend的原理
- PointRend代码实现
- PointRend在Camvid数据集上进行复现
目录
- 引文
- PointRend 思路
-
- 整体思路和PointRend实现步骤
- PointRend点选择策略
-
- 对于Inference过程
- 对于Train过程
- PointRend效果
- PointRend的一些代码和实现
-
- 点采样策略代码
- ResNet+DeepLabv3 + PointRend实现代码
- 在Camvid数据集上测试
-
- 结果
引文
PointRend是何凯明团队发在2020年CVPR上的作品,何凯明出品,必属精品。
看到这篇论文的第一眼,还是很惊艳的。再读下去,发现还十分有趣。
PointRend的思想其实并不复杂,但是却很新颖,原因是将渲染领域的操作引入到分割领域(不管是实例分割还是语义分割)。PointRend本身可以理解为一个新颖的上采样操作。
在图像分割问题中,边缘的恢复\精确分割是比较麻烦的问题。在比较经典的一些语义分割模型中,无论是FCN、DeepLab还是PSPNet,在模型后都是接一个8倍或4倍的上采样操作来恢复图像,这对于物体边缘的预测自然是不利的,上采样会损失一些边缘信息。
因此呢,PointRend其实就是为上采样过程中精确恢复物体边缘的任务而生。
PointRend 思路
整体思路和PointRend实现步骤
首先先看整体的结构图:
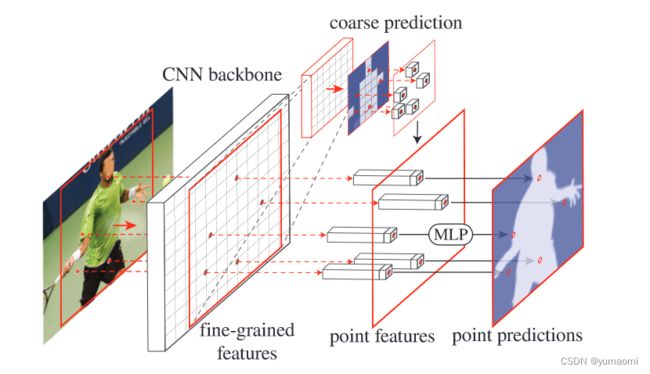
- 从PointRend的应用思路中可以看到,这里包含了两个阶段的特征处理,分别是fine-grained features和coarse prediction部分,如果主干网络是ResNet,那么fine-grained features就是ResNet的stage2输出,也就是4倍下采样时的精细分割结果,而coarse prediction就是检测头的预测结果(还未上采样还原成原图的结果)。
- 从coarse prediction中挑选N个“难点”,也就是结果很有可能和周围点不一样的点(比如物体边缘的点)。
对于每一个难点,获取他的“特征向量”,对于点特征向量(point features),主要由两部分组成,分别是fine-grained features的对应点和coarse prediction的对应点的特征向量,将这个两个特征向量拼接成一个向量。 - 接着,通过一个MLP网络对这个“特征向量”进行预测,更新coarse prediction。也就相当于对这个难点进行新的预测,对他进行分类。
看完这个,我们就可以这么理解,将预测难的点(边缘点)提取出来,再提取其特征向量,经过MLP网络,将这个点的归属进行分类,然后提升这些点的分类准确率。这就是PointRend的思想。
我们再看细节部分的实现图:
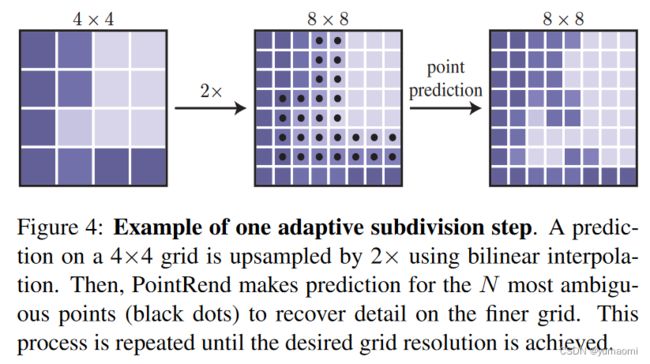
对于一个coarse prediction(4x4大小),将其上采样两倍(8x8大小,这里可以理解为检测头的输出)后,取了一些难分割的点(大多是边缘部分),取这些点的特征向量输入到MLP网络中,进行point prediction,得到每一个点的新类别,最后结果输出(8x8大小,边缘更加精确的结果)。
PointRend点选择策略
再了解了PointRend实现目标和总体思路后,我们还需对其细节做进一步了解。
既然PointRend是基于点的预测,那么这些点该如何采样?这将是一个问题,如果对全局点进行采样,那么计算量就过于大了。如果只想对预测困难点(物体边界)进行采样,那么这个采样该如何实现?带着这个问题,我们往下看。
对于点采样过程,需要对模型的Train过程和Inference过程做区分。
对于Inference过程
在Inference过程中,每个区域都通过迭代coarse-to-fine的方式来渲染。在每一次迭代过程中,PointRend都使用双线性差值将上一次的segmentation result进行上采样,然后在这个结果中选择N个不确定的点(分类概率接近0.5的点,也就是模型认为模棱两可的点)。这样就等于有目的的选到了N个分割困难的点,然后提取特征向量,经过MLP进行分类,得到新的segmentation result。
然后再上采样->提取点->MLP point prediction->…, 重复这个步骤,直到完成预测。这就是迭代coarse-to-fine的操作,也就是上图中figure 4的内容。
对于Train过程
对于Train过程的点采样操作,同样可以遵循Inference中的操作。但是作者发现,这样子采样对于梯度的传播不太友好,于是只能被迫选择其他的点采样策略——干脆就用随机采样的方式来进行采样。
- 首先依据均匀分布随机取kN个点(k>1)
- 然后上采样后,预测估计这些点的结果,再从kN个点中选取βN个点(0<β<1)
作者还选了几种采样方式,具体效果看下图。

PointRend效果
不管如何,PointRend对于物体的边缘恢复效果是很不错的,而且很灵活,可以作为上采样操作放置在很多网络之中,用来涨点。


PointRend的一些代码和实现
下面提供一些PointRend的代码(来自官方),以及在Camvid数据集上的测试代码。
点采样策略代码
import torch
import torch.nn.functional as F
def point_sample(input, point_coords, **kwargs):
add_dim = False
if point_coords.dim() == 3:
add_dim = True
point_coords = point_coords.unsqueeze(2)
output = F.grid_sample(input, 2.0 * point_coords - 1.0, **kwargs)
if add_dim:
output = output.squeeze(3)
return output
@torch.no_grad()
def sampling_points(mask, N, k=3, beta=0.75, training=True):
assert mask.dim() == 4, "Dim must be N(Batch)CHW"
device = mask.device
B, _, H, W = mask.shape
mask, _ = mask.sort(1, descending=True)
if not training:
H_step, W_step = 1 / H, 1 / W
N = min(H * W, N)
uncertainty_map = -1 * (mask[:, 0] - mask[:, 1])
_, idx = uncertainty_map.view(B, -1).topk(N, dim=1)
points = torch.zeros(B, N, 2, dtype=torch.float, device=device)
points[:, :, 0] = W_step / 2.0 + (idx % W).to(torch.float) * W_step
points[:, :, 1] = H_step / 2.0 + (idx // W).to(torch.float) * H_step
return idx, points
over_generation = torch.rand(B, k * N, 2, device=device)
over_generation_map = point_sample(mask, over_generation, align_corners=False)
uncertainty_map = -1 * (over_generation_map[:, 0] - over_generation_map[:, 1])
_, idx = uncertainty_map.topk(int(beta * N), -1)
shift = (k * N) * torch.arange(B, dtype=torch.long, device=device)
idx += shift[:, None]
importance = over_generation.view(-1, 2)[idx.view(-1), :].view(B, int(beta * N), 2)
coverage = torch.rand(B, N - int(beta * N), 2, device=device)
return torch.cat([importance, coverage], 1).to(device)
ResNet+DeepLabv3 + PointRend实现代码
from torchvision.models._utils import IntermediateLayerGetter
from torchvision.models.segmentation._utils import _SimpleSegmentationModel
from torchvision.models.segmentation.deeplabv3 import DeepLabHead
from torchvision.models import resnet50, resnet101
import torch.nn as nn
from torchvision.models.resnet import ResNet, Bottleneck
class ResNetXX3(ResNet):
def __init__(self, block, layers, num_classes=1000, zero_init_residual=False,
groups=1, width_per_group=64, replace_stride_with_dilation=None,
norm_layer=None):
super().__init__(block, layers, num_classes, zero_init_residual,
groups, width_per_group, replace_stride_with_dilation,
norm_layer)
self.conv1 = nn.Conv2d(3, 64, 3, 1, 1, bias=False)
nn.init.kaiming_normal_(self.conv1.weight, mode='fan_out', nonlinearity='relu')
def resnet53(pretrained=False, progress=True, **kwargs):
r"""ResNet-50 model from
`"Deep Residual Learning for Image Recognition" `_
Args:
pretrained (bool): If True, returns a model pre-trained on ImageNet
progress (bool): If True, displays a progress bar of the download to stderr
"""
return ResNetXX3(Bottleneck, [3, 4, 6, 3], **kwargs)
def resnet103(pretrained=False, progress=True, **kwargs):
return ResNetXX3(Bottleneck, [3, 4, 23, 3], **kwargs)
class SmallDeepLab(_SimpleSegmentationModel):
def forward(self, input_):
result = self.backbone(input_)
result["coarse"] = self.classifier(result["out"])
return result
def deeplabv3(pretrained=False, resnet="res101", head_in_ch=2048, num_classes=21):
resnet = {
"res53": resnet53,
"res103": resnet103,
"res50": resnet50,
"res101": resnet101
}[resnet]
net = SmallDeepLab(
backbone=IntermediateLayerGetter(
resnet(pretrained=False, replace_stride_with_dilation=[False, True, True]),
return_layers={'layer2': 'res2', 'layer4': 'out'}
),
classifier=DeepLabHead(head_in_ch, num_classes)
)
return net
if __name__ == "__main__":
import torch
x = torch.randn(3, 3, 224, 224).cuda()
net = deeplabv3(False,num_classes=33).cuda()
result = net(x)
for k, v in result.items():
print(k, v.shape)
import torch
import torch.nn as nn
import torch.nn.functional as F
class PointHead(nn.Module):
def __init__(self,num_classes, in_c=512, k=3, beta=0.75):
super().__init__()
self.mlp = nn.Conv1d(in_c+num_classes, num_classes, 1)
self.k = k
self.beta = beta
def forward(self, x, res2, out):
"""
1. Fine-grained features are interpolated from res2 for DeeplabV3
2. During training we sample as many points as there are on a stride 16 feature map of the input
3. To measure prediction uncertainty
we use the same strategy during training and inference: the difference between the most
confident and second most confident class probabilities.
"""
if not self.training:
return self.inference(x, res2, out)
points = sampling_points(out, x.shape[-1] // 16, self.k, self.beta)
coarse = point_sample(out, points, align_corners=False)
fine = point_sample(res2, points, align_corners=False)
feature_representation = torch.cat([coarse, fine], dim=1)
rend = self.mlp(feature_representation)
return {"rend": rend, "points": points}
@torch.no_grad()
def inference(self, x, res2, out):
"""
During inference, subdivision uses N=8096
(i.e., the number of points in the stride 16 map of a 1024×2048 image)
"""
num_points = 8096
while out.shape[-1] != x.shape[-1]:
out = F.interpolate(out, scale_factor=2, mode="bilinear", align_corners=True)
points_idx, points = sampling_points(out, num_points, training=self.training)
coarse = point_sample(out, points, align_corners=False)
fine = point_sample(res2, points, align_corners=False)
feature_representation = torch.cat([coarse, fine], dim=1)
rend = self.mlp(feature_representation)
B, C, H, W = out.shape
points_idx = points_idx.unsqueeze(1).expand(-1, C, -1)
out = (out.reshape(B, C, -1).scatter_(2, points_idx, rend).view(B, C, H, W))
return {"fine": out}
class PointRend(nn.Module):
def __init__(self, backbone, head):
super().__init__()
self.backbone = backbone
self.head = head
def forward(self, x):
result = self.backbone(x)
result.update(self.head(x, result["res2"], result["coarse"]))
return result
if __name__ == "__main__":
x = torch.randn(3, 3, 224, 224)
net = PointRend(deeplabv3(False,num_classes=33), PointHead(num_classes=33))
out = net(x)
for k, v in out.items():
print(k, v.shape)
在Camvid数据集上测试
# 导入库
import os
os.environ['CUDA_VISIBLE_DEVICES'] = '0'
os.environ["KMP_DUPLICATE_LIB_OK"]="TRUE"
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch.utils.data import DataLoader
import warnings
warnings.filterwarnings("ignore")
from PIL import Image
import numpy as np
import albumentations as A
from albumentations.pytorch.transforms import ToTensorV2
torch.manual_seed(17)
# 自定义数据集CamVidDataset
class CamVidDataset(torch.utils.data.Dataset):
"""CamVid Dataset. Read images, apply augmentation and preprocessing transformations.
Args:
images_dir (str): path to images folder
masks_dir (str): path to segmentation masks folder
class_values (list): values of classes to extract from segmentation mask
augmentation (albumentations.Compose): data transfromation pipeline
(e.g. flip, scale, etc.)
preprocessing (albumentations.Compose): data preprocessing
(e.g. noralization, shape manipulation, etc.)
"""
def __init__(self, images_dir, masks_dir):
self.transform = A.Compose([
A.Resize(224, 224),
A.HorizontalFlip(),
A.VerticalFlip(),
A.Normalize(),
ToTensorV2(),
])
self.ids = os.listdir(images_dir)
self.images_fps = [os.path.join(images_dir, image_id) for image_id in self.ids]
self.masks_fps = [os.path.join(masks_dir, image_id) for image_id in self.ids]
def __getitem__(self, i):
# read data
image = np.array(Image.open(self.images_fps[i]).convert('RGB'))
mask = np.array( Image.open(self.masks_fps[i]).convert('RGB'))
image = self.transform(image=image,mask=mask)
return image['image'], image['mask'][:,:,0]
def __len__(self):
return len(self.ids)
# 设置数据集路径
DATA_DIR = r'database/camvid/camvid/' # 根据自己的路径来设置
x_train_dir = os.path.join(DATA_DIR, 'train_images')
y_train_dir = os.path.join(DATA_DIR, 'train_labels')
x_valid_dir = os.path.join(DATA_DIR, 'valid_images')
y_valid_dir = os.path.join(DATA_DIR, 'valid_labels')
train_dataset = CamVidDataset(
x_train_dir,
y_train_dir,
)
val_dataset = CamVidDataset(
x_valid_dir,
y_valid_dir,
)
train_loader = DataLoader(train_dataset, batch_size=8, shuffle=True,drop_last=True)
val_loader = DataLoader(val_dataset, batch_size=8, shuffle=True,drop_last=True)
model = PointRend(deeplabv3(False, num_classes=33), PointHead(num_classes=33)).cuda()
from d2l import torch as d2l
from tqdm import tqdm
import pandas as pd
import monai
# training loop 100 epochs
epochs_num = 100
# 选用SGD优化器来训练
optimizer = torch.optim.SGD(model.parameters(), lr=0.1)
schedule = monai.optimizers.LinearLR(optimizer, end_lr=0.05, num_iter=int(epochs_num*0.75))
# 损失函数选用多分类交叉熵损失函数
lossf = nn.CrossEntropyLoss(ignore_index=255)
def evaluate_accuracy_gpu(net, data_iter, device=None):
if isinstance(net, nn.Module):
net.eval() # Set the model to evaluation mode
if not device:
device = next(iter(net.parameters())).device
# No. of correct predictions, no. of predictions
metric = d2l.Accumulator(2)
with torch.no_grad():
for X, y in data_iter:
if isinstance(X, list):
# Required for BERT Fine-tuning (to be covered later)
X = [x.to(device) for x in X]
else:
X = X.to(device)
y = y.to(device)
output = net(X)
pred = F.interpolate(output["coarse"], X.shape[-2:], mode="bilinear", align_corners=True)
metric.add(d2l.accuracy(pred, y), d2l.size(y))
return metric[0] / metric[1]
# 训练函数
def train_ch13(net, train_iter, test_iter, loss, optimizer, num_epochs, schedule, swa_start=swa_start, devices=d2l.try_all_gpus()):
timer, num_batches = d2l.Timer(), len(train_iter)
animator = d2l.Animator(xlabel='epoch', xlim=[1, num_epochs], ylim=[0, 1], legend=['train loss', 'train acc', 'test acc'])
net = nn.DataParallel(net, device_ids=devices).to(devices[0])
# 用来保存一些训练参数
loss_list = []
train_acc_list = []
test_acc_list = []
epochs_list = []
time_list = []
lr_list = []
for epoch in range(num_epochs):
# Sum of training loss, sum of training accuracy, no. of examples,
# no. of predictions
metric = d2l.Accumulator(4)
for i, (X, labels) in enumerate(train_iter):
timer.start()
if isinstance(X, list):
X = [x.to(devices[0]) for x in X]
else:
X = X.to(devices[0])
# y = labels.long().to(devices[0])
gt = labels.squeeze_(1).to(devices[0], dtype=torch.long, non_blocking=True)
net.train()
optimizer.zero_grad()
result = net(X)
pred = F.interpolate(result["coarse"], X.shape[-2:], mode="bilinear", align_corners=True)
seg_loss = F.cross_entropy(pred, gt, ignore_index=255)
gt_points = point_sample(
gt.float().unsqueeze(1),
result["points"],
mode="nearest",
align_corners=False
).squeeze_(1).long()
points_loss = F.cross_entropy(result["rend"], gt_points, ignore_index=255)
loss_sum = seg_loss + points_loss
l = loss_sum
loss_sum.sum().backward()
optimizer.step()
acc = d2l.accuracy(pred, gt)
metric.add(l, acc, labels.shape[0], labels.numel())
timer.stop()
if (i + 1) % (num_batches // 5) == 0 or i == num_batches - 1:
animator.add(epoch + (i + 1) / num_batches,(metric[0] / metric[2], metric[1] / metric[3], None))
if optimizer.state_dict()['param_groups'][0]['lr']>0.05:
schedule.step()
test_acc = evaluate_accuracy_gpu(net, test_iter)
animator.add(epoch + 1, (None, None, test_acc))
print(f"epoch {epoch+1}/{epochs_num} --- loss {metric[0] / metric[2]:.3f} --- train acc {metric[1] / metric[3]:.3f} --- test acc {test_acc:.3f} --- lr {optimizer.state_dict()['param_groups'][0]['lr']} --- cost time {timer.sum()}")
#---------保存训练数据---------------
df = pd.DataFrame()
loss_list.append(metric[0] / metric[2])
train_acc_list.append(metric[1] / metric[3])
test_acc_list.append(test_acc)
epochs_list.append(epoch+1)
time_list.append(timer.sum())
lr_list.append(optimizer.state_dict()['param_groups'][0]['lr'])
df['epoch'] = epochs_list
df['loss'] = loss_list
df['train_acc'] = train_acc_list
df['test_acc'] = test_acc_list
df["lr"] = lr_list
df['time'] = time_list
df.to_excel("savefile/PointRend_camvid.xlsx")
#----------------保存模型-------------------
if np.mod(epoch+1, 5) == 0:
torch.save(net.state_dict(), f'checkpoints/PointRend_{epoch+1}.pth')
# 保存下最后的model
torch.save(net.state_dict(), f'checkpoints/PointRend_last.pth')
train_ch13(model, train_loader, val_loader, lossf, optimizer, epochs_num, schedule=schedule)
结果
