c# 字典Dictionary
作者:曾志伟
链接:https://zhuanlan.zhihu.com/p/96633352
来源:知乎
C# 用了两三年,然后突然有一天被问到C#Dictionary的基本实现,这让我反思到我一直处于拿来主义,能用就好,根本没有去考虑和学习一些底层架构,想想令人头皮发麻。下面开始学习一些我平时用得理所当然的东西,今天先学习一下字典的源码。
一、Dictionary源码学习
Dictionary实现我们主要对照源码来解析,目前对照源码的版本是 .Net Framwork 4.8。
源码地址: dictionary.cs
这边主要介绍Dictionary中几个比较关键的类和对象
然后跟着代码来走一遍插入、删除和扩容的流程
1. Entry结构体
首先我们引入Entry这样一个结构体,它的定义如下代码所示。这是Dictionary种存放数据的最小单位,调用Add(Key,Value)方法添加的元素都会被封装在这样的一个结构体中。
private struct Entry {
public int hashCode; // Lower 31 bits of hash code, -1 if unused
public int next; // Index of next entry, -1 if last
public TKey key; // Key of entry
public TValue value; // Value of entry
}
2. 其它关键私有变量
private int[] buckets; // Hash桶
private Entry[] entries; // Entry数组,存放元素
private int count; // 当前entries的index位置
private int version; // 当前版本,防止迭代过程中集合被更改
private int freeList; // 被删除Entry在entries中的下标index,这个位置是空闲的
private int freeCount; // 有多少个被删除的Entry,有多少个空闲的位置
private IEqualityComparer comparer; // 比较器
private KeyCollection keys; // 存放Key的集合
private ValueCollection values; // 存放Value的集合
3. Dictionary的构造
private void Initialize(int capacity)
{
int prime = HashHelpers.GetPrime(capacity);
this.buckets = new int[prime];
for (int i = 0; i < this.buckets.Length; i++)
{
this.buckets[i] = -1;
}
this.entries = new Entry[prime];
this.freeList = -1;
}
我们看到,Dictionary在构造的时候做了以下几件事:
- 初始化一个this.buckets = new int[prime]
- 初始化一个this.entries = new Entry
- Bucket和entries的容量都为大于字典容量的一个最小的质数
其中this.buckets主要用来进行Hash碰撞,this.entries用来存储字典的内容,并且标识下一个元素的位置。
4. Dictionary – Add操作
public void Add(TKey key, TValue value) {
Insert(key, value, true);
}
int targetBucket = hashCode % buckets.Length;
我们以Dictionary
首先,我们构造一个字典,然后Bucket和entries的容量都为大于字典容量的一个最小的质数7:
Dictionary test = new Dictionary(6);
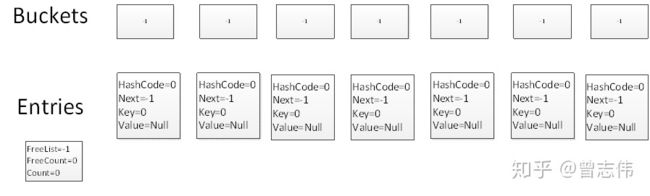
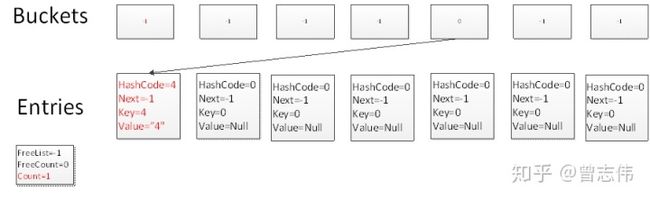
Test.Add(4,"4")
根据Hash算法: int targetBucket = hashCode % buckets.Length; buckets.Length等于7,4.GetHashCode()%7= 4,因此碰撞到buckets中下标为4的槽上,此时由于Count为0,因此元素放在Entries中第0个元素上,添加后Count变为1
Test.Add(11,"11")
根据Hash算法 11.GetHashCode()%7=4,因此再次碰撞到Buckets中下标为4的槽上,由于此槽上的值已经不为-1,此时Count=1,因此把这个新加的元素放到entries中下标为1的数组中,并且让Buckets槽指向下标为1的entries中,下标为1的entry之下下标为0的entries。

Test.Add(18,"18")
Test.Add(19,"19")
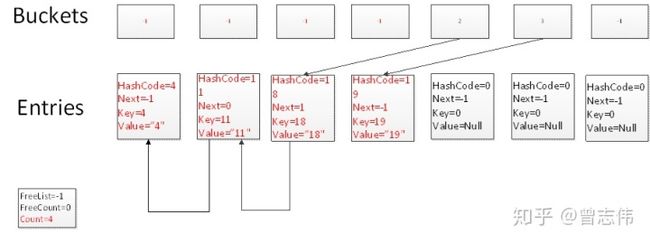
5. Dictionary – Remove操作
Test.Remove(4)
我们删除元素时,通过一次碰撞,并且沿着链表寻找3次,找到key为4的元素所在的位置,删除当前元素。并且把FreeList的位置指向当前删除元素的位置,FreeCount置为1
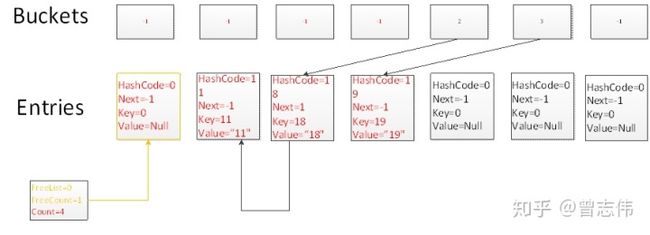
删除的数据会形成一个FreeList的链表,添加数据的时候,优先向FreeList链表中添加数据,FreeList为空则按照count依次排列
6. Dictionary – Resize操作(扩容)
有细心的小伙伴可能看过了Add操作以后就想问了,buckets、entries不就是两个数组么,那万一数组放满了怎么办?接下来就是我所要介绍的Resize(扩容)这样一种操作,对我们的buckets、entries进行扩容。
6.1 扩容操作的触发条件
首先我们需要知道在什么情况下,会发生扩容操作;
第一种情况自然就是数组已经满了,没有办法继续存放新的元素。如下图所示的情况。
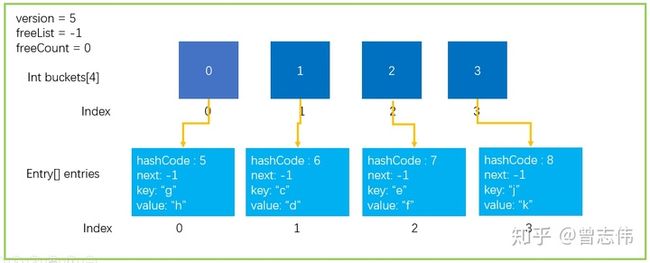
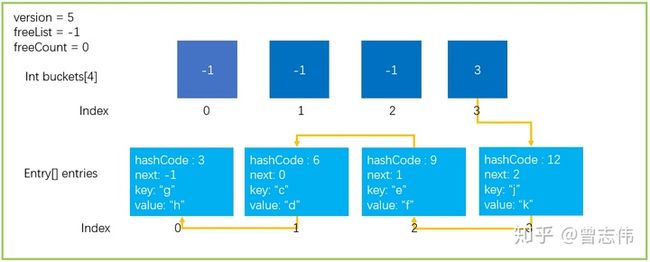
第二种,Dictionary中发生的碰撞次数太多,会严重影响性能,也会触发扩容操作。
Hash运算会不可避免的产生冲突,Dictionary中使用拉链法来解决冲突的问题,但是大家看下图中的这种情况。所有的元素都刚好落在buckets[3]上面,结果就是导致了时间复杂度O(n),查找性能会下降;
6.2 扩容操作如何进行
为了给大家演示的清楚,模拟了以下这种数据结构,大小为2的Dictionary,假设碰撞的阈值为2;现在触发Hash碰撞扩容。
- 1、申请两倍于现在大小的buckets、entries
- 2、将现有的元素拷贝到新的entries
- 3、如果是Hash碰撞扩容,使用新HashCode函数重新计算Hash值
- 4、对entries每个元素bucket = newEntries[i].hashCode % newSize确定新buckets位置
- 5、重建hash链,newEntries[i].next=buckets[bucket]; buckets[bucket]=i;
关注点
对于Dictionary的实现原理,其中有两个关键的算法,
- 一个是Hash算法,
- 一个是用于应对Hash碰撞冲突解决算法。
二、Hash算法
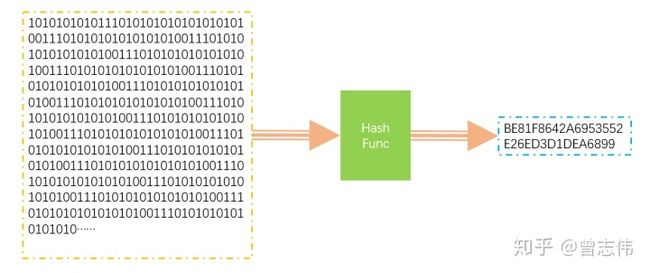
Hash算法是一种 数字摘要算法,它能将不定长度的 二进制数据集给 映射到一个较短的二进制长度数据集。
实现了Hash算法的函数我们叫她Hash函数。Hash函数有以下几点特征。
相同的数据进行Hash运算,得到的结果一定相同。HashFunc(key1) == HashFunc(key1)
不同的数据进行Hash运算,其结果也可能会相同,( Hash会产生碰撞)。key1 != key2 => HashFunc(key1) == HashFunc(key2).
Hash运算时不可逆的,不能由key获取原始的数据。key1 => hashCode但是hashCode ==> key1。
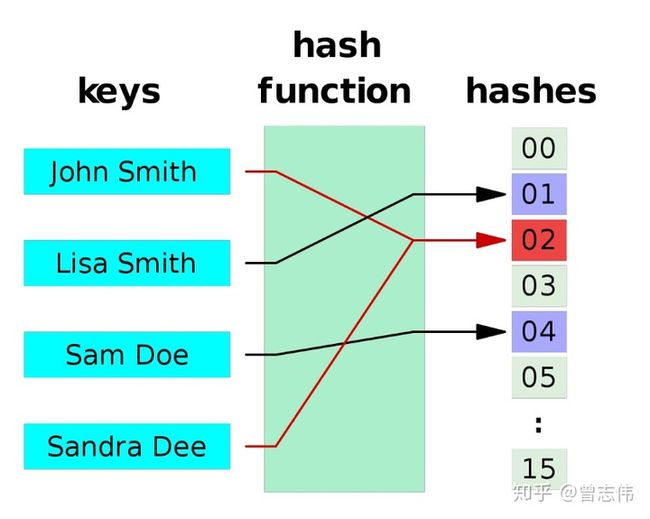
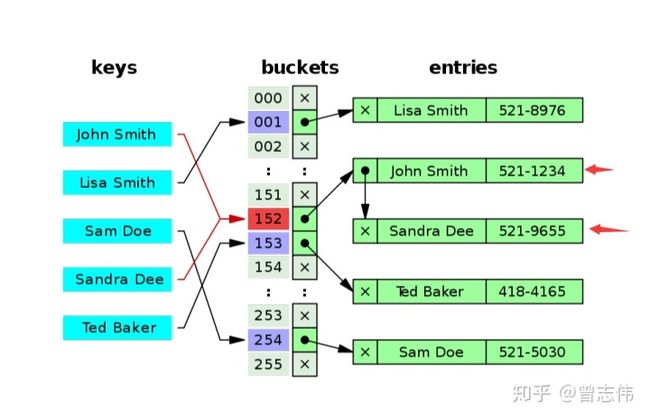
关于Hash碰撞下图很清晰的就解释了,可从图中得知Sandra Dee 和 John Smith通过hash运算后都落到了02的位置,产生了碰撞和冲突。
常见的构造Hash函数的算法有以下几种。
- 1. 直接寻址法:取keyword或keyword的某个线性函数值为散列地址。即H(key)=key或H(key) = a•key + b,当中a和b为常数(这样的散列函数叫做自身函数),
这个的应用就是,比如我们世界地图的掩码,直接用坐标x * 1000 + 坐标y,得到key。
- 2. 数字分析法:找出数字的规律,尽可能利用这些数据来构造冲突几率较低的散列地址。
分析一组数据,比方一组员工的出生年月日,这时我们发现出生年月日的前几位数字大体同样,这种话,出现冲突的几率就会非常大,可是我们发现年月日的后几位表示月份和详细日期的数字区别非常大,假设用后面的数字来构成散列地址,则冲突的几率会明显减少。
- 3. 平方取中法:取keyword平方后的中间几位作为散列地址。
- 4. 折叠法:将keyword切割成位数同样的几部分,最后一部分位数能够不同,然后取这几部分的叠加和(去除进位)作为散列地址。
- 5. 随机数法:选择一随机函数,取keyword的随机值作为散列地址,通经常使用于keyword长度不同的场合。
- 6. 除留余数法:取keyword被某个不大于散列表表长m的数p除后所得的余数为散列地址。
即 H(key) = key MOD p, p<=m。不仅能够对keyword直接取模,也可在折叠、平方取中等运算之后取模。对p的选择非常重要,一般取素数或m,若p选的不好,容易产生碰撞.
7、Hash桶算法
说到Hash算法大家就会想到 Hash表,一个Key通过Hash函数运算后可快速的得到hashCode,通过hashCode的映射可直接Get到Value,
但是hashCode一般取值都是非常大的,经常是2^32以上,不可能对每个hashCode都指定一个映射。
因为这样的一个问题,所以人们就将生成的HashCode以分段的形式来映射,把每一段称之为一个Bucket(桶),一般常见的Hash桶就是直接对结果取余。
假设将生成的hashCode可能取值有2^32个,然后将其切分成一段一段,使用 8个桶来映射,那么就可以通过 bucketIndex = HashFunc(key1) % 8这样一个算法来确定这个hashCode映射到具体的哪个桶中。
Dictionary就是用的哈希桶算法
int hashCode =comparer.GetHashCode(key)&0x7FFFFFFF;
int targetBucket = hashCode %buckets.Length;
三、Hash碰撞冲突解决算法
对于一个hash算法,不可避免的会产生冲突,那么产生冲突以后如何处理,是一个很关键的地方,目前常见的冲突解决算法有拉链法(Dictionary实现采用的)、开放定址法、再Hash法、公共溢出分区法
1. 拉链法(开散列 ):将产生冲突的元素建立一个单链表,并将头指针地址存储至Hash表对应桶的位置。这样定位到Hash表桶的位置后可通过遍历单链表的形式来查找元素。
2. 开放定址法(闭散列):当发生哈希冲突时,如果哈希表未被装满,说明在哈希表中必然还有空位置,那么可以把key存放到冲突位置中的“下一个” 空位置中去。
3. 再Hash法:顾名思义就是将key使用其它的Hash函数再次Hash,直到找到不冲突的位置为止。
1. 拉链法
2. 开放定址法
假设现在有一个关键码集合{1,4,5,6,7,9},哈希结构的容量为10,哈希函数为 Hash(key)=key%10。将所有关键码插入到该哈希结构中,如图。

假如现在有一关键码24要插入该结构中,使用哈希函数求得哈希地址为4,但是该地址处已经存放了元素,此时发生哈希冲突。
线性探测:从发生哈希冲突位置开始,依次向后探测,直到找到下一个空位置为止。例如上面的例子,插入关键码24时,进行线性探测,插入后如下图。

限制:
1. 用该方法需要关键码必须为整型才能被模,所以我们需要实现将非整型转化为整型。
2. 模的数值最好为素数,需要我们创建一个素数表。
3. 增容问题。