ConcurrentHashMap基本使用及其原理
HashMap: 线程不安全
Hashtable: 线程安全, 效率低 (底层悲观锁锁整张表)
ConcurrentHashMap: 线程安全, 效率高(分析JDK7和8的底层区别)
package com.itheima04_并发工具类.demo03_ConcurrentHashMap;
import java.util.Hashtable;
import java.util.concurrent.ConcurrentHashMap;
public class Test {
public static void main(String[] args) throws InterruptedException {
// 使用ConcurrentHashMap操作
ConcurrentHashMap hm = new ConcurrentHashMap<>();
Thread t1 = new Thread(() -> {
for (int i = 0; i < 25; i++) {
hm.put(i + "", i + "");
}
});
Thread t2 = new Thread(() -> {
for (int i = 25; i < 51; i++) {
hm.put(i + "", i + "");
}
});
t1.start();
t2.start();
// 让两个线程有机会将数据添加完毕
Thread.sleep(1000);
// 遍历集合: 我们发现很对null
for (int i = 0; i < 51; i++) {
System.out.println(hm.get(i + ""));
}
}
}
JDK1.7 ConcurrentHashMap 底层分析
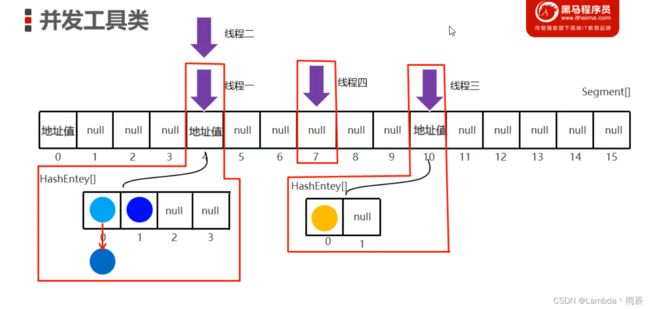
创建ConcurrentHashMap对象时:
创建一个长度为16的大数组, 加载因子是0.75 (Segment[])
创建一个长度为2的小数组, 将地址值赋值给0索引处, 其他索引位置都为null (HashEntry[])
添加元素时, 根据键的哈希值来计算出在大数组中的位置
如果为null, 按照模板创建小数组
创建完毕, 会二次哈希计算出在小数组中应存入的位置, 由于第一次都是null所以直接存入
如果不为null, 会二次哈希, 计算出在小数组中应存入的位置
如果小数组需要扩容, 则扩容为2倍 (存到索引1的地方)
如果不需要扩容, 则会判断小数组当前索引位置是否为null
如果为null代表没有元素, 直接存入
如果不为null代表有元素, 则根据equals方法比较属性值
一样则不存
不一样则将老元素挂在新元素下, 形成链表 (哈希桶)
综上所述, 如果这个大数组Segment[]存满了, 就是一个16*16的大哈希表
为什么效率高?
因为每一次操作只会锁小表 (小数组HashEntry[]), 不会锁大表
所以在JDK1.7之前, 某一时刻最多允许16个线程同时访问
JDK1.8 ConcurrentHashMap 底层分析
ConcurrentHashMap在JDK1.8底层分析:
结构: 哈希表 (数组 + 链表 + 红黑树)
线程安全: CAS机制 + synchronized同步代码块
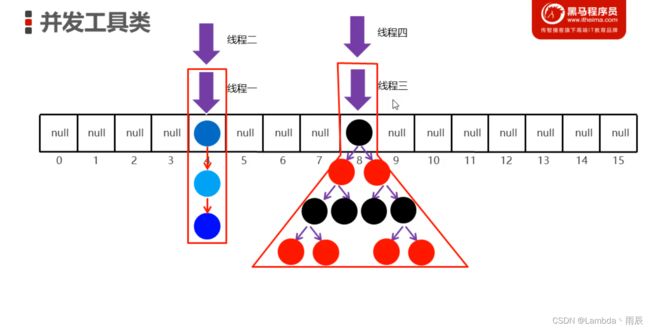
1. 如果使用空参构造创建ConcurrentHashMap对象时, 则什么都不做 (查看空参构造及父类的空参)
2. 在第一次添加元素时 (调用put方法时) 创建哈希表 (initTable方法)
计算当前元素应存入的索引位置
如果为null, 代表没有元素, 则通过CAS算法, 将本节点添加到数组中
如果不为null, 代表有元素, 则利用volatile获得当前索引位置最新的节点地址, 挂在它下面, 形成链表
当链表长度大于等于8的时候, 自动转为红黑树
3. 每次操作, 会以链表或者树的头结点为锁对象, 配合悲观锁(synchronized) 保证多线程操作集合时的安全问题
JDK1.8源码解析:
在ConcurrentHashMap对对象进行初始化new操作的时候,不会去初始化表结构,只有当用到put方法时,才会对哈希表进行构建,源码如下
第一次put时,会对哈希表进行初始化操作,具体代码如下:
private final Node[] initTable() {
Node[] tab; int sc;
while ((tab = table) == null || tab.length == 0) {
if ((sc = sizeCtl) < 0)
Thread.yield(); // lost initialization race; just spin
else if (U.compareAndSwapInt(this, SIZECTL, sc, -1)) {
try {
if ((tab = table) == null || tab.length == 0) {
int n = (sc > 0) ? sc : DEFAULT_CAPACITY;
@SuppressWarnings("unchecked")
Node[] nt = (Node[])new Node[n];
table = tab = nt;
sc = n - (n >>> 2);
}
} finally {
sizeCtl = sc;
}
break;
}
}
return tab;
} 第一次之后put时,会进行如下判断,再进行插入操作
public class ConcurrentHashMap extends AbstractMap
implements ConcurrentMap, Serializable {
public V put(K key, V value) {
return putVal(key, value, false);
}
/** Implementation for put and putIfAbsent */
final V putVal(K key, V value, boolean onlyIfAbsent) {
if (key == null || value == null) throw new NullPointerException();
int hash = spread(key.hashCode());
int binCount = 0;
for (Node[] tab = table;;) {
Node f; int n, i, fh;
if (tab == null || (n = tab.length) == 0)
tab = initTable();
else if ((f = tabAt(tab, i = (n - 1) & hash)) == null) {
if (casTabAt(tab, i, null,
new Node(hash, key, value, null)))
break; // no lock when adding to empty bin
}
else if ((fh = f.hash) == MOVED)
tab = helpTransfer(tab, f);
else {
V oldVal = null;
synchronized (f) {
if (tabAt(tab, i) == f) {
if (fh >= 0) {
binCount = 1;
for (Node e = f;; ++binCount) {
K ek;
if (e.hash == hash &&
((ek = e.key) == key ||
(ek != null && key.equals(ek)))) {
oldVal = e.val;
if (!onlyIfAbsent)
e.val = value;
break;
}
Node pred = e;
if ((e = e.next) == null) {
pred.next = new Node(hash, key,
value, null);
break;
}
}
}
else if (f instanceof TreeBin) {
Node p;
binCount = 2;
if ((p = ((TreeBin)f).putTreeVal(hash, key,
value)) != null) {
oldVal = p.val;
if (!onlyIfAbsent)
p.val = value;
}
}
}
}
if (binCount != 0) {
if (binCount >= TREEIFY_THRESHOLD)
treeifyBin(tab, i);
if (oldVal != null)
return oldVal;
break;
}
}
}
addCount(1L, binCount);
return null;
}
} 本章内容不对具体实现的步骤进行解释,大家期待后续文章发布再进行深度解析
继承结构: