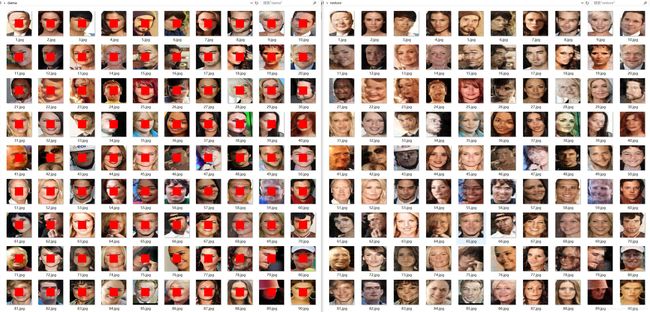
自编码AE 实现图片去马赛克(完整代码奉献) pytorch
前言:博主闲来无事,写了个AE网络来实现任意图片的去马赛克(前提是训练样本是哪方面的马赛克图~~,博主是针对打码人脸的去码)。样本分为没打码人脸8000张和经打码处理的对应8000张(取自celeba人脸数据集)。预处理阶段:人脸resize到256x256,打码。为读入数据,把文件夹里的图片名读取出并保存到了label.txt文件。主程序分4块:网络定义文件net.py, 读数据dataset.py, 训练train.py, 测试test.py 。并在每段代码上,我认为初学者易犯错的地方做了详解。
这是一个练手的网络,仅供初学者参考交流,博主希望能通过此代码在以下几点对初学者有所帮助
- 如何把本地文件传入网络:通过from torch.utils.data import Dataset,DataLoader,具体见dataset.py
- 对于待读入的图没有现成的标签时,如何制作标签文件:见ToTxt.py
- 编程起于清晰的思路,只有熟知一步步怎么做才能把一件事完成,才会写出完整的代码。如要实现人脸去码,那么我的思路就是:把打码图传入,先编码再解码,把解码的结果与对应的未打码的图求loss(用的均值平方差),这样就能够引导解码出的图向未打码前的样子不断靠拢。最后,把没训练过的新的打码的图传入AE网络,则编码出的图就会是该图打码前的样子
- 编程过程,一定要时刻警惕矩阵维度的转变(通道数),tensor与numpy的转化,HWC—>CHW, CHW—>NCHW, BGR—>RGB等细节问题。一不留神就会出bug,也是初学者最易犯的错误。
- 我的思考:AE网络的好处是易训练,稳定性好,但是学到的是两张对应图片上的像素间点对点的对应关系,从loss函数也能看出,这样就无法学到每张图内部的像素点与像素点间的相对空间关系(分布)。而gan网络恰好是学的分布关系。可知AE与GAN是优势互补的。所以,我说到这里,大家也能想到了,做图像修复的话,把二者结合使用是非常不错的方法,我相信会有明显的提升。实际我也在做了,也是博主研究生课题的一环,等过一段时间出了结果后续我再总结一下。
一. 代码
1.全代码名称展示


2.主程序
(1)dataset.py
'自制作样本标签txt以读取'
import torch
import os
import numpy as np
import cv2
from torch.utils.data import Dataset,DataLoader
class GetData(Dataset):
def __init__(self,path1,path2):
super(GetData,self).__init__()
self.path1 = path1
self.path2 = path2
self.dataset1 = []
self.dataset2 = []
self.dataset1.extend(open(os.path.join(self.path1,'label.txt')).readlines())
self.dataset2.extend(open(os.path.join(self.path2,'label.txt')).readlines())
def __getitem__(self, index): #index不是待赋参量,而是对应批次batch_size
str1 = self.dataset1[index].strip() #如dataset[0]是第一批次
str2 = self.dataset2[index].strip()
imgpath1 = os.path.join(self.path1,str1)
imgpath2 = os.path.join(self.path2,str2)
im1 = cv2.imread(imgpath1)
im2 = cv2.imread(imgpath2)
'对imgdata不要用transpose,会导致cv2.imshow()时出现显示错误!!!'
imgdata1 = torch.Tensor((im1 / 255. - 0.5))
imgdata2 = torch.Tensor((im2 / 255. - 0.5))
return imgdata1,imgdata2
def __len__(self):
return len(self.dataset1)
'cv2里BGR且HWC'
if __name__ == '__main__':
dataset= GetData(r'C:\Users\87419\Desktop\VAE1\data\trainA',r'C:\Users\87419\Desktop\VAE1\data\trainB')
dataloader = DataLoader(dataset, batch_size=200 ,shuffle=True) #经DataLoader()加批次N,由3维升至4维。平展求参数总量要乘N
for i,(imgdata ,_) in enumerate(dataloader):
# print(imgdata.numpy().shape) # NHWC(1, 256, 256, 3)
'imgdata是4维数据NHWC;imgdata[i]是第i-1批次,是3维数据HWC'
im1 = imgdata[0].numpy().reshape((256,256,3)) #经imgdata = torch.Tensor((im1 / 255. - 0.5))操作,显示与原图对应的像素点颜色不一样
cv2.imshow('a',im1)
cv2.waitKey(0)
(2).net.py
import torch
import torch.nn as nn
'需要分类时用全连接,提取特征用卷积'
class AutoEncoder(nn.Module):
def __init__(self):
super(AutoEncoder,self).__init__()
self.encoder = nn.Sequential(
nn.Conv2d(in_channels=3,
out_channels=16,
kernel_size=3,
stride=1,
padding=1), # (3,256,256)-->(16,256,256)
nn.PReLU(),
nn.Conv2d(in_channels=16,
out_channels=16,
kernel_size=4,
stride=2,
padding=1), # (16,256,256)-->(16,128,128)
nn.PReLU(),
nn.Conv2d(in_channels=16,
out_channels=32,
kernel_size=3,
stride=1,
padding=1), # (32,128,128)
nn.PReLU(),
nn.Conv2d(in_channels=32,
out_channels=32,
kernel_size=4,
stride=2,
padding=1), # (32,64,64)
nn.PReLU(),
nn.Conv2d(in_channels=32,
out_channels=64,
kernel_size=3,
stride=1,
padding=1), # (64,64,64)
nn.PReLU(),
nn.Conv2d(in_channels=64,
out_channels=64,
kernel_size=4,
stride=2,
padding=1), # (64,32,32)
nn.PReLU(),
nn.Conv2d(in_channels=64,
out_channels=128,
kernel_size=4,
stride=2,
padding=1), # (128,16,16)
nn.PReLU(),
nn.Conv2d(in_channels=128,
out_channels=128,
kernel_size=4,
stride=2,
padding=1), # (128,8,8)
nn.PReLU(),
nn.Conv2d(in_channels=128,
out_channels=256,
kernel_size=3,
stride=1,
padding=1), # (256,8,8)
nn.PReLU(),
nn.Conv2d(in_channels=256,
out_channels=256,
kernel_size=4,
stride=2,
padding=1) # (256,4,4)
)
self.decoder = nn.Sequential(
nn.ConvTranspose2d(256, 256, kernel_size=3, stride=3, padding=2), #(256,4,4)-->(256,8,8)
nn.PReLU(),
nn.ConvTranspose2d(256, 128, kernel_size=3, stride=1, padding=1), # (256,8,8)-->(128,8,8)
nn.PReLU(),
nn.ConvTranspose2d(128, 128,kernel_size=2,stride= 2), # (128,8,8)-->(128,16,16)
nn.PReLU(),
nn.ConvTranspose2d(128, 64, kernel_size=2, stride=2), # (128,16,16)-->(64,32,32)
nn.PReLU(),
nn.ConvTranspose2d(64, 64, kernel_size=2, stride=2), # (64,32,32)-->(64,64,64)
nn.PReLU(),
nn.ConvTranspose2d(64, 32, kernel_size=1, stride=1), # (64,64,64)-->(32,64,64)
nn.PReLU(),
nn.ConvTranspose2d(32, 32, kernel_size=2, stride=2), # (32,64,64)-->(32,128,128)
nn.PReLU(),
nn.ConvTranspose2d(32, 16, kernel_size=1, stride=1), # (32,128,128)-->(16,128,128)
nn.PReLU(),
nn.ConvTranspose2d(16, 16, kernel_size=2, stride=2), # (16,128,128)-->(16,256,256)
nn.PReLU(),
nn.ConvTranspose2d(16, 3, kernel_size=1, stride=1), # (16,256,256)-->(3,256,256)
nn.Tanh()
)
def forward(self, x):
encoded = self.encoder(x)
decoded = self.decoder(encoded)
return encoded, decoded
(3)train.py
import torch
import torch.optim as optim
from net import AutoEncoder
import torch.nn as nn
import os
import cv2
import numpy as np
from dataset import GetData
from torch.utils.data import DataLoader
auto = AutoEncoder()
auto.cuda()
LR = 0.001
BATCH_SIZE = 180
EPOCHES = 200
optimizer = optim.Adam(auto.parameters(),lr=LR)
loss_f = nn.MSELoss() #均方误差
def train(x,_x): # x有码图,_x无码图
if os.path.exists(r'C:\Users\87419\Desktop\VAE2\auto.pkl'):
auto.load_state_dict(torch.load(r'C:\Users\87419\Desktop\VAE2\auto.pkl'))
#################################################
'此段来显示图片,用以判断输入的无码图是否正常'
# _x = _x[0].detach().cpu().data.numpy()
# _x = _x.reshape(256,256,3)
# cv2.imshow('aa', _x)
# cv2.waitKey(0)
################################################
encoded, decoded = auto(x)
loss = loss_f(decoded,_x)
return loss
for i in range(EPOCHES):
print('epoch:',i)
dataset = GetData(r'C:\Users\87419\Desktop\VAE1\data\trainB', r'C:\Users\87419\Desktop\VAE1\data\trainA')
dataloader = DataLoader(dataset, batch_size=BATCH_SIZE, shuffle=True)
for j,(imgdata1,imgdata2) in enumerate(dataloader):
'每次循环,同时处理BATCH_SIZE张。故每个epoch内的循环次数j=总张数/BATCH_SIZE '
'对于dataloder的批次,imgdata是NCHW。对其取imgdata[0]是取N上的第一个批次对应的CHW而不是数值N,同理imgdata[9]是取N上的第10个批次对应的CHW'
'为了让批次设的有意义,取批量的imgdata1.cuda()而不是imgdata1[0].cuda()'
imgdata1_ = imgdata1.cuda()
imgdata2_ = imgdata2.cuda()
'切记为不影响矩阵内部结构就用reshape() 。此处view()等都会导致内部矩阵结构变化,从而输出图片出问题'
# imgdata1_ = imgdata1_.view(-1,3,256,256)
# imgdata2_ = imgdata2_.view(-1,3,256,256)
imgdata1_ = imgdata1_.reshape(-1,3,256,256)
imgdata2_ = imgdata2_.reshape(-1,3,256,256)
# print(imgdata1_.shape) # [180, 3 ,256, 256]
loss = train(imgdata1_,imgdata2_)
optimizer.zero_grad()
loss.backward()
optimizer.step()
print('j:',j,'|','loss:',loss)
torch.save(auto.state_dict(),'auto.pkl')
(4)test.py
import torch
from net import AutoEncoder
import cv2
import os
from PIL import Image
import numpy as np
auto = AutoEncoder()
auto.load_state_dict(torch.load('auto.pkl'))
auto.cuda()
count = 0
# x_path = r'C:\Users\87419\Desktop\VAE1\data\test'
x_path = r'C:\Users\87419\Desktop\cg1\dama'
for name in os.listdir(x_path):
count += 1
im1 = cv2.imread(os.path.join(x_path,name))
arr = np.array(im1)
arr_ = torch.Tensor(arr /255. - 0.5)
arr_ = arr_.cuda()
arr_ = arr_.reshape(-1,3,256,256)
encoded = auto.encoder(arr_)
decoded=auto.decoder(encoded)
img = (decoded.detach().cpu().numpy() + 0.5)*255
'网络运算时是NCHW,待到输出图时需变回HWC'
img = img.reshape(256, 256,3)
# img = img[:, :, ::-1] # BGR->RGB
# print(img)
# cv2.imshow('{}'.format(name),img)
# cv2.waitKey(0)
# cv2.imwrite(os.path.join(r'C:\Users\87419\Desktop\VAE1\data\save',name),img)
cv2.imwrite(os.path.join(r'C:\Users\87419\Desktop\cg1\restore',name),img)
3.预处理程序
(1).resize.py
'cv2'
import cv2
import os
import glob
path = r'C:\Users\87419\Desktop\cg1\img\*.jpg'
for i in glob.glob(path):
im1 = cv2.imread(i)
im2 = cv2.resize(im1, (256, 256))
cv2.imwrite(os.path.join(r'C:\Users\87419\Desktop\cg1\resize', os.path.basename(i)), im2)
(2)dama.py
import os
from PIL import Image
import numpy as np
outdir = r'C:\Users\87419\Desktop\cg1\dama'
count = 0
path = r'C:\Users\87419\Desktop\cg1\resize'
x_names = os.listdir(path)
x_names.sort(key=lambda i: int(i[:-4]))
for i in x_names:
im1 = Image.open(os.path.join(path, i))
arr = np.array(im1)
h = arr.shape[0]
w = arr.shape[1]
for j in range(int((1 / 3) * w), int((2 / 3) * w), 1):
for k in range(int((1 / 3) * h), int((2 / 3) * h), 1):
im1.putpixel((j, k), (255, 0, 0))
count += 1
print(count)
im1.save(os.path.join(outdir, '{}.jpg'.format(count)))
(3)ToTxt.py
import os
def ListFilesToTxt(dir, file, wildcard, recursion):
exts = wildcard.split(" ")
files = os.listdir(dir)
files.sort(key=lambda x: int(x[:-4]))
for name in files:
fullname = os.path.join(dir, name)
if (os.path.isdir(fullname) & recursion):
ListFilesToTxt(fullname, file, wildcard, recursion)
else:
for ext in exts:
if (name.endswith(ext)):
file.write(name + "\n")
break
def Test():
dir = r"C:\Users\87419\Desktop\VAE1\data\trainA" # 读入
outfile = "label.txt" # 写入
# wildcard = ".jpg .txt .exe .dll .lib" # 要读取的文件类型
wildcard = ".jpg"
file = open(outfile, "w")
if not file:
print("cannot open the file %s for writing" % outfile)
ListFilesToTxt(dir, file, wildcard, 1)
file.close()
if __name__ == '__main__':
Test()
二.效果展示