2021及历届国科大高级OS思考题汇总
国科大高级OS思考题汇总
- 师兄们的成果。。。21年考了打机枪那块的数据结构。。。
文章目录
-
-
- 国科大高级OS思考题汇总
-
- 1、bootsect、setup、head程序之间是怎么衔接的?给出代码证据。
- 2、setup程序里的cli是为了什么?
- 3、setup程序的最后是jmpi 0,8 为什么这个8不能简单的当作阿拉伯数字8看待?
- 4、打开A20和打开pe究竟是什么关系,保护模式不就是32位的吗?为什么还要打开A20?有必要吗?
- 5、Linux是用C语言写的,为什么没有从main还是开始,而是先运行3个汇编程序,道理何在?
- 6、为什么不用call,而是用ret“调用”main函数?画出调用路线图,给出代码证据。
- 7、保护模式的“保护”体现在哪里?
- 8、特权级的目的和意义是什么?为什么特权级是基于段的?
- 9、在setup程序里曾经设置过一次gdt,为什么在head程序中将其废弃,又重新设置了一个?为什么折腾两次,而不是一次搞好?
- 10、用户进程自己设计一套LDT表,并与GDT挂接,是否可行,为什么?
- 11、保护模式、分页下,线性地址到物理地址的转化过程是什么?
- 12、为什么开始启动计算机的时候,执行的是BIOS代码而不是操作系统自身的代码?
- 13、为什么BIOS只加载了一个扇区,后续扇区却是由bootsect代码加载?为什么BIOS没有直接把所有需要加载的扇区都加载?
- 14、为什么BIOS把bootsect加载到0x07c00,而不是0x00000?加载后又马上挪到0x90000处,是何道理?为什么不一次加载到位?
- 15、进程0的task_struct在哪?具体内容是什么?
- 16、内核的线性地址空间是如何分页的?画出从0x000000开始的7个页(包括页目录表、页表所在页)的挂接关系图,就是页目录表的前四个页目录项、第一个个页表的前7个页表项指向什么位置?给出代码证据。
- 17、用文字和图说明中断描述符表是如何初始化的,可以举例说明(比如:set_trap_gate(0,÷_error)),并给出代码证据。
- 18、在IA-32中,有大约20多个指令是只能在0特权级下使用,其他的指令,比如cli,并没有这个约定。奇怪的是,在Linux0.11中,3特权级的进程代码并不能使用cli指令,这是为什么?请解释并给出代码证据。
- 19、在system.h里
- 20、进程0 fork进程1之前,为什么先调用move_to_user_mode()?用的是什么方法?解释其中的道理。
- 21、copy_process函数的参数最后五项是:long eip,long cs,long eflags,long esp,long ss。查看栈结构确实有这五个参数,奇怪的是其他参数的压栈代码都能找得到,确找不到这五个参数的压栈代码,反汇编代码中也查不到,请解释原因。
- 22、分析get_free_page()函数的代码,叙述在主内存中获取一个空闲页的技术路线。
- 23、分析copy_page_tables()函数的代码,叙述父进程如何为子进程复制页表。
- 24、进程0创建进程1时,为进程1建立了task_struct及内核栈,第一个页表,分别位于物理内存16MB顶端倒数第一页、第二页。请问,这两个页究竟占用的是谁的线性地址空间,内核、进程0、进程1、还是没有占用任何线性地址空间?说明理由(可以图示)并给出代码证据。
- 25、假设:经过一段时间的运行,操作系统中已经有5个进程在运行,且内核分别为进程4、进程5分别创建了第一个页表,这两个页表在谁的线性地址空间?用图表示这两个页表在线性地址空间和物理地址空间的映射关系。
- 26、代码中的"ljmp %0\n\t" 很奇怪,按理说jmp指令跳转到得位置应该是一条指令的地址,可是这行代码却跳到了"m" (*&__tmp.a),这明明是一个数据的地址,更奇怪的,这行代码竟然能正确执行。请论述其中的道理。
- 27、进程0开始创建进程1,调用fork(),跟踪代码时我们发现,fork代码执行了两次,第一次,执行fork代码后,跳过init()直接执行了for( ; ; ) pause(),第二次执行fork代码后,执行了init()。奇怪的是,我们在代码中并没有看到向转向fork的goto语句,也没有看到循环语句,是什么原因导致fork反复执行?请说明理由(可以图示),并给出代码证据。
- 28、打开保护模式、分页后,线性地址到物理地址是如何转换的?
- 29、详细分析进程调度的全过程。考虑所有可能(signal、alarm除外)
- 30、wait_on_buffer函数中为什么不用if()而是用while()?
- 31、add_reques()函数中有下列代码
- 32、do_hd_request()函数中dev的含义始终一样吗?
- 33、read_intr()函数中,下列代码是什么意思?为什么这样做?
- 34、bread()函数代码中为什么要做第二次if (bh->b_uptodate)判断?
- 35、getblk()函数中,两次调用wait_on_buffer()函数,两次的意思一样吗?
- 36、getblk()函数中
- 37、make_request()函数
- 38.在head程序执行结束的时候,在idt的前面有184个字节的head程序的剩余代码,剩余了什么?为什么要剩余?
- 39.在Linux操作系统中大量使用了中断、异常类的处理,究竟有什么好处?
- 40、getblk函 数中,申请空闲缓冲块的标准就是b_count为0,而申请到之后,为什么在wait_on_buffer(bh)后又执行if(bh->b_count)来判断b_count是否为0?
- 41、b_dirt已经被置为1的缓冲块,同步前能够被进程继续读、写?给出代码证据。
- 42、分析panic函数的源代码,根据你学过的操作系统知识,完整、准确的判断panic函数所起的作用。假如操作系统设计为支持内核进程(始终运行在0特权级的进程),你将如何改进panic函数?
- 43、操作系统如何利用b_uptodate保证缓冲块数据的正确性?new_block (int dev)函数新申请一个缓冲块后,并没有读盘,b_uptodate却被置1,是否会引起数据混乱?详细分析理由。
- 44、为什么static inline _syscall0(type,name)中需要加上关键字inline?
- 45、根据代码详细说明copy_process函数的所有参数是如何形成的?
- 46、进程0创建进程1时调用copy_process函数,在其中直接、间接调用了两次get_free_page函数,在物理内存中获得了两个页,分别用作什么?是怎么设置的?给出代码证据。
- 47、用户进程自己设计一套LDT表,并与GDT挂接,是否可行,为什么?
- 48、为什么get_free_page()将新分配的页面清0?P265
- 49、内核和普通用户进程并不在一个线性地址空间内,为什么仍然能够访问普通用户进程的页面?P271
- 50、为什么要设计缓冲区,有什么好处?
- 51、copy_mem()和copy_page_tables()在第一次调用时是如何运行的?
- 52、用图表示下面的几种情况,并从代码中找到证据:
- 53、在虚拟盘被设置为根设备之前,操作系统的根设备是软盘,请说明设置软盘为根设备的技术路线。
-
1、bootsect、setup、head程序之间是怎么衔接的?给出代码证据。
bootsect将setup加载到 0x90200 处INITSEG = 0x9000 ! we move boot here - out of the way jmpi go,INITSEG ! 修改 cs go: mov ax,cs mov ds,ax mov es,ax load_setup: mov dx,#0x0000 ! drive 0, head 0 mov cx,#0x0002 ! sector 2, track 0 mov bx,#0x0200 ! address = 512, in INITSEG mov ax,#0x0200+SETUPLEN ! service 2, nr of sectors int 0x13 ! read it jnc ok_load_setup ! ok - continue mov dx,#0x0000 mov ax,#0x0000 ! reset the diskette int 0x13 j load_setup
bootsect将system加载到 0x10000 处SYSSIZE = 0x3000 SYSSEG = 0x1000 ! system loaded at 0x10000 (65536). ENDSEG = SYSSEG + SYSSIZE ! where to stop loading mov ax,#SYSSEG mov es,ax ! segment of 0x010000 call read_it read_it: mov ax,es test ax,#0x0fff ! 64KB 对齐 die: jne die ! es must be at 64kB boundary xor bx,bx ! bx is starting address within segment rp_read: mov ax,es cmp ax,#ENDSEG ! have we loaded all yet? jb ok1_read ret ok1_read: seg cs mov ax,sectors ! 每磁道扇区数 sub ax,sread ! 当前磁道已读扇区数 mov cx,ax shl cx,#9 ! 计算一共有多少个字节 (*512) 以下是用来判断是否超过 64KB,真正有用的是 ax add cx,bx ! 段内当前偏移值 jnc ok2_read je ok2_read ! 没有超过 64KB xor ax,ax sub ax,bx ! 计算此时最多能读入的字节数 shr ax,#9 ok2_read: call read_track mov cx,ax ! 该次操作读取的扇区数 add ax,sread ! 当前磁道已读扇区数 seg cs cmp ax,sectors jne ok3_read ! 如果当前磁道还有扇区未读,则跳转到 ok3_read mov ax,#1 sub ax,head jne ok4_read ! 如果是 0 磁头,则去读 1 磁头面上的扇区数据 inc track ! 否则去读下一磁道 ok4_read: mov head,ax xor ax,ax ! 清零当前已读扇区数 ok3_read: mov sread,ax shl cx,#9 add bx,cx ! 调整当前段内数据开始的位置 jnc rp_read mov ax,es add ax,#0x1000 mov es,ax xor bx,bx jmp rp_read read_track: push ax push bx push cx push dx mov dx,track ! 当前磁道号 mov cx,sread ! 当前磁道已读扇区数 inc cx ! 从下一扇区开始读 mov ch,dl mov dx,head ! 当前磁头号 mov dh,dl mov dl,#0 and dx,#0x0100 mov ah,#2 int 0x13 jc bad_rt pop dx pop cx pop bx pop ax ret bad_rt: mov ax,#0 ! 执行驱动器复位操作 mov dx,#0 int 0x13 pop dx pop cx pop bx pop ax jmp read_track
bootsect跳转到setupSETUPSEG = 0x9020 ! setup starts here jmpi 0,SETUPSEG ! 跳转到 setup.s
setup将system移动到 0x0 处mov ax,#0x0000 cld ! 'direction'=0, movs moves forward do_move: mov es,ax ! destination segment add ax,#0x1000 cmp ax,#0x9000 jz end_move mov ds,ax ! source segment sub di,di sub si,si mov cx,#0x8000 rep movsw jmp do_move
setup加载 GDT,令内核代码段基址指向第一条指令,即 0x0 处! 内核代码段 .word 0x07FF ! 8Mb - limit=2047 (2048*4096=8Mb) .word 0x0000 ! base address=0 .word 0x9A00 ! code read/exec .word 0x00C0 ! granularity=4096, 386
setup进入保护模式,通过内核代码段选择子和偏移量跳转到headjmpi 0,8 ! jmp offset 0 of segment 8 (cs) 进入 head
2、setup程序里的cli是为了什么?
setup要将内核代码复制到 0x00000 处,该处原本为中断向量表,内核代码覆盖该位置后中断向量表被破坏,如果此时有中断进来,中断不能被正确处理,因此在此之前需要关闭中断。- 此时需要由 16 位实模式向 32 位保护模式转变,即将进行实模式下的中断向量表和保护模式下的中断描述符表的交接工作,在保护模式的中断机制尚未完成时不允许响应中断,以免发生未知的错误。
3、setup程序的最后是jmpi 0,8 为什么这个8不能简单的当作阿拉伯数字8看待?
当进入保护模式后,
jmpi指令后若跟两个数字,则 CPU 将这两个数字视为偏移量和段选择子,根据段选择子的规则,bit15 - bit3 为描述符表的索引,bit2 表示在 GDT 中或在 LDT 中索引,bit1 - bit0 表示请求特权级。8 = 1000=> 1=描述符表的第一项,0表示GDT,00表示0特权级
4、打开A20和打开pe究竟是什么关系,保护模式不就是32位的吗?为什么还要打开A20?有必要吗?
打开 PE 表示让 CPU 进入保护模式,若不打开 A20,则对于所有 32 位地址,bit20 都为 0,可以访问的内存只能是奇数 1M 段。
5、Linux是用C语言写的,为什么没有从main还是开始,而是先运行3个汇编程序,道理何在?
- 有些操作只能用汇编来写,比如特权指令。
- 尽管可以用 gcc 将 C 语言编译为 16 位模式的代码,但生成的可执行文件为 ELF 格式的,除了执行指令外还有其他的部分,导致可执行文件的体积变大,可能
bootsect可执行程序的大小大于一个扇区的大小,加载后造成运行错误。另外,BIOS 将第一扇区加载到内存后就从第一字节开始执行,因此需要进行裁剪,令第一条指令从第一字节开始。- 使用汇编能在编译阶段就对内存按照自己的需求进行划分。比如
setup.s中 IDT、GDT、页目录表、页表所占用的内存地址空间。- 《艺术》P43 点评
6、为什么不用call,而是用ret“调用”main函数?画出调用路线图,给出代码证据。
- 在逻辑上
head是操作系统的底层,所以需要让main看起来是在调用head程序。- 在由
head程序向main函数跳转时,是不需要main函数返回的。调用路线图:《艺术》P42 图 1-46
jmpretretjmpafter_page_tablessetup_pagingmainL6代码:
after_page_tables: pushl $0 # These are the parameters to main :-) envp pushl $0 # argv pushl $0 # argc pushl $L6 # return address for main, if it decides to. pushl $_main # kernel 的 main 函数地址 jmp setup_paging L6: jmp L6 # main should never return here, but # just in case, we know what happens. setup_paging: // 内核分页,分完以后 线性地址 == 物理地址 // ... ret /* this also flushes prefetch-queue */ // 我们是操作系统的底层,所以要返回到 kernel 中
7、保护模式的“保护”体现在哪里?
保护机制提供了对特定段或页进行限制性访问的能力。

当使用保护机制时,对内存的任何引用都要进行检验,以确定是否符合各种保护性要求,保护性检验可以分为以下几类:
- 界限检验
- 类型检验
- 特权级检验
- 可寻址区域的限制
- 例程入口点的限制
- 指令集的限制
所有保护违例都会产生异常。
8、特权级的目的和意义是什么?为什么特权级是基于段的?
除非某些可控制情况之外,处理器使用特权级来阻止较低特权级的进程或任务访问特权级较高的段。
特权级检验是在段描述符的段选择子被装入段寄存器时进行的。

9、在setup程序里曾经设置过一次gdt,为什么在head程序中将其废弃,又重新设置了一个?为什么折腾两次,而不是一次搞好?
- 在
setup程序里设置gdt是为程序进入保护模式提供全局描述符表;- 在
head程序中重新设置gdt的主要原因是为了把gdt表放在内存内核代码比较合理的地方。当然我们也可以在setup程序中就把描述符的段限长直接设置成 16MB,然后在head中直接把原 GDT 表移动到内存适当位置处。但由于setup和head连接时不在同一个文件,setup无法直接获取head中的 gdt 的偏移量,需事先写入,这会使设计失去一般性,给程序编写带来很大不便。- 《艺术》P33 点评
10、用户进程自己设计一套LDT表,并与GDT挂接,是否可行,为什么?
不可行。
- 用户态无法访问 gdtr 的值,因此无法访问 GDT;
- GDT 位于内核数据段,属于 0 特权级,3 特权级的用户进程无权访问修改;
- LDT 的首地址的值必须使用
lldt指令挂载到 ldtr 上才能被使用,但lldt指令是特权指令。
11、保护模式、分页下,线性地址到物理地址的转化过程是什么?
- cpu 通过 cr3 寄存器定位到页目录表的物理地址;
- 使用线性地址的高 10 位作为索引在页目录表中定位到某一页目录表项;
- 读出页目录表项的内容,即为页表的物理地址;
- 使用线性地址的中间 10 位作为索引在页表中定位到某一页表项;
- 读出页表项的内容,即为对应的页的起始物理地址;
- 页的起始物理地址加上线性地址的低 12 位即为线性地址对应的物理地址。

12、为什么开始启动计算机的时候,执行的是BIOS代码而不是操作系统自身的代码?
计算机启动的时候,内存尚未初始化, 因为 CPU 只能读取内存中的程序, 所以如果要首先执行操作系统的代码,那么需要先将操作系统的代码从硬盘加载到内存,但这一过程本身也需要执行指令,这些指令必定不能是操作系统的指令,而BIOS的作用之一正是提供这样的指令。
13、为什么BIOS只加载了一个扇区,后续扇区却是由bootsect代码加载?为什么BIOS没有直接把所有需要加载的扇区都加载?
- BIOS 和操作系统的开发通常是不同的团队,按固定的规则约定,可以进行灵活的各自设计相应的部分。
- BIOS 不知道需要加载的扇区有多少。
- 加载哪些扇区,将扇区加载到哪一般由操作系统决定。
- 给操作系统留尽量大的可用内存空间。
- BIOS 处于实模式,只能访问 1MB 以下的内存地址空间,如果操作系统需要加载的内容大于 1MB,它无法加载所有的内容。
14、为什么BIOS把bootsect加载到0x07c00,而不是0x00000?加载后又马上挪到0x90000处,是何道理?为什么不一次加载到位?
0x00000 是中断向量表的起始地址,暂时不能被覆盖。
0x07c00 这个地址有历史原因。
0x7C00 这个地址来自 Intel 的第一代个人电脑芯片 8088,以后的 CPU 为了保持兼容,一直使用这个地址。1981 年 8 月,IBM 公司最早的个人电脑 IBM PC 5150 上市,就用了这个芯片。当时,搭配的操作系统是 86-DOS。这个操作系统需要的内存最少是 32KB。我们知道,内存地址从 0x0000 开始编号,32KB 的内存就是 0x0000~0x7FFF。8088 芯片本身需要占用 0x0000~0x03FF,用来保存各种中断处理程序的储存位置。(主引导记录本身就是中断信号 INT 19h 的处理程序。) 所以,内存只剩下 0x0400~0x7FFF 可以使用。为了把尽量多的连续内存留给操作系统,主引导记录就被放到了内存地址的尾部。由于一个扇区是 512 字节,主引导记录本身也会产生数据,需要另外留出 512 字节保存。所以,它的预留位置就变成了 0x7FFF - 512 - 512 + 1 = 0x7C00
bootsect有数据需要保存以便后续使用(比如:偏移 0x508 处保存的根文件系统所在的设备号),而根据操作系统对内存的规划,内核占用 0x00000 开始的空间,因此 0x07c00 可能会被覆盖,并且system将会被加载到 0x10000-0x8FFFF 地址处,所以将bootsect挪到 0x90000 处。《艺术》P6 点评
《艺术》P9 点评
15、进程0的task_struct在哪?具体内容是什么?

- 代码如下:(若未要求没时间可不写) INIT_TASK的定义见P68。
16、内核的线性地址空间是如何分页的?画出从0x000000开始的7个页(包括页目录表、页表所在页)的挂接关系图,就是页目录表的前四个页目录项、第一个个页表的前7个页表项指向什么位置?给出代码证据。


- P39****最下面
17、用文字和图说明中断描述符表是如何初始化的,可以举例说明(比如:set_trap_gate(0,÷_error)),并给出代码证据。
(先画图见P54 图2-9然后解释)以set_trap_gate(0,÷_error)为例,其中,n是0,gate_addr是&idt[0],也就是idt的第一项中断描述符的地址;type是15,dpl(描述符特权级)是0;addr是中断服务程序divide_error(void)的入口地址。
代码证据:P53 代码
18、在IA-32中,有大约20多个指令是只能在0特权级下使用,其他的指令,比如cli,并没有这个约定。奇怪的是,在Linux0.11中,3特权级的进程代码并不能使用cli指令,这是为什么?请解释并给出代码证据。
#define INIT_TASK \ /* ... */\ /*tss*/ {0,PAGE_SIZE+(long)&init_task,0x10,0,0,0,0,(long)&pg_dir,\ 0,0,0,0,0,0,0,0, /* eflags 的值为 0 */\ 0,0,0x17,0x17,0x17,0x17,0x17,0x17, \ _LDT(0),0x80000000, \ {} \ }, \ }在 3 特权级下执行
cli指令会触发一般保护异常,中断号为 0x0d:_general_protection: pushl $_do_general_protection jmp error_code error_code: // ... iretset_trap_gate(13,&general_protection); void do_general_protection(long esp, long error_code) { die("general protection",esp,error_code); }实验:
修改
init/main.c中的代码为:move_to_user_mode(); __asm__ ("cli"::); if (!fork()) { /* we count on this going ok */ init(); }结果:

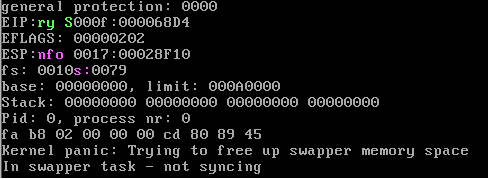
19、在system.h里
\#define _set_gate(gate_addr,type,dpl,addr) \
__asm__ ("movw %%dx,%%ax\n\t" \
"movw %0,%%dx\n\t" \
"movl %%eax,%1\n\t" \
"movl %%edx,%2" \
: \
: "i" ((short) (0x8000+(dpl<<13)+(type<<8))), \
"o" (*((char *) (gate_addr))), \
"o" (*(4+(char *) (gate_addr))), \
"d" ((char *) (addr)),"a" (0x00080000))
\#define set_intr_gate(n,addr) \
_set_gate(&idt[n],14,0,addr)
\#define set_trap_gate(n,addr) \
_set_gate(&idt[n],15,0,addr)
\#define set_system_gate(n,addr) \
_set_gate(&idt[n],15,3,addr)
-
读懂代码。这里中断门、陷阱门、系统调用都是通过_set_gate设置的,用的是同一个嵌入汇编代码,比较明显的差别是dpl一个是3,另外两个是0,这是为什么?说明理由。
- 门的特权检验规则为:CPL <= 调用门 DPL;RPL <= 调用门DPL
- 系统调用是由用户态程序调用的,因此 DPL 为 3.
- 以
int指令主动发中断时使用中断门,以int3指令主动发中断时使用陷阱门,中断门和陷阱门不能被用户态程序调用,因此 DPL 为 0.
20、进程0 fork进程1之前,为什么先调用move_to_user_mode()?用的是什么方法?解释其中的道理。
- 使其进入用户态。
fork为系统调用,需要在用户态下调用。Linux 规定,除进程 0 之外,所有进程都是由一个已有进程在用户态下完成创建的。- 使用
iret指令进入用户态,因为从内核态跳转到用户态只能使用iret指令,iret为中断返回指令,执行该指令硬件会自动将eip、cs和eflags弹栈,如果需要切换特权级,还需要将esp、ss弹栈。因此在执行iret指令前需要将栈构造好,ss和esp为进程 0 的用户栈段选择子和栈顶指针user_stack,cs和eip为进程 0 的用户代码段选择子和指令指针,指令指针指向从iret返回的下一条指令的地址。cs和ss为进程 0ldt的选择子。
21、copy_process函数的参数最后五项是:long eip,long cs,long eflags,long esp,long ss。查看栈结构确实有这五个参数,奇怪的是其他参数的压栈代码都能找得到,确找不到这五个参数的压栈代码,反汇编代码中也查不到,请解释原因。
copy_process函数是由系统调用来调用的,系统调用是用int 0x80中断实现的,当发生中断时,如果需要进行特权级转换,则硬件自动将ss和esp压栈,然后将eflags、cs和eip压栈。
22、分析get_free_page()函数的代码,叙述在主内存中获取一个空闲页的技术路线。
在
mem_map中从后向前找出引用计数为 0 的第一项,将该项的引用计数置为 1,并通过下标计算空闲页的起始物理地址(LOW_MEM+(index<<12)),从高地址向低地址用 0 填充该页,最后返回该页的起始物理地址。如果所有的引用计数都不为 0,即没有空闲页,则返回 0.
23、分析copy_page_tables()函数的代码,叙述父进程如何为子进程复制页表。
- 要求源地址和目的地址必须按 4MB 对齐;
- 计算源地址和目的地址所在的页目录表项的线性地址;
- 通过所占的地址空间计算所用的页目录表项数;
- 根据页目录表项的起始线性地址和页目录表项数遍历页目录表,对每一个源页目录表项,如果对应的页表存在,则进行以下操作:
- 从页目录表项中取出对应的页表的起始物理地址;
- 为目的页表分配一个空白页,并挂到目的页目录表项上,并将标志设置为用户级的、可读写、存在;
- 计算需要复制的页表项数,如果是内核空间(源地址为 0),则只复制前 160 项(内核空间只占低 640 KB),否则全部复制。
- 遍历页表,对于每一个源页表项,如果对应的页存在,则进行以下操作:
- 从源页表中复制每一项到目的页表,同时置为"只读",以便进行 COW;
- 如果页表项对应的页的地址在 1MB 以上(非内核页面),则将源页表项置为"只读",并在
mem_map中将该页的引用计数加 1;- 重新加载 cr3,刷新 TLB。
24、进程0创建进程1时,为进程1建立了task_struct及内核栈,第一个页表,分别位于物理内存16MB顶端倒数第一页、第二页。请问,这两个页究竟占用的是谁的线性地址空间,内核、进程0、进程1、还是没有占用任何线性地址空间?说明理由(可以图示)并给出代码证据。
占用的是内核的线性地址空间,也即为进程 0、进程 1 位于内核态下的线性地址空间。
在
head.s中,setup_paging函数对内核进行分页,令内核线性地址等于物理地址:setup_paging: // 内核分页,分完以后 线性地址 == 物理地址 // ... movl $pg3+4092,%edi movl $0xfff007,%eax /* 16Mb - 4096 + 7 (r/w user,p) */ // 页表中最后一项对应的地址(一页的起始地址) 线性地址 == 物理地址 std // 方向:edi 递减 1: stosl /* fill pages backwards - more efficient :-) */ // 注意:没有 rep,说明是一项一项地填的 subl $0x1000,%eax // 页表每一项对应一页(0x1000 == 4096) jge 1b // ...由于
get_free_page()分配的是物理地址,因此占用的是内核的线性地址空间。进程 0 用户态的线性地址空间是内存前 640KB,因此无法访问到 16MB 的顶端倒数的两个页,所以占用的不是进程 0 用户态的线性地址空间。
进程 1 拷贝了进程 0 的页表以及 ldt,并修改了 ldt 内描述符的段基址,因此线性空间也被限制在了 640KB 内,同时进程 1 用户态的线性地址不等于物理地址,所以占用的不是进程 1 的线性地址空间。
int copy_mem(int nr,struct task_struct * p) // 做线性和物理内存 { // ... new_data_base = new_code_base = nr * 0x4000000; // nr * 64MB(4GB / 64) p->start_code = new_code_base; set_base(p->ldt[1],new_code_base); // 做子进程的 ldt set_base(p->ldt[2],new_data_base); // 以上为子进程做线性地址空间 // ... }
25、假设:经过一段时间的运行,操作系统中已经有5个进程在运行,且内核分别为进程4、进程5分别创建了第一个页表,这两个页表在谁的线性地址空间?用图表示这两个页表在线性地址空间和物理地址空间的映射关系。

26、代码中的"ljmp %0\n\t" 很奇怪,按理说jmp指令跳转到得位置应该是一条指令的地址,可是这行代码却跳到了"m" (*&__tmp.a),这明明是一个数据的地址,更奇怪的,这行代码竟然能正确执行。请论述其中的道理。
#define switch_to(n) {\
struct {long a,b;} __tmp; \
__asm__("cmpl %%ecx,_current\n\t" \
"je 1f\n\t" \
"movw %%dx,%1\n\t" \
"xchgl %%ecx,_current\n\t" \
"ljmp %0\n\t" \
"cmpl %%ecx,_last_task_used_math\n\t" \
"jne 1f\n\t" \
"clts\n" \
"1:" \
::"m" (*&__tmp.a),"m" (*&__tmp.b), \
"d" (_TSS(n)),"c" ((long) task[n])); \
}
__tmp.a为偏移量,__tmp.b为段选择子,通过movw %%dx,%1\n\t指令将目标进程 TSS 描述符的段选择子赋值到__tmp.b中,ljmp加上 TSS 描述符的选择子和偏移量就跳转到了目标进程中,在这个过程中将 CPU 的各个寄存器值保存在进程 0 的 TSS 中,将进程 1 的 TSS 数据加载到 CPU 的各个寄存器中。
27、进程0开始创建进程1,调用fork(),跟踪代码时我们发现,fork代码执行了两次,第一次,执行fork代码后,跳过init()直接执行了for( ; ; ) pause(),第二次执行fork代码后,执行了init()。奇怪的是,我们在代码中并没有看到向转向fork的goto语句,也没有看到循环语句,是什么原因导致fork反复执行?请说明理由(可以图示),并给出代码证据。
进程 0 调用
fork函数,fork函数使用int 0x80系统调用,系统调用执行copy_process函数;static inline _syscall0(int,fork) #define _syscall0(type,name) \ type name(void) \ { \ long __res; \ __asm__ volatile ("int $0x80" \ : "=a" (__res) \ : "0" (__NR_##name)); \ if (__res >= 0) \ return (type) __res; \ errno = -__res; \ return -1; \ }_system_call: # ... call _sys_call_table(,%eax,4) # ... #define __NR_fork 2 _sys_fork: # ... call _copy_process # 父子进程创建机制 # ...进程 0 为进程 1 构造
task_struct,并执行p->tss.eip = eip;、p->tss.eax = 0;,其中eip指向进程 0 调用中断的下一条指令的地址,即if (__res >= 0);int copy_process(int nr,long ebp,long edi,long esi,long gs,long none, // nr 是进程号,none 是 call sys_fork 时压的返回地址 long ebx,long ecx,long edx, long fs,long es,long ds, long eip,long cs,long eflags,long esp,long ss) // 中断自动压栈 { struct task_struct *p; // ... p = (struct task_struct *) get_free_page(); // ... p->tss.eip = eip; // 父进程进入中断前的下一条指令的地址 // ... p->tss.eax = 0; // 子进程 fork() 的返回值 // ... return last_pid; }进程 0 从
copy_process函数返回,返回值为last_pid,即进程 1 的pid,保存在eax寄存器中;进程 0 从中断返回,
eax寄存器的值为进程 1 的pid,然后从fork函数返回,返回值eax不为 0,跳过init()直接执行了for(;;) pause();进程 0 在
pause函数中被挂起, 由于只有进程 1 处于就绪态, 因此 cpu 调度到进程 1 执行,即将进程 1task_struct中的tss字段的内容加载到 cpu 中;static inline _syscall0(int,pause) int sys_pause(void) { current->state = TASK_INTERRUPTIBLE; // 挂起 schedule(); return 0; } void schedule(void) { // ... switch_to(next); // 实际切换 } #define switch_to(n) {\ struct {long a,b;} __tmp; /* 偏移量,段选择子(ljmp 的参数) */\ __asm__("cmpl %%ecx,_current\n\t" \ "je 1f\n\t" \ "movw %%dx,%1\n\t" \ "xchgl %%ecx,_current\n\t" \ "ljmp %0\n\t" /* 分界 */\ "cmpl %%ecx,_last_task_used_math\n\t" \ "jne 1f\n\t" \ "clts\n" \ "1:" \ ::"m" (*&__tmp.a),"m" (*&__tmp.b), \ "d" (_TSS(n)),"c" ((long) task[n])); /* 目标进程的 tss 的段选择子,目标进程的 task_struct 指针 */\ }cpu 中的
eip为if (__res >= 0)的地址,eax为 0,开始执行,从fork函数返回,返回值eax为 0,执行init()。
28、打开保护模式、分页后,线性地址到物理地址是如何转换的?
- cpu 通过 cr3 寄存器定位到页目录表的物理地址;
- 使用线性地址的高 10 位作为索引在页目录表中定位到某一页目录表项;
- 读出页目录表项的内容,即为页表的物理地址;
- 使用线性地址的中间 10 位作为索引在页表中定位到某一页表项;
- 读出页表项的内容,即为对应的页的起始物理地址;
- 页的起始物理地址加上线性地址的低 12 位即为线性地址对应的物理地址。

29、详细分析进程调度的全过程。考虑所有可能(signal、alarm除外)
void schedule(void) { int i,next,c; struct task_struct ** p; /* check alarm, wake up any interruptible tasks that have got a signal */ // ... /* this is the scheduler proper: */ while (1) { c = -1; next = 0; i = NR_TASKS; p = &task[NR_TASKS]; while (--i) { if (!*--p) continue; if ((*p)->state == TASK_RUNNING && (*p)->counter > c) c = (*p)->counter, next = i; } // 得到就绪态的并且时间片最多的,即进程 1 if (c) break; // 进程 1 有时间片,直接退出 for(p = &LAST_TASK ; p > &FIRST_TASK ; --p) if (*p) (*p)->counter = ((*p)->counter >> 1) + (*p)->priority; } switch_to(next); // 实际切换 }
#define switch_to(n) {\ struct {long a,b;} __tmp; /* 偏移量,段选择子(ljmp 的参数) */\ __asm__("cmpl %%ecx,_current\n\t" \ "je 1f\n\t" \ "movw %%dx,%1\n\t" \ "xchgl %%ecx,_current\n\t" \ "ljmp %0\n\t" /* 分界 */\ "cmpl %%ecx,_last_task_used_math\n\t" \ "jne 1f\n\t" \ "clts\n" \ "1:" \ ::"m" (*&__tmp.a),"m" (*&__tmp.b), \ "d" (_TSS(n)),"c" ((long) task[n])); /* 目标进程的 tss 的段选择子,目标进程的 task_struct 指针 */\ }
- 在
switch_to中,先判断目标进程是否为当前进程,若是,则直接返回,否则将目标进程 TSS 描述符的段选择子赋值到__tmp.b中,设置当前进程为目标进程,使用ljmp加上 TSS 描述符的选择子和偏移量就跳转到了目标进程中。- 当目标进程被调度回来后,判断上个进程是否使用过协处理器,没有则跳转退出,否则清 cr0 中的任务切换。

30、wait_on_buffer函数中为什么不用if()而是用while()?
答案1
- 被调度回来 b_lock 可能还没清零;
- 有可能被其他进程加了 b_lock。
答案2
- 因为可能存在一种情况是,很多进程都在等待一个缓冲块。在缓冲块同步完毕,唤醒各等待进程到轮转到某一进程的过程中,很有可能此时的缓冲块又被其它进程所占用,并被加上了锁。此时如果用if(),则此进程会从之前被挂起的地方继续执行,不会再判断是否缓冲块已被占用而直接使用,就会出现错误;而如果用while(),则此进程会再次确认缓冲块是否已被占用,在确认未被占用后,才会使用,这样就不会发生之前那样的错误
31、add_reques()函数中有下列代码
if (!(tmp = dev->current_request)) {
dev->current_request = req;
sti();
(dev->request_fn)();
return;
}
其中的
if (!(tmp = dev->current_request)) {
dev->current_request = req;
是什么意思?
检查设备是否正忙,若目前该设备没有请求项,本次是唯一一个请求,之前无链表,则将该设备当前请求项指针直接指向该请求项,作为链表的表头。
32、do_hd_request()函数中dev的含义始终一样吗?
122 页 不一样。
答: 不是一样的。 dev/=5 之前表示当前硬盘的逻辑盘号。 这行代码之后表示的实际的物理设备号。
33、read_intr()函数中,下列代码是什么意思?为什么这样做?
if (--CURRENT->nr_sectors) {
do_hd = &read_intr;
return;
}
34、bread()函数代码中为什么要做第二次if (bh->b_uptodate)判断?
if (bh->b_uptodate)
return bh;
ll_rw_block(READ,bh);
wait_on_buffer(bh);
if (bh->b_uptodate)
return bh;
有可能发生读设备操作失败。
“It returns NULL if the block was unreadable.”
35、getblk()函数中,两次调用wait_on_buffer()函数,两次的意思一样吗?
答: 一样。 都是等待缓冲块解锁。
第一次调用是在, 已经找到一个比较合适的空闲缓冲块, 但是此块可能是加锁的, 于是等待该缓冲块解锁。
第二次调用, 是找到一个缓冲块, 但是此块被修改过, 即是脏的, 还有其他进程在写或此块等待把数据同步到硬盘上, 写完要加锁, 所以此处的调用仍然是等待缓冲块解锁。
36、getblk()函数中
do {
if (tmp->b_count)
continue;
if (!bh || BADNESS(tmp)b_next_free) != free_list);
说明什么情况下执行continue、break。
- 如果遍历到的缓冲块头数据结构表示该缓冲块被引用,则执行
continue;- 如果遍历到的缓冲块头数据结构表示该缓冲块既不脏也没有被锁定,则执行
break。(P114代码)
37、make_request()函数
if (req < request) {
if (rw_ahead) {
unlock_buffer(bh);
return;
}
sleep_on(&wait_for_request);
goto repeat;
其中的sleep_on(&wait_for_request)是谁在等?等什么?
当前进程等待空闲请求项。
make_request()函数创建请求项并插入请求队列,执行if的内容说明没有找到空请求项:如果是超前的读写请求,因为是特殊情况则放弃请求直接释放缓冲区,否则是一般的读写操作,此时等待直到有空闲请求项,然后从repeat开始重新查看是否有空闲的请求项。
38.在head程序执行结束的时候,在idt的前面有184个字节的head程序的剩余代码,剩余了什么?为什么要剩余?
剩余代码:
包含代码段如下after_page_tables(栈中压入了些参数)、 ignore_int(初始化中断时的中断处理函数) 和 setup_paging(初始化分页)。
剩余的原因:
after_page_tables 中压入的参数,为内核进入 main 函数的跳转做准备。设计者在栈中压入了 L6: main,以使得系统出错时,返回到 L6 处执行。
ignore_int 为中断处理函数,使用 ignore_int 将 idt 全部初始化,如果中断开启后存在使用了未设置的中断向量,那么将默认跳转到 ignore_int 处执行,使得系统不会跳转到随机的地方执行错误的代码。
setup_paging 进行初始化分页,在该函数中对 0x0000 和 0x5000 的进行了初始化操作。该代码用于跳转到 main,即执行“ret”指令。
39.在Linux操作系统中大量使用了中断、异常类的处理,究竟有什么好处?
采用以“被动模式” 代替“主动轮询” 模式来处理终端问题。进程在主机中运算需用到 CPU,其中可能进行“异常处理” ,此时需要具体的服务程序来执行。 这种中断服务体系的建立是为了被动响应中断信号。因此, CPU 就可以更高效的处理用户程序服务, 不用考虑随机可能产生的中断信号,从而提高了操作系统的综合效率。
40、getblk函 数中,申请空闲缓冲块的标准就是b_count为0,而申请到之后,为什么在wait_on_buffer(bh)后又执行if(bh->b_count)来判断b_count是否为0?
P114参考,考试不用看
wait_on_buffer(bh)内包含睡眠函数,虽然此时已经找到比较合适的空闲缓冲块,但是可能在睡眠阶段该缓冲区被其他任务所占用,因此必须重新搜索,判断是否被修改,修改则写盘等待解锁。判断若被占用则重新repeat,继续执行if(bh->b_count)
41、b_dirt已经被置为1的缓冲块,同步前能够被进程继续读、写?给出代码证据。
同步前能够被进程继续读、写
b_uptodate设置为1后,内核就可以支持进程共享该缓冲块的数据了,读写都可以,读操作不会改变缓冲块的内容,所以不影响数据,而执行写操作后,就改变了缓冲块的内容,就要将b_dirt标志设置为1。由于此前缓冲块中的数据已经用硬盘数据块更新了,所以后续的同步未被改写的部分不受影响,同步是不更改缓冲块中数据的,所以b_uptodate仍为1。即进程在b_dirt置为1时,仍能对缓冲区数据进行读写。
代码证据:代码P331
42、分析panic函数的源代码,根据你学过的操作系统知识,完整、准确的判断panic函数所起的作用。假如操作系统设计为支持内核进程(始终运行在0特权级的进程),你将如何改进panic函数?
panic()函数是当系统发现无法继续运行下去的故障时将调用它,会导致程序终止,然后由系统显示错误号。如果出现错误的函数不是进程0,那么就要进行数据同步,把缓冲区中的数据尽量同步到硬盘上。遵循了Linux尽量简明的原则。
改进panic函数:将死循环for(;;改进为跳转到内核进程(始终运行在0特权级的进程),让内核继续执行。
代码: kernel/panic.c
#include 43、操作系统如何利用b_uptodate保证缓冲块数据的正确性?new_block (int dev)函数新申请一个缓冲块后,并没有读盘,b_uptodate却被置1,是否会引起数据混乱?详细分析理由。
答:b_uptodate是缓冲块中针对进程方向的标志位,它的作用是告诉内核,缓冲块的数据是否已是数据块中最新的。当b_update置1时,就说明缓冲块中的数据是基于硬盘数据块的,内核可以放心地支持进程与缓冲块进行数据交互;如果b_uptodate为0,就提醒内核缓冲块并没有用绑定的数据块中的数据更新,不支持进程共享该缓冲块。
当为文件创建新数据块,新建一个缓冲块时,b_uptodate被置1,但并不会引起数据混乱。此时,新建的数据块只可能有两个用途,一个是存储文件内容,一个是存储文件的i_zone的间接块管理信息。
如果是存储文件内容,由于新建数据块和新建硬盘数据块,此时都是垃圾数据,都不是硬盘所需要的,无所谓数据是否更新,结果“等效于”更新问题已经解决。
如果是存储文件的间接块管理信息,必须清零,表示没有索引间接数据块,否则垃圾数据会导致索引错误,破坏文件操作的正确性。虽然缓冲块与硬盘数据块的数据不一致,但同样将b_uptodate置1不会有问题。
综合以上考虑,设计者采用的策略是,只要为新建的数据块新申请了缓冲块,不管这个缓冲块将来用作什么,反正进程现在不需要里面的数据,干脆全部清零。这样不管与之绑定的数据块用来存储什么信息,都无所谓,将该缓冲块的b_uptodate字段设置为1,更新问题“等效于”已解决
44、为什么static inline _syscall0(type,name)中需要加上关键字inline?
答:因为_syscall0(int,fork)展开是一个真函数,普通真函数调用事需要将eip入栈,返回时需要讲eip出栈。inline是内联函数,它将标明为inline的函数代码放在符号表中,而此处的fork函数需要调用两次,加上inline后先进行词法分析、语法分析正确后就地展开函数,不需要有普通函数的call\ret等指令,也不需要保持栈的eip,效率很高。若不加上inline,第一次调用fork结束时将eip 出栈,第二次调用返回的eip出栈值将是一个错误值。
答案2:inline一般是用于定义内联函数,内联函数结合了函数以及宏的优点,在定义时和函数一样,编译器会对其参数进行检查;在使用时和宏类似,内联函数的代码会被直接嵌入在它被调用的地方,这样省去了函数调用时的一些额外开销,比如保存和恢复函数返回地址等,可以加快速度。
45、根据代码详细说明copy_process函数的所有参数是如何形成的?
答:
long eip, long cs, long eflags, long esp, long ss;这五个参数是中断使CPU自动压栈的。
long ebx, long ecx, long edx, long fs, long es, long ds为__system_call压进栈的参数。
long none 为__system_call调用__sys_fork压进栈EIP的值。
Int nr, long ebp, long edi, long esi, long gs,为__system_call压进栈的值。
额外注释:
一般在应用程序中,一个函数的参数是由函数定义的,而在操作系统底层中,函数参数可以由函数定义以外的程序通过压栈的方式“做”出来。copy_process函数的所有参数正是通过压栈形成的。代码见P83页、P85页、P86页。
46、进程0创建进程1时调用copy_process函数,在其中直接、间接调用了两次get_free_page函数,在物理内存中获得了两个页,分别用作什么?是怎么设置的?给出代码证据。
答:
第一次调用get_free_page函数申请的空闲页面用于进程1 的task_struct及内核栈。首先将申请到的页面清0,然后复制进程0的task_struct,再针对进程1作个性化设置,其中esp0 的设置,意味着设置该页末尾为进程 1 的堆栈的起始地址。代码见P90 及 P92。
kenel/fork.c:copy_process
p = (struct task_struct *)get_free_page();
*p = *current
p->tss.esp0 = PAGE_SIZE + (long)p;
第二次调用get_free_page函数申请的空闲页面用于进程1的页表。在创建进程1执行copy_process中,执行copy_mem(nr,p)时,内核为进程1拷贝了进程 0的页表(160 项),同时修改了页表项的属性为只读。代码见P98。
mm/memory.c: copy_page_table
if(!(to_page_table = (unsigned long *)get_free_page()))
return -1;
*to_dir = ((unsigned long)to_page_table) | 7;
47、用户进程自己设计一套LDT表,并与GDT挂接,是否可行,为什么?
答:
不可行
GDT和LDT放在内核数据区,属于0特权级,3特权级的用户进程无权访问修改。此外,如果用户进程可以自己设计LDT的话,表明用户进程可以访问其他进程的LDT,则会削弱进程之间的保护边界,容易引发问题。
补充:
如果仅仅是形式上做一套和GDT,LDT一样的数据结构是可以的。但是真正其作用的GDT、LDT是CPU硬件认定的,这两个数据结构的首地址必须挂载在CPU中的GDTR、LDTR上,运行时CPU只认GDTR和LDTR指向的数据结构。而对GDTR和LDTR的设置只能在0特权级别下执行,3特权级别下无法把这套结构挂接在CR3上。
LDT表只是一段内存区域,我们可以构造出用户空间的LDT。而且Ring0代码可以访问Ring3数据。但是这并代表我们的用户空间LDT可以被挂载到GDT上。考察挂接函数set_ldt_desc:1)它是Ring0代码,用户空间程序不能直接调用;2)该函数第一个参数是gdt地址,这是Ring3代码无权访问的,又因为gdt 很可能不在用户进程地址空间,就算有权限也是没有办法寻址的。3)加载ldt所用到的特权指令lldt也不是Ring3代码可以任意使用的。
48、为什么get_free_page()将新分配的页面清0?P265
因为无法预知这页内存的用途,如果用作页表,不清零就有垃圾值,就是隐患。
答2:Linux在回收页面时并没有将页面清0,只是将mem_map中与该页对应的位置0。在使用get_free_page申请页时,也是遍历mem_map寻找对应位为0的页,但是该页可能存在垃圾数据,如果不清0的话,若将该页用做页表,则可能导致错误的映射,引发错误,所以要将新分配的页面清0。
49、内核和普通用户进程并不在一个线性地址空间内,为什么仍然能够访问普通用户进程的页面?P271
答:内核的线性地址空间和用户进程不一样,内核是不能通过跨越线性地址访问进程的,但由于早就占有了所有的页面,而且特权级是0,所以内核执行时,可以对所有的内容进行改动,“等价于”可以操作所有进程所在的页面。
50、为什么要设计缓冲区,有什么好处?
答:
缓冲区的作用主要体现在两方面:
① 形成所有块设备数据的统一集散地,操作系统的设计更方便,更灵活;
② 数据块复用,提高对块设备文件操作的运行效率。在计算机中,内存间的数据交换速度是内存与硬盘数据交换速度的2个量级,如果某个进程将硬盘数据读到缓冲区之后,其他进程刚好也需要读取这些数据,那么就可以直接从缓冲区中读取,比直接从硬盘读取快很多。如果缓冲区的数据能够被更多进程共享的话,计算机的整体效率就会大大提高。同样,写操作类似。
51、copy_mem()和copy_page_tables()在第一次调用时是如何运行的?
答:copy_mem()的第一次调用是进程0创建进程1时,它先提取当前进程(进程0)的代码段、数据段的段限长,并将当前进程(进程0)的段限长赋值给子进程(进程1)的段限长。然后提取当前进程(进程0)的代码段、数据段的段基址,检查当前进程(进程0)的段基址、段限长是否有问题。接着设置子进程(进程1)的LDT段描述符中代码段和数据段的基地址为nr(1)*64MB。最后调用copy_page_table()函数
copy_page_table()的参数是源地址、目的地址和大小,首先检测源地址和目的地址是否都是4MB的整数倍,如不是则报错,不符合分页要求。然后取源地址和目的地址所对应的页目录项地址,检测如目的地址所对应的页目录表项已被使用则报错,其中源地址不一定是连续使用的,所以有不存在的跳过。接着,取源地址的页表地址,并为目的地址申请一个新页作为子进程的页表,且修改为已使用。然后,判断是否源地址为0,即父进程是否为进程0 ,如果是,则复制页表项数为160,否则为1k。最后将源页表项复制给目的页表,其中将目的页表项内的页设为“只读”,源页表项内的页地址超过1M的部分也设为"只读"(由于是第一次调用,所以父进程是0,都在1M内,所以都不设为“只读”),并在mem_map中所对应的项引用计数加1。1M内的内核区不参与用户分页管理。
52、用图表示下面的几种情况,并从代码中找到证据:
-
A当进程获得第一个缓冲块的时候,hash表的状态
-
B经过一段时间的运行。已经有2000多个buffer_head挂到hash_table上时,hash表(包括所有的buffer_head)的整体运行状态。
-
C经过一段时间的运行,有的缓冲块已经没有进程使用了(空闲),这样的空闲缓冲块是否会从hash_table上脱钩?
-
D经过一段时间的运行,所有的buffer_head都挂到hash_table上了,这时,又有进程申请空闲缓冲块,将会发生什么?
-
A
getblk(int dev, int block) à get_hash_table(dev,block) -> find_buffer(dev,block) -> hash(dev, block)
哈希策略为:
#define _hashfn(dev,block)(((unsigned)(dev block))%NR_HASH)
#define hash(dev,block) hash_table[_hashfn(dev, block)]
此时,dev为0x300,block为0,NR_HASH为307,哈希结果为154,将此块插入哈希表中次位置后
- B
//代码路径 :fs/buffer.c:
…
static inline void insert_into_queues(struct buffer_head * bh) {undefined
/*put at end of free list */
bh->b_next_free= free_list;
bh->b_prev_free= free_list->b_prev_free;
free_list->b_prev_free->b_next_free= bh;
free_list->b_prev_free= bh;
/*put the buffer in new hash-queue if it has a device */
bh->b_prev= NULL;
bh->b_next= NULL;
if (!bh->b_dev)
return;
bh->b_next= hash(bh->b_dev,bh->b_blocknr);
hash(bh->b_dev,bh->b_blocknr)= bh;
bh->b_next->b_prev= bh
}
- C
不会脱钩,会调用brelse()函数,其中if(!(buf->b_count–)),计数器减一。没有对该缓冲块执行remove操作。由于硬盘读写开销一般比内存大几个数量级,因此该空闲缓冲块若是能够再次被访问到,对提升性能是有益的。 - D
进程顺着freelist找到没被占用的,未被上锁的干净的缓冲块后,将其引用计数置为1,然后从hash队列和空闲块链表中移除该bh,然后根据此新的设备号和块号重新插入空闲表和哈西队列新位置处,最终返回缓冲头指针。
Bh->b_count=1;
Bh->b_dirt=0;
Bh->b_uptodate=0;
Remove_from_queues(bh);
Bh->b_dev=dev;
Bh->b_blocknr=block;
Insert_into_queues(bh);
53、在虚拟盘被设置为根设备之前,操作系统的根设备是软盘,请说明设置软盘为根设备的技术路线。
答:首先,将软盘的第一个山区设置为可引导扇区:
(代码路径:boot/bootsect.s) boot_flag: .word 0xAA55
在主Makefile文件中设置ROOT_DEV=/dev/hd6。并且在bootsect.s中的508和509处设置ROOT_DEV=0x306;在tools/build中根据Makefile中的ROOT_DEV设置MAJOR_TOOT和MINOR_ROOT,并将其填充在偏移量为508和509处:
(代码路径:Makefile) tools/build boot/bootsect boot/setup tools/system $(ROOT_DEV) > Image
随后被移至0x90000+508(即0x901FC)处,最终在main.c中设置为ORIG_ROOT_DEV并将其赋给ROOT_DEV变量:
(代码路径:init/main.c)
62 #define ORIG_ROOT_DEV (*(unsigned short *)0x901FC)
113 ROOT_DEV = ORIG_ROOT_DEV;