简单回归模型(二):OLS最小二乘法
简单回归模型(二)
拟合优度
已知: y i = y ^ i + u ^ i y_i=\hat y_i+\hat u_i yi=y^i+u^i,可以把OLS分成拟合值和残差两个部分,在样本中,拟合值和残差是不相关的。定义总平方和(SST)、解释平方和(SSE),和**残差平方和(SSR)**如下:
S S T = ∑ i = 1 n ( y i − y ˉ ) 2 SST=\sum_{i=1}^{n}(y_i-\bar y)^2 SST=i=1∑n(yi−yˉ)2
S S R = ∑ i = 1 n ( y ^ i − y ˉ ) 2 SSR=\sum_{i=1}^{n}(\hat y_i-\bar y)^2 SSR=i=1∑n(y^i−yˉ)2
S S R = ∑ i = 1 n u i 2 = ∑ i − 1 n ( y i − y ˉ ) 2 SSR=\sum_{i=1}^{n}u_i^2=\sum_{i-1}^{n}(y_i-\bar y)^2 SSR=i=1∑nui2=i−1∑n(yi−yˉ)2
容易证得: S S T = S S E + S S R SST=SSE+SSR SST=SSE+SSR
假定总平方和SST不为零,我们可以通过将方程两边同时除以SST得到 1 = S S E / S S T + S S R / S S T 1=SSE/SST+SSR/SST 1=SSE/SST+SSR/SST。回归的 R 2 R^2 R2有时又被称为判定系数,是被解释波动与总波动之比,被定义为:
R 2 = S S E / S S T = 1 − S S R / S S T R^2=SSE/SST=1-SSR/SST R2=SSE/SST=1−SSR/SST
根据该方程, R 2 R^2 R2的值总是介于0和1之间。若所有数据点都落在同一条直线上,此时 R 2 = 1 R^2=1 R2=1;同理,一个接近于零的 R 2 R^2 R2给出了一个糟糕的拟合,因为 y i y_i yi的波动极少能被 y ˉ \bar y yˉ所解释(后者全部落在OLS回归线上)。另外,可以证明 R 2 R^2 R2等于 y i y_i yi和 x i x_i xi样本相关系数的平方:
R 2 = ∑ i = 1 n y ^ i 2 ∑ i = 1 n y i 2 = β ^ 1 2 ∑ i = 1 n x i 2 ∑ i = 1 n y i 2 = ⋯ = r 2 R^2=\frac{\sum_{i=1}^n\hat y_i^2}{\sum_{i=1}^ny_i^2}=\frac{\hat \beta_1^2\sum_{i=1}^n x_i^2}{\sum_{i=1}^ny_i^2}=\cdots=r^2 R2=∑i=1nyi2∑i=1ny^i2=∑i=1nyi2β^12∑i=1nxi2=⋯=r2
(太麻烦了不写了)
注意: R 2 R^2 R2不能作为评价计量分析成功与否的主要准则!
度量单位与函数形式
当自变量和因变量的单位发生变化时,OLS的估计值也会发生变化。一般的自变量被除以或乘以一个非零的常数c时,OLS的斜率和截距也会分别被乘以或除以c,但判定系数 R 2 R^2 R2不会因y或x的单位变化而变化。
我们也可以把许多非线性因素引入到简单回归分析之中,例如:对于一个变量为非线性形式的模型: Y = β 0 X 1 β Y=\beta_0X^\beta_1 Y=β0X1β,我们可以通过一定的函数变换得到一个新的模型,如 l n Y = l n β 0 + β 1 l n X lnY=ln\beta_0+\beta_1lnX lnY=lnβ0+β1lnX,令 W = l n Y W=lnY W=lnY, Z = l n X Z=lnX Z=lnX, α 0 = l n β 0 \alpha_0=ln\beta_0 α0=lnβ0,就能够得到 W = α 0 + β 1 Z W=\alpha_0+\beta_1Z W=α0+β1Z。再对上式进行OLS估计,可以得到 β 1 \beta_1 β1的无偏估计量 β ^ 1 \hat \beta_1 β^1和 α 0 \alpha_0 α0的无偏估计量 α ^ 0 \hat \alpha_0 α^0。
但是通过上述变换却无法得到 β 1 \beta_1 β1的无偏估计量 β ^ 1 \hat \beta_1 β^1,因为 e α ^ 0 e^{\hat \alpha_0} eα^0并不是 β 0 \beta_0 β0的一个好的估计量。然而,在回归分析中一般都关心斜率系数而不是截距系数,因此我们只要能够正确估计出 β 1 \beta_1 β1,仍然可以看作是一个线性模型。
对解释变量进行某种形式的函数变换,不会改变模型的参数线性,但会使得模型的经济意义更加合理。主要有一下三种常用的函数形式:
| 模型 | 因变量 | 自变量 | 对 β 1 \beta_1 β1的解释 |
|---|---|---|---|
| 水平值-水平值 | y | x | △ y = β 1 △ x \triangle y=\beta_1\triangle x △y=β1△x |
| 水平值-对数 | y | log(x) | △ y = ( β 1 / 100 ) % △ x \triangle y=(\beta_1/100)\%\triangle x △y=(β1/100)%△x |
| 对数-水平值 | log(y) | x | % △ y = ( 100 β 1 ) △ x \%\triangle y=(100\beta_1)\triangle x %△y=(100β1)△x |
| 对数-对数 | log(y) | log(x) | % △ y = β 1 % △ x \%\triangle y=\beta_1\%\triangle x %△y=β1%△x |
过原点回归
在分析问题时,有些情况我们希望x=0时y=0,这时得到的方程 y ˉ = β ˉ 1 x \bar y=\bar \beta_1 x yˉ=βˉ1x又被称为过原点回归。通过最小化残差平方和的一阶条件,我们可以得到
β ˉ 1 = ∑ i = 1 n x i y i ∑ i = 1 n x i 2 \bar \beta_1=\frac{\sum_{i=1}^nx_iy_i}{\sum_{i=1}^nx_i^2} βˉ1=∑i=1nxi2∑i=1nxiyi
(分子不为零)
同样的,判定系数
R 2 = 1 − ∑ i = 1 n ( y i − β ˉ 1 x i ) 2 ∑ i = 1 n y i 2 R^2=1-\frac{\sum_{i=1}^n(y_i-\bar \beta_1x_i)^2}{\sum_{i=1}^ny_i^2} R2=1−∑i=1nyi2∑i=1n(yi−βˉ1xi)2
使用过原点回归需要非常强的前提条件,在实际分析中应用不多。
估计量的性质
高斯-马尔科夫假定
定理:对于线性回归模型,在某些约束条件下,由最小二乘法得到的估计量(估计子),即线性回归模型的系数,是最优的线性无偏估计子。
为了判断点估计的无偏性、有效性等性质,需要对模型做出一些假定
1.线性于参数: y = β 0 + β 1 x + u y=\beta_0+\beta_1x+u y=β0+β1x+u
2.随机抽样:从总体中随机抽取样本,样本容量为n。同时,可以把随机样本的形式将方程写为: y i = β 0 + β 1 x i + u i y_i=\beta_0+\beta_1x_i+u_i yi=β0+β1xi+ui,其中 u i u_i ui是第i次观测时的误差或干扰。
3.解释变量的样本有波动:即 x i x_i xi的标准差不为零。
4.零条件均值假定:对给定任何x值,误差的期望都为零: E ( u ∣ x ) = 0 E(u|x)=0 E(u∣x)=0
OLS估计量的无偏性
基于以上四个假定,可以证明出OLS估计量的无偏性:
首先,我们把 β 1 \beta_1 β1的估计量改写为
β ^ 1 = ∑ i = 1 n ( x i − x ˉ ) y i ∑ i = 1 n ( x i − x ˉ ) 2 \hat \beta_1=\frac{\sum_{i=1}^n(x_i-\bar x)y_i}{\sum_{i=1}^n(x_i-\bar x)^2} β^1=∑i=1n(xi−xˉ)2∑i=1n(xi−xˉ)yi
将随驾抽样形式的方程代入:其中 S S T X = ∑ i = 1 n ( x i − x ˉ ) 2 SST_X=\sum_{i=1}^n(x_i-\bar x)^2 SSTX=∑i=1n(xi−xˉ)2
β ^ 1 = ∑ i = 1 n ( x i − x ˉ ) ( β 0 + β 1 x i + u i ) S S T x = β 0 ∑ i = 1 n ( x I − x ˉ ) + β 1 ∑ i = 1 n ( x i − x ˉ ) x i + ∑ i = 1 n ( x i − x ˉ ) u i S S T x = β 1 S S T x + ∑ i = 1 n ( x i − x ˉ ) u i S S T x \hat \beta_1=\frac{\sum_{i=1}^n(x_i-\bar x)(\beta_0+\beta_1x_i+u_i)}{SST_x}=\frac{\beta_0\sum_{i=1}^n(x_I-\bar x)+\beta_1\sum_{i=1}^n(x_i-\bar x)x_i+\sum_{i=1}^n(x_i-\bar x)u_i}{SST_x}=\frac{\beta_1SST_x+\sum_{i=1}^n(x_i-\bar x)u_i}{SST_x} β^1=SSTx∑i=1n(xi−xˉ)(β0+β1xi+ui)=SSTxβ0∑i=1n(xI−xˉ)+β1∑i=1n(xi−xˉ)xi+∑i=1n(xi−xˉ)ui=SSTxβ1SSTx+∑i=1n(xi−xˉ)ui
进一步整理,得到
β ^ 1 = β 1 + ( 1 / S S T x ) ∑ i = 1 n d i u i \hat \beta_1=\beta_1+(1/SST_x)\sum_{i=1}^n d_i u_i β^1=β1+(1/SSTx)i=1∑ndiui
其中 d i = x i − x ˉ d_i=x_i-\bar x di=xi−xˉ
得到上式,就可证明出OLS的无偏性:
**定理:**基于假定1-4,对任意 β 1 \beta_1 β1和 β 0 \beta_0 β0都有 E ( β ^ 0 ) = β 0 E(\hat \beta_0)=\beta_0 E(β^0)=β0, E ( β ^ 1 ) = β 1 E(\hat \beta_1)=\beta_1 E(β^1)=β1。
E ( β ^ 1 ) = β 1 + E [ ( 1 / S S T x ) ∑ i = 1 n d i u i ] = β 1 + ( 1 / S S T x ) ∑ i = 1 n E ( d i u i ) = β 1 + ( 1 / S S T x ) ∑ i = 1 n d i E ( u i ) = β 1 + ( 1 / S S T x ) ∑ i = 1 n d i ⋅ 0 = β 1 \begin{array}{c} \mathrm{E}\left(\hat{\beta}_{1}\right)=\beta_{1}+\mathrm{E}\left[\left(1 / \mathrm{SST}_{x}\right) \sum_{i=1}^{n} d_{i} u_{i}\right]=\beta_{1}+\left(1 / \mathrm{SST}_{x}\right) \sum_{i=1}^{n} \mathrm{E}\left(d_{i} u_{i}\right) \\ =\beta_{1}+\left(1 / \mathrm{SST}_{x}\right) \sum_{i=1}^{n} d_{i} \mathrm{E}\left(u_{i}\right)=\beta_{1}+\left(1 / \mathrm{SST}_{x}\right) \sum_{i=1}^{n} d_{i} \cdot 0=\beta_{1} \end{array} E(β^1)=β1+E[(1/SSTx)∑i=1ndiui]=β1+(1/SSTx)∑i=1nE(diui)=β1+(1/SSTx)∑i=1ndiE(ui)=β1+(1/SSTx)∑i=1ndi⋅0=β1
β ^ 0 = y ˉ − β ^ 1 x ˉ = β 0 + β 1 x ˉ + u ˉ − β ^ 1 x ˉ = β 0 + ( β 1 − β ^ 1 ) x + u 据假定 2 和 4 , 有 E ( u ˉ ) = 0 , 于是以 x i 的值为条 E ( β ^ 0 ) = β 0 + E [ ( β 1 − β ^ 1 ) x ˉ ] + E ( u ˉ ) = β 0 + E [ ( β 1 − β ^ 1 ) ] x ˉ = β 1 \begin{aligned} &\hat{\beta}_{0}=\bar{y}-\hat{\beta}_{1} \bar{x}=\beta_{0}+\beta_{1} \bar{x}+\bar{u}-\hat{\beta}_{1} \bar{x}=\beta_{0}+\left(\beta_{1}-\hat{\beta}_{1}\right) x+u\\ &\text { 据假定} 2 \text { 和 } 4, \text { 有 } \mathrm{E}(\bar{u})=0, \text { 于是以 } x_{i} \text { 的值为条 }\\ &\mathrm{E}\left(\hat{\beta}_{0}\right)=\beta_{0}+\mathrm{E}\left[\left(\beta_{1}-\hat{\beta}_{1}\right) \bar{x}\right]+\mathrm{E}(\bar{u})=\beta_{0}+\mathrm{E}\left[\left(\beta_{1}-\hat{\beta}_{1}\right)\right] \bar{x}=\beta_1 \end{aligned} β^0=yˉ−β^1xˉ=β0+β1xˉ+uˉ−β^1xˉ=β0+(β1−β^1)x+u 据假定2 和 4, 有 E(uˉ)=0, 于是以 xi 的值为条 E(β^0)=β0+E[(β1−β^1)xˉ]+E(uˉ)=β0+E[(β1−β^1)]xˉ=β1
证毕。
OLS估计量的方差
结果表明,在假定1至4下,OLS估计量的方差可以计算出来。不过,这些表达式多少有些复杂。有鉴于此,我们增加一个在横截面分析中的传统假定。这个假定要求,以x为条件,无法观测变量u的方差是一一个常数。这就是同方差(homoskedasticity) 或“常方差”假定。
假定5(同方差性):对任意x,误差都具有相同的方差,即 V a r ( u ∣ x ) = σ 2 Var(u|x)=\sigma^2 Var(u∣x)=σ2(误差方差)

相反的,当 V a r ( u ∣ x ) Var(u|x) Var(u∣x)取决于x时,便称误差项表现为异方差性。由于 V a r ( u ∣ x ) = V a r ( y ∣ x ) Var(u|x)=Var(y|x) Var(u∣x)=Var(y∣x),所以只要 V a r ( y ∣ x ) Var(y|x) Var(y∣x)是x的函数,便表现出异方差性。
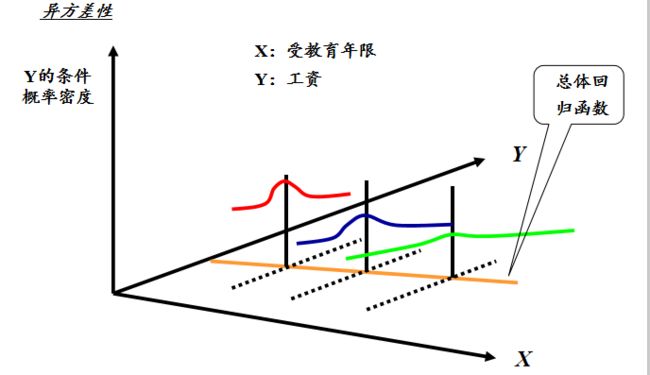
定理:OLS估计量的抽样方差
在假定1-5下,我们有
V a r ( β ^ 1 ) = σ 2 / S S T x Var(\hat \beta_1)=\sigma^2/SST_x Var(β^1)=σ2/SSTx
V a r ( β ^ 0 ) = σ 2 n − 1 ∑ i = 1 n x i 2 ∑ i = 1 n ( x i − x ˉ ) 2 Var(\hat \beta_0)=\frac{\sigma^2n^{-1}\sum_{i=1}^nx_i^2}{\sum_{i=1}^n(x_i-\bar x)^2} Var(β^0)=∑i=1n(xi−xˉ)2σ2n−1∑i=1nxi2
证明:
Var ( β ^ 1 ) = ( 1 / SST x ) 2 Var ( ∑ i = 1 n d i u i ) = ( 1 / S S T x ) 2 ( ∑ i = 1 ∞ d ′ Var ( u i ) ) = ( 1 / S S T x ) 2 ( ∑ i = 1 n d i 2 σ 2 ) [ 因为 Var ( u i ) = σ 2 , ∀ i ] = σ 2 ( 1 / S S T x ) 2 ( ∑ i = 1 n d i 2 ) = σ 2 ( 1 / S S T x ) 2 S S T , = σ / S S T x \begin{aligned} \operatorname{Var}\left(\hat{\beta}_{1}\right) &=\left(1 / \operatorname{SST}_{x}\right)^{2} \operatorname{Var}\left(\sum_{i=1}^{n} d_{i} u_{i}\right)=\left(1 / \mathrm{SST}_{x}\right)^{2}\left(\sum_{i=1}^{\infty} d^{\prime} \operatorname{Var}\left(u_{i}\right)\right) \\ &=\left(1 / \mathrm{SST}_{x}\right)^{2}\left(\sum_{i=1}^{n} d_{i}^{2} \sigma^{2}\right)\left[\text { 因为 } \operatorname{Var}\left(u_{i}\right)=\sigma^{2}, \forall i\right] \\ &=\sigma^{2}\left(1 / \mathrm{SST}_{x}\right)^{2}\left(\sum_{i=1}^{n} d_{i}^{2}\right)=\sigma^{2}\left(1 / \mathrm{SST}_{x}\right)^{2} \mathrm{SST},=\sigma / \mathrm{SST}_{x} \end{aligned} Var(β^1)=(1/SSTx)2Var(i=1∑ndiui)=(1/SSTx)2(i=1∑∞d′Var(ui))=(1/SSTx)2(i=1∑ndi2σ2)[ 因为 Var(ui)=σ2,∀i]=σ2(1/SSTx)2(i=1∑ndi2)=σ2(1/SSTx)2SST,=σ/SSTx
( V a r ( β ^ 0 ) Var(\hat \beta_0) Var(β^0)同理)
证毕
我们可以看出,误差方差越大, V a r ( β ^ 1 ) Var(\hat \beta_1) Var(β^1)就越大:影响y的不可观测因素波动越大,要准确估计 β 1 \beta_1 β1也就越难;自变量波动越大, V a r ( β ^ 1 ) Var(\hat \beta_1) Var(β^1)也就越小,x的样本越分散,越容易估计出 β 1 \beta_1 β1,因此,较大的样本容量会使 β ^ 1 \hat \beta_1 β^1的方差越小。
误差方差的估计
待更