日常学习记录——支持向量机、随机森林对鸢尾花数据集进行分类
日常学习记录——支持向量机、随机森林对鸢尾花数据集进行分类
- 前言
- 1 实验结果及分析
-
- 1.1 支持向量机对鸢尾花数据集分类效果
- 1.2 随机森林对鸢尾花数据集分类效果
- 1.3 实验小结
- 2 实验代码
-
- 2.1 SVM实验代码
- 2.2 随机森林实验代码
- 3 实验遇到的问题总结
-
- 3.1 数据归一化处理
- 3.2 背景色显示不全
前言
本文采用支持向量机和随机森林算法对鸢尾花数据集进行了分类实验,实验结果表明,对于鸢尾花数据集来说,支持向量机的分类效果会更好,分类正确率达到100%,且没有出现过拟合的现象。
主要参考文献如下:
1、机器学习SVM:基于Python实现的鸢尾花分类问题
2、【集成学习】随机森林实现鸢尾花分类
提示:以下是本篇文章正文内容,下面案例可供参考
1 实验结果及分析
1.1 支持向量机对鸢尾花数据集分类效果
分类正确率为100%,其中各类别的分类效果如表1、图1所示。
| 类别 | precision | recall | f1-score | support |
|---|---|---|---|---|
| 山鸢尾 | 1.00 | 1.00 | 1.00 | 17 |
| 变色鸢尾 | 1.00 | 1.00 | 1.00 | 13 |
| 维吉尼亚鸢尾 | 1.00 | 1.00 | 1.00 | 8 |
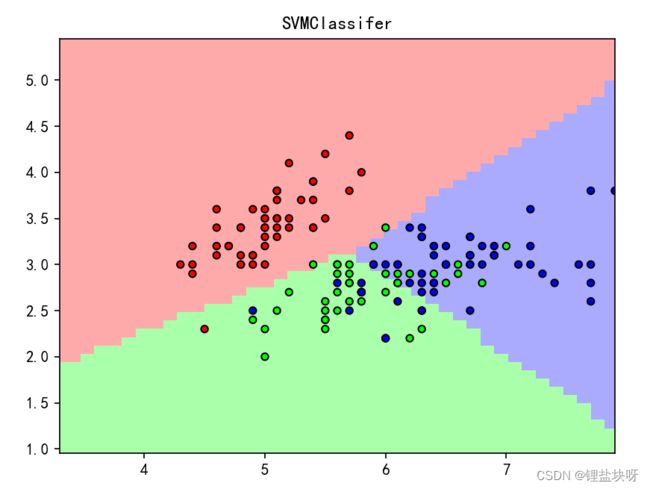
1.2 随机森林对鸢尾花数据集分类效果
分类正确率为97.36%,其中各类别的分类情况下表和下图所示。
| 类别 | precision | recall | f1-score | support |
|---|---|---|---|---|
| 山鸢尾 | 1.00 | 1.00 | 1.00 | 13 |
| 变色鸢尾 | 1.00 | 0.94 | 0.97 | 16 |
| 维吉尼亚鸢尾 | 0.9 | 1.00 | 0.95 | 9 |
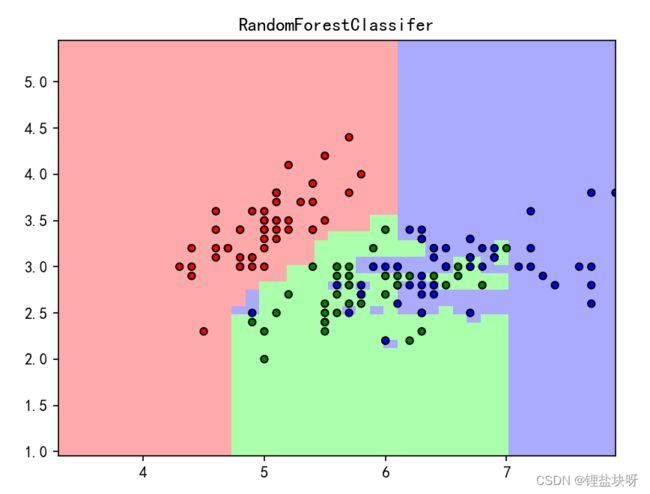
1.3 实验小结
对于鸢尾花数据集来说,支持向量机的分类效果会更好,分类正确率为100%。图1和图2的对比可得随机森林分类器出现了过拟合情况。
2 实验代码
2.1 SVM实验代码
import numpy as np
from sklearn.datasets import load_iris
from sklearn.svm import LinearSVC
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.metrics import accuracy_score
from sklearn.metrics import classification_report
import matplotlib as mpl
from matplotlib.colors import ListedColormap
import matplotlib.pyplot as plt
if __name__ == "__main__":
iris = load_iris()
X1 = iris.data
y = iris.target
X_train, X_test, y_train, y_test = train_test_split(X1, y, random_state=14)
sc = StandardScaler() # 数据预处理和归一化
X_train = sc.fit_transform(X_train)
X_test = sc.transform(X_test)
# 模型训练
clf = LinearSVC(random_state=0)
clf = clf.fit(X_train, y_train)
y_pred = clf.predict(X_test)
print("支持向量机准确率:", accuracy_score(y_test, y_pred))
print("其他指标:", classification_report(y_test, y_pred, target_names=['0', '1', '2']))
# 指定默认字体
mpl.rcParams['font.sans-serif'] = ['SimHei']
mpl.rcParams['axes.unicode_minus'] = False
# 画图
x = iris.data[:, :2]
clf.fit(x, y)
N = 50
cmap_light = ListedColormap(['#FFAAAA', '#AAFFAA', '#AAAAFF'])
cmap_bold = ListedColormap(['#FF0000', '#00FF00', '#0000FF'])
x_min, x_max = x[:, 0].min() - 1, x[:, 0].max() + 1 # 第0列的范围
y_min, y_max = x[:, 1].min() - 1, x[:, 1].max() + 1 # 第一列的范围
xx, yy = np.meshgrid(np.linspace(x_min, x_max, N), np.linspace(y_min, y_max, N)) # 生成网格采样点
z_show = np.stack((xx.flat, yy.flat), axis=1) # 测试点
z = clf.predict(z_show) # 预测分类值
plt.figure()
plt.pcolormesh(xx, yy, z.reshape(xx.shape), shading='auto', cmap=cmap_light)
plt.scatter(x[:, 0], x[:, 1], c=y, cmap=cmap_bold, edgecolors='k', s=20)
plt.xlim(xx.min(), x.max())
plt.title("SVMClassifer")
plt.show()
2.2 随机森林实验代码
import numpy as np
import matplotlib.pyplot as plt
from matplotlib.colors import ListedColormap
from sklearn.ensemble import RandomForestClassifier
from sklearn.datasets import load_iris
from sklearn.preprocessing import StandardScaler
import matplotlib as mpl
from sklearn.model_selection import train_test_split
from sklearn.metrics import classification_report
from sklearn.metrics import accuracy_score
mpl.rcParams['font.sans-serif'] = ['SimHei']
mpl.rcParams['axes.unicode_minus'] = False
RF = RandomForestClassifier(n_estimators=100, n_jobs=4, oob_score=True)
iris = load_iris()
X1 = iris.data
y = iris.target
X_train, X_test, y_train, y_test = train_test_split(X1, y, test_size=0.25, random_state=0)
sc = StandardScaler()
X_train = sc.fit_transform(X_train)
X_test = sc.transform(X_test)
RF.fit(X_train, y_train)
y_pred = RF.predict(X_test)
print("随机森林准确率:", accuracy_score(y_test, y_pred))
print("其他指标:\n", classification_report(y_test, y_pred, target_names=['0', '1', '2']))
# 画图
x = iris.data[:, :2]
RF.fit(x, y)
N = 50
cmap_light = ListedColormap(['#FFAAAA', '#AAFFAA', '#AAAAFF'])
cmap_bold = ListedColormap(['r', 'g', 'b'])
# for weight in ['uniform','distance']
x_min, x_max = x[:, 0].min() - 1, x[:, 0].max() + 1
y_min, y_max = x[:, 1].min() - 1, x[:, 1].max() + 1
xx, yy = np.meshgrid(np.linspace(x_min, x_max, N), np.linspace(y_min, y_max, N))
z_show = np.stack((xx.flat, yy.flat), axis=1) # 测试点
z = RF.predict(z_show)
plt.figure()
plt.pcolormesh(xx, yy, z.reshape(xx.shape), shading='auto', cmap=cmap_light)
plt.scatter(x[:, 0], x[:, 1], c=y, cmap=cmap_bold, edgecolors='k', s=20)
plt.xlim(xx.min(), x.max())
plt.title('RandomForestClassifer')
plt.show()
3 实验遇到的问题总结
3.1 数据归一化处理
实验代码:
sc = StandardScaler()
X_train = sc.fit_transform(X_train)
X_test = sc.transform(X_test)
参考文献:Sklearn之数据预处理——StandardScaler。
3.2 背景色显示不全
原先代码:
x_min, x_max = x[:, 0].min() - 1, x[:, 0].max() - 1
y_min, y_max = x[:, 1].min() - 1, x[:, 1].max() + 1
修改代码:
x_min, x_max = x[:, 0].min() - 1, x[:, 0].max() + 1
y_min, y_max = x[:, 1].min() - 1, x[:, 1].max() + 1