KITTI 数据集解析 - 3D目标检测
KITTI 数据集解析 - 3D目标检测
- 1. 数据集简介
- 2. 数据集内容
-
- 2.1 KITTI 3D 目标检测数据集描述
- 2.2 KITTI 数据采集平台描述
- 2.3 KITTI 3D 目标检测数据集解析
-
- 2.3.1 ImageSets
- 2.3.2 testing & training
-
- 2.3.2.1 calib
- 2.3.2.2 image_2
- 2.3.2.3 label_2
- 2.3.2.4 planes
- 2.3.2.5 velodyne
- 3. 数据集下载
- 4. 参考资料
1. 数据集简介
- 文章标题
Are we ready for Autonomous Driving? The KITTI Vision Benchmark Suite (2012)
- 文章链接
http://www.cvlibs.net/publications/Geiger2012CVPR.pdf
- 数据集官网
http://www.cvlibs.net/datasets/kitti/index.php
2. 数据集内容
2.1 KITTI 3D 目标检测数据集描述
- KITTI 数据集主页
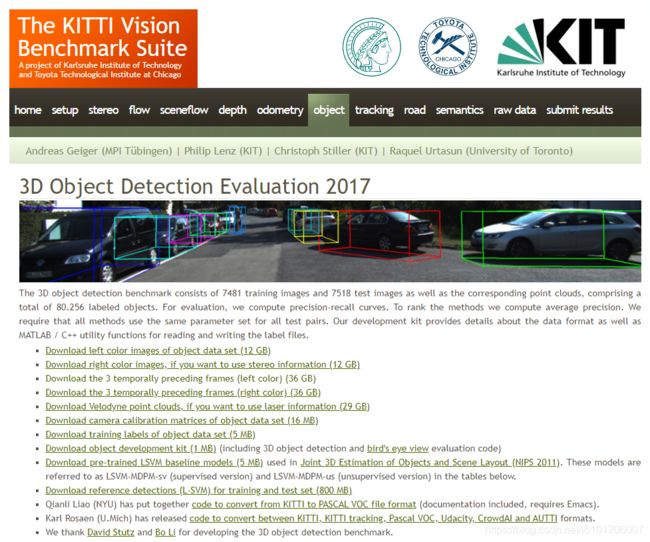
3D目标检测基准由7481个训练图像和7518个测试图像以及相应的点云组成,共包含80256个带标签的目标。( 国内下载方式)
2.2 KITTI 数据采集平台描述
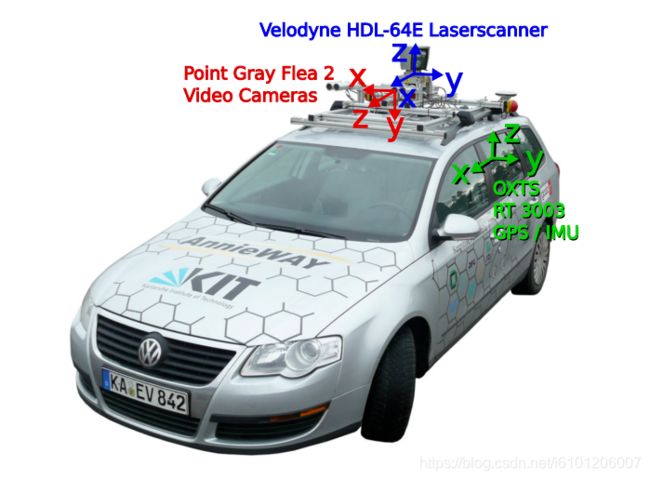
数据采集平台:2个灰度摄像机,2个彩色摄像机,1个激光雷达,4个光学镜头,1个GPS导航系统。
- 2 × PointGray Flea2 grayscale cameras (FL2-14S3M-C), 1.4 Megapixels, 1/2” Sony ICX267 CCD, global shutter
- 2 × PointGray Flea2 color cameras (FL2-14S3C-C), 1.4 Megapixels, 1/2” Sony ICX267 CCD, global shutter
- 4 × Edmund Optics lenses, 4mm, opening angle ∼ 90◦, vertical opening angle of region of interest (ROI) ∼ 35◦
- 1 × Velodyne HDL-64E rotating 3D laser scanner, 10 Hz, 64 beams, 0.09 degree angular resolution, 2 cm distance accuracy, collecting ∼ 1.3 million points/second, field of view: 360◦ horizontal, 26.8◦ vertical, range: 120 m
- 1 × OXTS RT3003 inertial and GPS navigation system, 6 axis, 100 Hz, L1/L2 RTK, resolution: 0.02m / 0.1◦
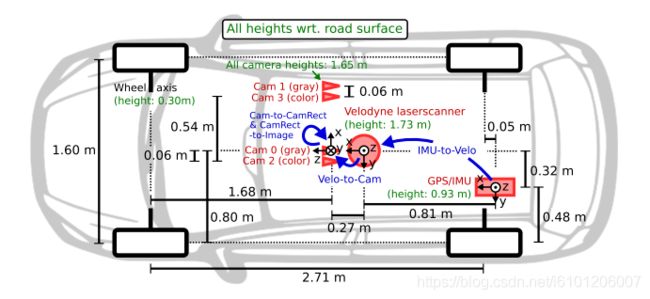
传感器的配置平面图如上所示。为了生成双目立体图像,相同类型的摄像头相距54cm安装。由于彩色摄像机的分辨率和对比度不够好,所以还使用了两个立体灰度摄像机,它和彩色摄像机相距6cm安装。
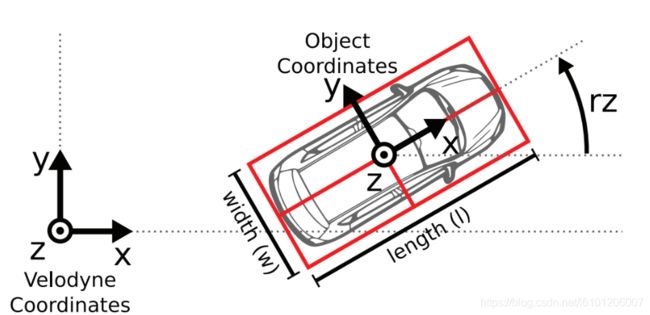
为了方便传感器数据标定,规定坐标系方向如下 :
- Camera: x = right, y = down, z = forward
- Velodyne: x = forward, y = left, z = up
- GPS/IMU: x = forward, y = left, z = up
2.3 KITTI 3D 目标检测数据集解析
数据集结构
data
│── kitti
│ │── ImageSets
│ │── testing
│ │ ├── calib & image_2 & velodyne
│ │── training
│ │ ├── calib & image_2 & label_2 & planes & velodyne
2.3.1 ImageSets
数据集列表信息,一般包括如下3部分:
- train.txt:训练集 列表信息
- trainval.txt:训练集+验证集 列表信息
- val.txt:验证集 列表信息
2.3.2 testing & training
2.3.2.1 calib
P0: 7.215377000000e+02 0.000000000000e+00 6.095593000000e+02 0.000000000000e+00 0.000000000000e+00 7.215377000000e+02 1.728540000000e+02 0.000000000000e+00 0.000000000000e+00 0.000000000000e+00 1.000000000000e+00 0.000000000000e+00
P1: 7.215377000000e+02 0.000000000000e+00 6.095593000000e+02 -3.875744000000e+02 0.000000000000e+00 7.215377000000e+02 1.728540000000e+02 0.000000000000e+00 0.000000000000e+00 0.000000000000e+00 1.000000000000e+00 0.000000000000e+00
P2: 7.215377000000e+02 0.000000000000e+00 6.095593000000e+02 4.485728000000e+01 0.000000000000e+00 7.215377000000e+02 1.728540000000e+02 2.163791000000e-01 0.000000000000e+00 0.000000000000e+00 1.000000000000e+00 2.745884000000e-03
P3: 7.215377000000e+02 0.000000000000e+00 6.095593000000e+02 -3.395242000000e+02 0.000000000000e+00 7.215377000000e+02 1.728540000000e+02 2.199936000000e+00 0.000000000000e+00 0.000000000000e+00 1.000000000000e+00 2.729905000000e-03
R0_rect: 9.999239000000e-01 9.837760000000e-03 -7.445048000000e-03 -9.869795000000e-03 9.999421000000e-01 -4.278459000000e-03 7.402527000000e-03 4.351614000000e-03 9.999631000000e-01
Tr_velo_to_cam: 7.533745000000e-03 -9.999714000000e-01 -6.166020000000e-04 -4.069766000000e-03 1.480249000000e-02 7.280733000000e-04 -9.998902000000e-01 -7.631618000000e-02 9.998621000000e-01 7.523790000000e-03 1.480755000000e-02 -2.717806000000e-01
Tr_imu_to_velo: 9.999976000000e-01 7.553071000000e-04 -2.035826000000e-03 -8.086759000000e-01 -7.854027000000e-04 9.998898000000e-01 -1.482298000000e-02 3.195559000000e-01 2.024406000000e-03 1.482454000000e-02 9.998881000000e-01 -7.997231000000e-01
- P0 ~ P3:矫正后的投影矩阵
- R0_rect:矫正旋转矩阵
- Tr_velo_to_cam:从雷达到相机 0 的旋转平移矩阵
- Tr_imu_to_velo:从惯导或GPS装置到相机的旋转平移矩阵
- i ∈ {0, 1, 2, 3} 是相机索引,其中 0 代表左灰度,1 代表右灰度,2 代表左彩色,3 代表右边彩色相机。
1、将 Velodyne 坐标中的点 x 投影到左侧的彩色图像中 y,使用公式 y = P2 * R0_rect * Tr_velo_to_cam * x
2、将 Velodyne 坐标中的点 x 投影到右侧的彩色图像中 y,使用公式 y = P3 * R0_rect * Tr_velo_to_cam * x
3、将 Velodyne 坐标中的点 x 投影到编号为 0 的相机(参考相机)坐标系中,使用公式 R0_rect * Tr_velo_to_cam * x
4、将 Velodyne 坐标中的点 x 投影到编号为 0 的相机(参考相机)坐标系中,再投影到编号为 2 的相机(左彩色相机)的照片上,使用公式 P2 * R0_rect * Tr_velo_to_cam * x
注意:
- 所有矩阵都存储在行中,即第一个值对应于第一行。 R0_rect 包含一个 3x3 矩阵,需要将其扩展为 4x4 矩阵,方法是在右下角添加 1,在其他位置添加 0。 Tr_xxx是一个 3x4 矩阵(R | t),需要以相同的方式扩展到 4x4 矩阵!
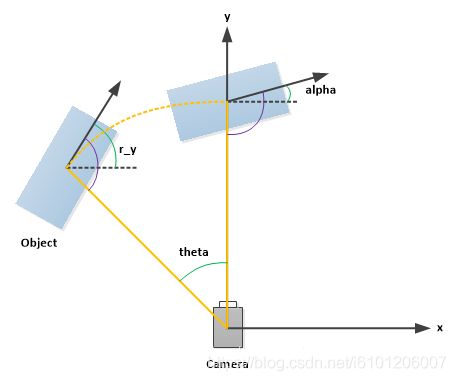
- 通过使用校准文件夹中的 3x4 投影矩阵,可以将相机坐标系中的坐标投影到图像中,对于提供图像的左侧彩色相机,必须使用 P2。rotation_y 和 alpha 之间的区别在于 rotation_y 直接在相机坐标中给出,而 alpha 也会考虑从相机中心到物体中心的矢量,以计算物体相对于相机的相对方向。 例如,沿着摄像机坐标系的 X 轴面向的汽车,无论它位于 X / Z 平面(鸟瞰图)中的哪个位置,它的 rotation_y 都为 0,而只有当此车位于相机的Z轴上时 α 才为零,当此车从 Z 轴移开时,观察角度 α 将会改变。
2.3.2.2 image_2

2.3.2.3 label_2
The label files contain the following information, which can be read and
written using the matlab tools (readLabels.m, writeLabels.m) provided within
this devkit. All values (numerical or strings) are separated via spaces,
each row corresponds to one object. The 15 columns represent:
#Values Name Description
----------------------------------------------------------------------------
1 type Describes the type of object: 'Car', 'Van', 'Truck',
'Pedestrian', 'Person_sitting', 'Cyclist', 'Tram',
'Misc' or 'DontCare'
1 truncated Float from 0 (non-truncated) to 1 (truncated), where
truncated refers to the object leaving image boundaries
1 occluded Integer (0,1,2,3) indicating occlusion state:
0 = fully visible, 1 = partly occluded
2 = largely occluded, 3 = unknown
1 alpha Observation angle of object, ranging [-pi..pi]
4 bbox 2D bounding box of object in the image (0-based index):
contains left, top, right, bottom pixel coordinates
3 dimensions 3D object dimensions: height, width, length (in meters)
3 location 3D object location x,y,z in camera coordinates (in meters)
1 rotation_y Rotation ry around Y-axis in camera coordinates [-pi..pi]
1 score Only for results: Float, indicating confidence in
detection, needed for p/r curves, higher is better.
Here, 'DontCare' labels denote regions in which objects have not been labeled,
for example because they have been too far away from the laser scanner. To
prevent such objects from being counted as false positives our evaluation
script will ignore objects detected in don't care regions of the test set.
You can use the don't care labels in the training set to avoid that your object
detector is harvesting hard negatives from those areas, in case you consider
non-object regions from the training images as negative examples.
Truck 0.00 0 -1.57 599.41 156.40 629.75 189.25 2.85 2.63 12.34 0.47 1.49 69.44 -1.56
Car 0.00 0 1.85 387.63 181.54 423.81 203.12 1.67 1.87 3.69 -16.53 2.39 58.49 1.57
Cyclist 0.00 3 -1.65 676.60 163.95 688.98 193.93 1.86 0.60 2.02 4.59 1.32 45.84 -1.55
DontCare -1 -1 -10 503.89 169.71 590.61 190.13 -1 -1 -1 -1000 -1000 -1000 -10
DontCare -1 -1 -10 511.35 174.96 527.81 187.45 -1 -1 -1 -1000 -1000 -1000 -10
DontCare -1 -1 -10 532.37 176.35 542.68 185.27 -1 -1 -1 -1000 -1000 -1000 -10
DontCare -1 -1 -10 559.62 175.83 575.40 183.15 -1 -1 -1 -1000 -1000 -1000 -10
每行代表1个目标,每行有16列,其定义如下:
- 第1列(字符串):代表物体类别(type),总共有9类,分别是:Car、Van、Truck、Pedestrian、Person_sitting、Cyclist、Tram、Misc、DontCare。其中DontCare标签表示该区域没有被标注,比如由于目标物体距离激光雷达太远。为了防止在评估过程中(主要是计算precision),将本来是目标物体但是因为某些原因而没有标注的区域统计为假阳性(false positives),评估脚本会自动忽略DontCare区域的预测结果。
- 第2列(浮点数):代表物体是否被截断(truncated),数值在0(非截断)到1(截断)之间浮动,数字表示指离开图像边界对象的程度。
- 第3列(整数):代表物体是否被遮挡(occluded),整数0、1、2、3分别表示被遮挡的程度。
- 第4列(弧度数):物体的观察角度(alpha),取值范围为:-pi ~ pi(单位:rad),它表示在相机坐标系下,以相机原点为中心,相机原点到物体中心的连线为半径,将物体绕相机y轴旋转至相机z轴,此时物体方向与相机x轴的夹角,如图1所示。
- 第5~8列(浮点数):物体的2D边界框大小(bbox),四个数分别是xmin、ymin、xmax、ymax(单位:pixel),表示2维边界框的左上角和右下角的坐标。
- 第9~11列(浮点数):3D物体的尺寸(dimensions),分别是高、宽、长(单位:米)
- 第12-14列(整数):3D物体的位置(location),分别是x、y、z(单位:米),特别注意的是,这里的xyz是在相机坐标系下3D物体的中心点位置。
- 第15列(弧度数):3D物体的空间方向(rotation_y),取值范围为:-pi ~ pi(单位:rad),它表示,在照相机坐标系下,物体的全局方向角(物体前进方向与相机坐标系x轴的夹角)。
- 第16列(整数):检测的置信度(score),用来绘制p/r曲线,越高越好。此为模型的输出,此处省略了。
2.3.2.4 planes
# Plane
Width 4
Height 1
-1.851372e-02 -9.998285e-01 -5.362310e-04 1.678761e+00
2.3.2.5 velodyne
8D 97 92 41 39 B4 48 3D 58 39 54 3F 00 00 00 00
83 C0 92 41 87 16 D9 3D 58 39 54 3F 00 00 00 00
2D 32 4D 42 AE 47 01 3F FE D4 F8 3F 00 00 00 00
37 89 92 41 D3 4D 62 3E 58 39 54 3F 00 00 00 00
E5 D0 92 41 12 83 80 3E E1 7A 54 3F EC 51 B8 3D
7B 14 70 41 2B 87 96 3E 50 8D 37 3F CD CC 4C 3E
96 43 6F 41 7B 14 AE 3E 3D 0A 37 3F E1 7A 14 3F
2F DD 72 41 5E BA C9 3E 87 16 39 3F 00 00 00 00
FA 7E 92 41 5E BA 09 3F 58 39 54 3F 00 00 00 00
66 66 92 41 EC 51 18 3F CF F7 53 3F 00 00 00 00
A4 70 92 41 77 BE 1F 3F CF F7 53 3F 00 00 00 00
A4 70 92 41 8D 97 2E 3F 58 39 54 3F 00 00 00 00
...
...
点云数据以浮点二进制文件格式存储,每个浮点数占4字节。一个点云数据由4个浮点数构成,分别表示点云的x、y、z、r,其存储方式如下表所示:
| 点云 | X轴 (m) | Y轴 (m) | Z轴 (m) | 反射强度 |
|---|---|---|---|---|
| pointcloud-1 | x-1 | y-1 | z-1 | r-1 |
| pointcloud-2 | x-2 | y-2 | z-2 | r-2 |
| pointcloud-3 | x-3 | y-3 | z-3 | r-3 |
| … | … | … | … | … |
| pointcloud-n | x-n | y-n | z-n | r-n |
3. 数据集下载
官方下载地址:
http://www.cvlibs.net/datasets/kitti/eval_object.php?obj_benchmark=3d
第三方下载地址:
https://gas.graviti.cn/dataset/data-decorators/KITTIObject
4. 参考资料
- [1] Andreas Geiger and Philip Lenz and Raquel Urtasun. Are we ready for Autonomous Driving? The KITTI Vision Benchmark Suite. CVPR, 2012
- [2] Andreas Geiger and Philip Lenz and Christoph Stiller and Raquel Urtasun. Vision meets Robotics: The KITTI Dataset. IJRR, 2013
- [3] https://blog.csdn.net/u013086672/article/details/103913361