【CVPR 2019】Semantic Image Synthesis with Spatially-Adaptive Normalization(SPADE)
文章目录
- Introduction
- 3. Semantic Image Synthesis
-
- Spatially-adaptive denormalization.
- conclusion

# 空间自适应正则化
We propose spatially-adaptive normalization, a simplebut effective layer for synthesizing photorealistic images given an input semantic layout. we propose usingthe input layout for modulating the activations in normal-ization layers through a spatially-adaptive, learned trans-formation.
Experiments on several challenging datasetsdemonstrate the advantage of the proposed method over ex-isting approaches, regarding both visual fidelity and align-ment with input layouts. Finally, our model allows usercontrol over both semantic and style.
Introduction
In this paper, we show that the conventional net-work architecture [22, 48], which is built by stacking con-volutional, normalization, and nonlinearity layers, is at best suboptimal because their normalization layers tend to “washaway” information contained in the input semantic masks. //在本文中,我们证明了传统的网络体系结构[22,48],它由卷积层、归一化层和非线性层叠加而成,在最好的情况下是次优的,因为它们的归一化层倾向于“淘汰”包含在输入语义掩码中的信息。
To address the issue, we proposespatially-adaptive normal-ization, a conditional normalization layer that modulates theactivations using input semantic layouts through a spatially-adaptive, learned transformation and can effectively propa-gate the semantic information throughout the network. //为了解决这一问题,我们提出了一种空间自适应标准化,它是一种条件标准化层,通过空间自适应的学习转换来调节输入语义布局的激活,并能在整个网络中有效地传播语义信息。
这段话像abstract。
Figure 1: Our model allows user control over both semantic and style as synthesizing an image. The semantic (e.g., theexistence of a tree) is controlled via a label map (the top row), while the style is controlled via the reference style image (theleftmost column). Please visit our website for interactive image synthesis demos. //图1:我们的模型允许用户控制合成图像时的语义和风格。语义(例如,树的存在)是通过标签映射(最上面的行)来控制的,而样式是通过参考样式图像(最左边的列)来控制的。请访问我们的网站进行交互式图像合成演示。
our goal is to design a generator forstyle and semantics disentanglement. We focus on provid-ing the semantic information in the context of modulatingnormalized activations. We use semantic maps in differentscales, which enables coarse-to-fine generation. The readeris encouraged to review their work for more details. //我们的目标是设计一个样式和语义分解的生成器。我们专注于在调节规范化激活的上下文中提供语义信息。我们在不同的尺度上使用语义映射,这使得粗到细的生成成为可能。鼓励读者回顾他们的工作以获得更多的细节。
3. Semantic Image Synthesis
我们的目标是学习一个映射函数,它可以将一个输入分割mask转换成逼真的图像
Spatially-adaptive denormalization.
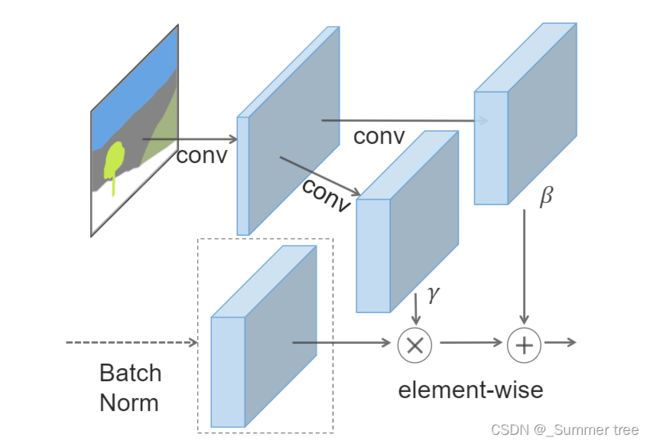
Figure 2: In the SPADE, the mask is first projected onto anembedding space and then convolved to produce the modu-lation parametersγandβ. Unlike prior conditional normal-ization methods,γandβare not vectors, but tensors withspatial dimensions. The producedγandβare multipliedand added to the normalized activation element-wise //图2:在SPADE中,掩模首先投影到嵌入空间,然后卷积产生调制参数γ和β。与先验条件归一化方法不同,γ和β不是向量,而是具有空间维数的张量。将生成的γ和β相乘并加入到归一化的活化元素中.
The activation value at site(n∈N,c∈Ci,y∈Hi,x∈Wi)is
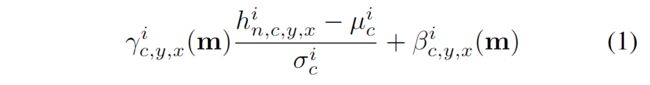
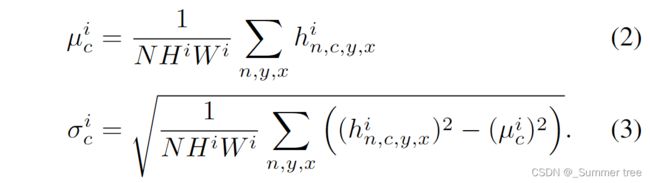
\gamma and \beta are thelearned modulation parameters of the normalization layer/
In contrast to the BatchNorm [21], they depend on the in-put segmentation mask and vary with respect to the location(y,x).


Figure 3: Comparing results given uniform segmentationmaps: while the SPADE generator produces plausible tex-tures, the pix2pixHD generator [48] produces two identicaloutputs due to the loss of the semantic information after thenormalization layer.
SPADE generator.
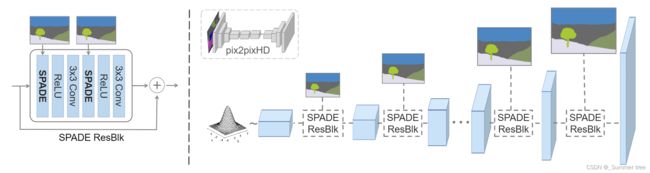
Figure 4: In the SPADE generator, each normalization layer uses the segmentation mask to modulate the layer activations.(left)Structure of one residual block with the SPADE.(right)The generator contains a series of the SPADE residual blockswith upsampling layers. Our architecture achieves better performance with a smaller number of parameters by removing thedownsampling layers of leading image-to-image translation networks such as the pix2pixHD model [48].
conclusion
我们提出了空间自适应归一化,利用输入语义布局,在归一化层中进行仿射变换。提出的归一化导致了第一个语义图像合成模型,该模型可以产生包括室内、室外、景观和街道场景在内的各种场景的真实感输出。我们进一步论证了它在多模态合成和引导图像合成中的应用。