tensorflow自然语言处理基础
语言模型:
语言模型是自然语言处理问题中一类最基本的问题,它有着非常广泛的应用,也是理解更加复杂的自然语言处理问题的基础。假设一门语言中所有可能的句子服从某一个概率分布,每个句子出现的概率加起来为1,那么语言模型的任务就是预测每个句子在语言中出现的概率。把句子看成单词的序列,语言模型可以表示为一个计算p(w1,w2,……,wm)的模型,语言模型仅仅只是对句子出现的概率进行建模,并不尝试去理解句子的内容含义。
那么如何计算一个句子的概率呢?首先一个句子可以被看成是一个单词序列,S=(w1,w2,……,wm),其中m为句子的长度,那么它的概率可以表示为:
P(S) = p(w1,w2,……,wm) = p(w1)p(w2|w1)p(w3|w1,w2)……p(wm|w1,w2,……,wm-1)
p(wm|w1,w2,……,wm-1)表示已知前m-1个单词时,第m个单词为wm的条件概率,假设一门语言的词汇量为V,如果要将p(wm|w1,w2,……,wm-1)的所有参数保存在一个模型里,将需要V^m个参数,一般句子长度远远超出了实际可行的范围。为了估计这些参数的取值,常见的方法有n-gram,决策树,最大熵模型,条件随机场,神经网络语言模型等等。
这里以最简单的n-gram模型来介绍自然语言处理,n-gram做了一个有限的历史假设 p(S) = p(w1,w2,w3,…,wm) = ∏ p(wi | wi-n+1, …, wi-1),n-gram模型里的n指的是当前单词依赖它前面单词个数,通常n可以取1,2,3,4。n-gram模型的参数一般采用最大似然值估计(MLE)方法计算:
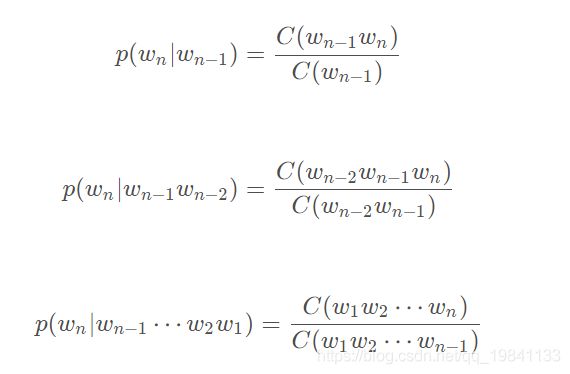
说人话就是数频数。
语言模型的评价方法:
语言模型效果好坏的常用评价指标是复杂度(perplexity),在一个测试集上得到的perplexity越低,说明建模的效果越好。perplexity值刻画的是语言模型预测一个语言样本的能力。
perplexity值,PP(S) = perplexity(S)
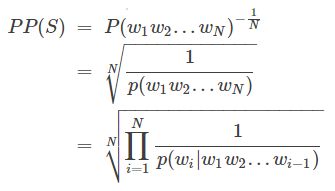
perlexity实际是计算每一个单词得到的概率的几何平均,因此perplexity可以理解为平均分支系数,即模型预测下一个词时的平均可选择数量。
在语言模型的训练中,通常采用perplexity的对数表达形式:
log(perplexity(S)),相比乘积求平方根的方式,使用加法的形式可以加速计算,同时避免乘积数值过低而导致浮点数向下溢出的问题。
在数学上log perplexity 可以看成真实分布与预测分布之间的交叉熵。
在神经网络模型中,p(wm|w1,w2,……,wm-1)分布通常是由一个softmax层产生,softmax层的作用是将神经网络的输出转为一个单词表中每个单词的输出概率。
第一,使用一个线性映射将神经网络的输出映射为一个维度与词汇表大小相同的向量,这一步的输出叫logits。
第二,调用ft.nn.softmax法将logits转化为加和为1的概率。Softmax函数的公式如下所示,这个计算过程在sparse_softmax_cross_entropy_with_logits函数内部进行。
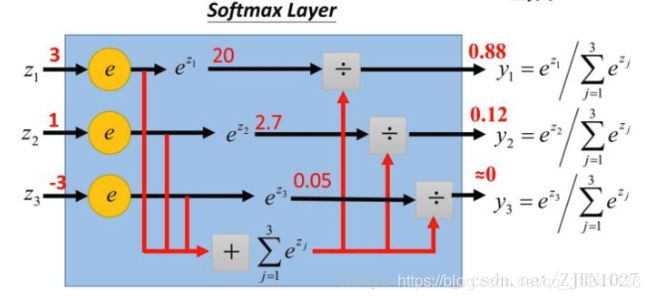
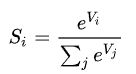
最后一步,模型训练通常不关心概率的具体取值,而更关心最终的log perplexity,最终调用tf.nn.sparse_softmax_cross_entropy_with_logits计算log perplexity。
sparse_softmax_cross_entropy_with_logits()函数有两个参数logits和labels,
传入的logits为神经网络输出层的输出,shape为[batch_size,num_classes],(如果为二分类问题,num_classes就等于2,在自然语言处理中那么这个num_classes就等于VOCAB_SIZE词汇量了)
传入的labels为一个一维的向量,长度等于batch_size,每一个值的取值区间必须是[0,num_classes),其实每一个值就是代表了batch中对应样本的类别。sparse不用one-hot, 直接用标签计算交叉熵。而如果你的label已经是one-hot格式,则可以使用tf.nn.softmax_cross_entropy_with_logits()函数来进行softmax和loss的计算。
one-hot格式:
例如如果分量(num_classes)为3,代表该样本属于第三类,其对应的one-hot格式label为[0,0,0,1,…0],再例如如果词汇表大小为3,num_classes=2,对应的one-hot格式为[0.0, 0.0, 1.0]。
Cross-Entropy交叉熵计算
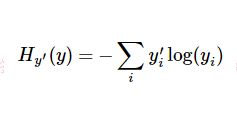
其中yi’为label中的第i个值,yi为经softmax归一化输出的向量中的对应分量,由此可以看出,当分类越准确时,yi所对应的分量就会越接近于1,从而交叉熵的值也就会越小。
也就是说,logits是作为softmax的输入。经过softmax的加工,就变成“归一化”的概率(设为q),然后和labels代表的概率分布(设为p),于是,整个函数的功能就是前面的计算labels(概率分布p)和logits(概率分布q)之间的交叉熵,也就是log perplexity。
PTB数据集预处理
PTB文本数据集是目前语言模型学习中使用最广泛的数据集。虽然与深度学习和tf并不直接相关,但是正确理解数据集的预处理对于理解后面的内容和工程实践都是非常重要的。
PTB数据集下载地址如下:
http://www.fit.vutbr.cz/~imikolov/rnnlm/simple-examples.tgz
里面会得到如下文件夹

在解压上述链接的压缩包,找到文件中的data文件,会发现有三个已经预处理过的三分数据文件
ptb.test.txt
ptb.train.txt
ptb.valid.txt
这三个文件都已经预处理过,相邻单词之间用空格隔开,数据集包含了9998个不同的单词词汇,加上稀有词汇的特殊符号 unk,和语句结束标志符在内一共就是10000个词汇,注意在使用复杂度比较不同的语言模型时,文本的预处理和词汇表必须保持一致。近年来有关于语言模型的论文大多采用了Mikolov提供的这一预处理后的数据版本,由此保证了论文之间具有可比性。
按照词频顺序为每个词汇分配一个编号,然后将词汇表保存到一个独立的vocab文件中。
import codecs
import collections
from operator import itemgetter
# 训练集的数据文件
RAW_DATA = "D:\My_Field\datasets\simple-examples\data\ptb.train.txt"
# 定义一个将为文本文件转化为词汇表文件名
VOCAB_OUTPUT = "ptb.vocab"
# 统计单词的出现频率
counter = collections.Counter() # statistic frequence of vocab
with codecs.open(RAW_DATA, "r", "utf-8") as f:
for line in f:
for word in line.strip().split():
counter[word] += 1
# 按词频顺序对单词进行排序
sorted_word_to_cnt = sorted(counter.items(),
key=itemgetter(1),
reverse=True)
sorted_words = [x[0] for x in sorted_word_to_cnt]
# 在文本换行处加入句子的结束符"",这里预先将其加入词汇表
sorted_words = ["" ] + sorted_words
# 因为在PTB数据集中,输入数据已经将低频词汇替换为了,所以不需要以下代码块。
'''
if MODE == "PTB":
# 稍后我们需要在文本换行处加入句子结束符"",这里预先将其加入词汇表。
sorted_words = [""] + sorted_words
elif MODE in ["TRANSLATE_EN", "TRANSLATE_ZH"]:
# 在处理机器翻译数据时,除了""以外,还需要将""(是指稀有词汇)
和句子起始符""加入词汇表,并从词汇表中删除低频词汇。
# 一般情况下应采用以下代码块
sorted_words = ["", "", ""] + sorted_words
if len(sorted_words) > VOCAB_SIZE:
sorted_words = sorted_words[:VOCAB_SIZE]
'''
with codecs.open(VOCAB_OUTPUT, 'w', 'utf-8') as file_output:
for word in sorted_words:
file_output.write(word + "\n")
下面展示了使用频率由高到低的几个词
在确定了词汇表后,再将训练文件、测试文件等根据词汇表转化为单词编号,每个单词的编号就是它在ptb.vocab文件中的编号。
import codecs
import sys
# 原始的训练集数据文件
RAW_DATA = "D:\My_Field\datasets/simple-examples/data/ptb.train.txt"
# 上面生成的词汇表文件
VOCAB = "ptb.vocab"
# 将单词替换成为单词编号后的输出文件
OUTPUT_DATA = "ptb.train"
# 读取词汇表,并建立词汇到单词编号的映射。
with codecs.open(VOCAB, "r", "utf-8") as f_vocab:
vocab = [w.strip() for w in f_vocab.readlines()]
word_to_id = {k: v for (k, v) in zip(vocab, range(len(vocab)))}
# 如果出现了被删除的低频词,则替换为""。
def get_id(word):
return word_to_id[word] if word in word_to_id else word_to_id["]
fin = codecs.open(RAW_DATA, "r", "utf-8")
fout = codecs.open(OUTPUT_DATA, 'w', 'utf-8')
for line in fin:
# 读取单词并添加结束符
words = line.strip().split() + ["" ]
# 将每个单词替换为词汇表中的编号
out_line = ' '.join([str(get_id(w)) for w in words]) + '\n'
fout.write(out_line)
fin.close()
fout.close()
文件结果:
这个例子简单使用了文本文件来保存经过处理的数据,在实际工程中,通常使用TFRecords格式来提高读写效率,但在工程实践上,保存处理好的数据有几个重要的优点,第一,在调试模式的过程中,可以保证不同模型采取的预处理步骤相同,第二,减小文件体积,节省磁盘度读取的时间,第三,方便对预处理步骤本身进行debug,例如在模型训练效果不理想时,只需检查最终的数据文件就可以知道是否是预处理过程出了问题。
PTB数据的batching方法
在文本数据中,由于每个句子的长度不同,又无法像图像一样调整到固定维度,因此对文本数据进行batching需要有特殊的操作。最常用的方法是padding,将同一batch内的句子长度不齐。但语言模型为了利用上下文信息,必须将前面句子的信息传递到后面,在PTB上下文有关联的数据集上,通常采用另一种batching方法。
如果模型大小没有限制,那最理想的设计是将整个文档前后连接起来,当作一个句子来训练,但是现实中是无法实现的,例如PTB数据中共有约19万词,如将整个文档放入一个计算图,循环神经网络会展开成一个19万层的前馈网络,这样导致计算图过大,另外序列过长可能造成训练中的梯度爆炸问题。对此问题的解决方法是,将长序列切割为固定长度的子序列。循环神经网络在处理完一个子序列后,它最终的隐藏状态将复制到下一个序列中作为初始值,这样在前向计算时,效果等同于一次性顺序地读取了整个文档;而在反向传播中,梯度则只在每个子序列内内部传播。
为了利用计算时的并行能力,我们希望每一次计算可以对多个句子进行并行处理,同时又要尽量保证batch之间上下文连续,解决方案是,将整个文档切分成若干连接段落,再让batch中的每一个位置负责其中的一段,例如,如果batch大小是4,则先将文档平均分成4个子序列,让batch中的每一个位置负责其中一个子序列,这样每个子序列内部的所有数据仍可以被顺序处理。
下面代码从文本文件中读取数据,并按上面介绍的方案将数据整理成batch
"""
@desc: 从文本文件中读取数据,并按照下面介绍的方案将数据整理成batch。
方法是:先将整个文档切分成若干连续段落,再让batch中的每一个位置负责其中一段。
"""
import numpy as np
import tensorflow as tf
# 使用单词编号表示的训练数据
TRAIN_DATA = './ptb.train'
TRAIN_BATCH_SIZE = 20
TRAIN_NUM_STEP = 35
# 从文件中读取数据,并返回包含单词编号的数组
def read_data(file_path):
with open(file_path, "r") as fin:
# 将整个文档读进一个长字符串
id_string = ' '.join([line.strip() for line in fin.readlines()])
# 将读取的单词编号转为整数
id_list = [int(w) for w in id_string.split()]
return id_list
def make_batches(id_list, batch_size, num_step):
# batch_size: 一个batch中样本的数量 = 20
# num_batches:batch的个数 = 1327
# num_step: 一个样本的序列长度 = 35
# 计算总的batch数量。每个batch包含的单词数量是batch_size * num_step
num_batches = (len(id_list) - 1) // (batch_size * num_step)
# 将数据整理成一个维度为[batch_size, num_batches*num_step]的二维数组
data = np.array(id_list[: num_batches * batch_size * num_step])
data = np.reshape(data, [batch_size, num_batches * num_step])
# 沿着第二个维度将数据切分成num_batches个batch,存入一个数组。
data_batches = np.split(data, num_batches, axis=1)
print(data)
# 重复上述操作,但是每个位置向右移动一位,这里得到的是RNN每一步输出所需要预测的下一个单词
label = np.array(id_list[1: num_batches * batch_size * num_step + 1])
label = np.reshape(label, [batch_size, num_batches * num_step])
label_batches = np.split(label, num_batches, axis=1)
# 返回一个长度为num_batches的数组,其中每一项包括一个data矩阵和一个label矩阵
return list(zip(data_batches, label_batches))
def main():
train_batches = make_batches(read_data(TRAIN_DATA), TRAIN_BATCH_SIZE, TRAIN_NUM_STEP)
# 在这里插入模型训练的代码。训练代码将在后面提到。
if __name__ == '__main__':
main()
’ '.join([line.strip() for line in fin.readlines()])
join() 方法用于将序列中的元素以指定的字符连接生成一个新的字符串。
str = "-";
seq = ("a", "b", "c"); # 字符串序列
print str.join( seq );
# a-b-c
strip() 方法用于移除字符串头尾指定的字符(默认为空格或换行符)或字符序列。
str = "00000003210Runoob01230000000";
print str.strip( '0' );
# 3210Runoob0123
num_batches = (len(id_list) - 1) // (batch_size * num_step)
//除法,只是不会有小数部分
x = 15 // 7
print(x)
# 2
np.split(data, num_batches, axis=1)
split(ary, indices_or_sections, axis=0) :把一个数组从左到右按顺序切分
ary:要切分的数组
indices_or_sections:如果是一个整数,就用该数平均切分,如果是一个数组,为沿轴切分的位置(左开右闭)
axis:沿着哪个维度进行切向,默认为0,横向切分。为1时,纵向切分,就是按列切分。
x = [int(i) for i in range(12)]
x = np.array(x)
x = np.reshape(x, [3, 4])
print(np.split(x, 2, axis=1))
'''
[array([[0, 1],
[4, 5],
[8, 9]]), array([[ 2, 3],
[ 6, 7],
[10, 11]])]
'''
list(zip(data_batches, label_batches))
zip() 函数用于将可迭代的对象作为参数,将对象中对应的元素打包成一个个元组,然后返回由这些元组组成的对象,这样做的好处是节约了不少的内存。我们可以使用 list() 转换来输出列表。如果各个迭代器的元素个数不一致,则返回列表长度与最短的对象相同,利用 * 号操作符,可以将元组解压为列表。
x = [1, 2, 3, 4, 5, 6]
y = [7, 8, 9, 10, 11, 12]
z = [13, 14, 15, 16, 17, 18]
print(list(zip(x, y, z)))
'''
[(1, 7, 13), (2, 8, 14), (3, 9, 15), (4, 10, 16), (5, 11, 17), (6, 12, 18)]
'''
list(zip(data_batches, label_batches))
这里的data_batches和label_batches都是含有1327个20×35矩阵的list,zip后拼接成1327个元组,一个元组包含两个矩阵(array)分别来自data_batches和label_batches