「综述专栏」什么是知识图谱|知识图谱入门|概述
知识图谱,本质上,是一种揭示实体之间关系的语义网络。
知识图谱的提出是为了准确地阐述人、事、物之间的关系,最早应用于搜索引擎。知识图谱是为了描述文本语义,在自然界建立实体关系的知识数据库。
在信息的基础上,建立实体之间的联系,就能行成 “知识”。大多数知识图谱都采用自底向上(bottom-up)的构建方式。自底向上指的是从一些开放链接数据(也就是 “信息”)中提取出实体,选择其中置信度较高的加入到知识库,再构建实体与实体之间的联系。
在自然语言处理视角下,知识图谱就是从文本中抽取语义和结构化的数据。在知识表示视角下,知识图谱是采用计算机符号表示和处理知识的方法。在人工智能视角下,知识图谱是利用知识库来辅助理解人类语言的工具。在数据库视角下,知识图谱是利用图的方式去存储知识的方法。
知识图谱还是比较通用的语义知识的形式化描述框架,它用节点表示语义符号,用边表示语义之间的关系.
知识图谱的表示是指用语言对知识图谱进行建模,从而达到方便知识计算的目的。从图的角度来看,知识图谱就是一个语义网络,即用互联的节点和弧表示知识结构。知识图谱的表示是一种符合计算机高效计算要求的数据结构。
三要素
知识图谱的组成三要素包括:实体、关系和属性。
实体:又叫作本体(Ontology),指客观存在并可相互区别的事物,可以是具体的人、事、物,也可以是抽象的概念或联系。实体是知识图谱中最基本的元素。
关系:在知识图谱中,边表示知识图谱中的关系,用来表示不同实体间的某种联系。
属性:知识图谱中的实体和关系都可以有各自的属性
01
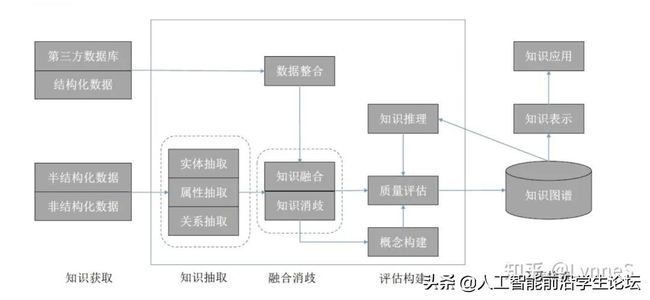
知识图谱的体系架构
知识图谱构建流程如下:
首先确定知识表示模型,然后根据不同的数据来源选择不同的知识获取手段并导入相关的知识,接着利用知识推理、知识融合、知识挖掘等技术构建相应的知识图谱,最后根据不同应用场景设计知识图谱的表现方式,比如:语义搜索、智能推荐、智能问答等。
知识源:包括结构化数据、非结构化数据和半结构化数据(知识获取)
知识图谱在逻辑结构上可分为模式层与数据层两个层次
数据层
主要是由一系列的事实组成,而知识将以事实为单位进行存储。
通常,通过本体库来管理数据层,本体库的概念相当于对象中“类”的概念。借助本体库,我们可以管理公理、规则和约束条件,规范实体、关系、属性这些具体对象间的关系。
模式层
构建在数据层之上,主要是通过本体库来规范数据层的一系列事实表达。本体是结构化知识库的概念模板,通过本体库而形成的知识库不仅层次结构较强,并且冗余程度较小。
02
知识图谱表示与建模
四种方式:
(1)一阶谓词逻辑
(2)Horn逻辑
(3)产生式模型
(4)框架
框架是一种描述对象(事物、事件或概念等)属性的数据结构。在框架理论中,框架是知识表示的基本单元。一个框架由若干个槽结构组成,每个槽又可以分为若干个侧面。一个槽用于描述所描述对象某一方面的属性。一个侧面用于描述相应属性的一个方面。槽和侧面所具有的属性值分别称为槽值和侧面值。
语义网络
基本思想是在网络中,用节点代替概念,用节点间的连接弧代替概念间的关系。所以,语义网络又称联想网络。语义网络中的节点表示各种事物、概念、情况、属性、动作、状态等。每个节点可以带有若干属性,一般可以用框架或元组表示。此外,节点也可以嵌套形成一个小的语义网络。最简单的语义网络就是一个三元组,如(节点1,弧,节点2)
资源描述框架(Resource Description Framework,RDF)
它是能够对结构化的元数据进行编码、交换和再利用的基础架构。RDF假定任何复杂的语义都可以通过三元组组合来表达。三元组的形式为<对象,属性,值>或<主语,谓词,宾语>,RDF是数据模型,不是序列化模型。RDF还允许分布式定义知识,分布式定义的知识还可以合并。
Web本体语言(Web OntologyLanguage,OWL)
OWL是知识图谱语言中最规范、最严谨、表达能力最强的语言,它使表示出来的文档具有语义理解的结构基础。OWL主要包括头部和主体两部分,在描述本体时会预先指定一系列的命名空间,包括xmlns:owl,xml:rdf等,并使用命名空间中预定义的标签形成本体的头部。
03
三大技术
通过知识抽取技术,可以从一些公开的半结构化、非结构化的数据中提取出实体、关系、属性等知识要素。
通过知识融合,可消除实体、关系、属性等指称项与事实对象之间的歧义,形成高质量的知识库。
知识推理,则是在已有的知识库基础上进一步挖掘隐含的知识,从而丰富、扩展知识库。分布式的知识表示形成的综合向量对知识库的构建、推理、融合以及应用均具有重要的意义。
知识抽取
就是从各种类型的数据源中提取实体、属性以及实体间的相互关系,在此基础上形成本体的知识表述。知识图谱的构建过程中存在大量的非结构化或者是半结构化数据,这些数据在知识图谱的构建过程中需要通过自然语言处理的方法进行信息抽取。从这些数据中,我们可以提取出实体、关系和属性。
抽取是构建知识图谱的第一步。简单地说是一个输入和输出的过程。
输入是未知的文本信息
输出是具有固定格式、无二义性的数据信息。
知识抽取有三个主要工作:
- 实体抽取:在技术上我们更多称为 NER(named entity recognition,命名实体识别),指的是从原始语料中自动识别出命名实体。由于实体是知识图谱中的最基本元素,其抽取的完整性、准确、召回率等将直接影响到知识库的质量。因此,实体抽取是知识抽取中最为基础与关键的一步;
- 发展历程:
- 通过字典和规则来识别实体。
- 传统的机器学习利用HMM、MEMM、CRF算法模型
- HMM是一种生成式模型,也就是通过联合概率P(Y,X)直接建模输入文本X和输出标签序列Y。HMM将待测的标签序列视作隐变量,将输入文本X视作由这些隐变量经由马尔可夫随机过程生成的结果。因此,对输入文本求解最优标签序列过程可以建模为Y_hat=argmaxP(Y,X)。
- 而CRF是一种判别式模型,它可以直接建模并求解使P(Y|X)最大的Y。
- 深度学习(nlp),RNN-CRF或者CNN-CRF深度学习模型来识别实体。
- BiLSTM-CRF
- 深度学习模型需要CRF提供更多的标签之间的转移概率,即上下文信息。
- 注意力模型和迁移学习在NLP的最基本的几个任务上都有很好的应用。利用Transformer、ELMo、BERT模型提高NER识别率成为识别命名实体的首选。
- 发展历程:
- 关系抽取:目标是解决实体间语义链接的问题,早期的关系抽取主要是通过人工构造语义规则以及模板的方法识别实体关系。随后,实体间的关系模型逐渐替代了人工预定义的语法与规则。
- 方法:
- 第一种是基于模式或规则的方式。
- 第二种方法是基于学习的抽取。基于学习的抽取包括基于监督学习的方式、基于远程监督学习的方式及基于深度学习的方式。
- 1.基于RNN
- 循环神经网络。可以采用RNN建模句子的关系来抽取的方法。
- 2.基于CNN
- 基于卷积神经网络进行关系抽取的主要思想为:使用卷积神经网络对输入语句进行编码,基于编码结果并使用全连接层及激活函数对实体对的关系进行分类
- 模型会先将每个句子转化为稠密实数向量,然后利用卷积、池化和非线性转换等操作构建对应的句向量。基于CNN的输入和基于RNN的输入是一样的,输入为原始句子,然后转变为word2vector,加入位置向量。其基本思想是离实体越近的词通常包含越多的关于分类有用的信息。
- 将数据经过CNN处理后,使用注意力机制对新的句子进行加权处理,力图降低噪声数据的权重
- 1.基于RNN
- 方法:
- 属性抽取:属性抽取主要是针对实体而言的,通过属性可形成对实体的完整勾画。由于实体的属性可以看成是实体与属性值之间的一种名称性关系,因此可以将实体属性的抽取问题转换为关系抽取问题。
知识表示
近年来,以深度学习为代表的表示学习技术取得了重要的进展,可以将实体的语义信息表示为稠密低维实值向量,进而在低维空间中高效计算实体、关系及其之间的复杂语义关联,对知识库的构建、推理、融合以及应用均具有重要的意义。graph embedding 就是一种表示学习。
知识融合
知识融合:主要工作是把结构化的数据以及信息抽取提炼到的实体信息,甚至第三方知识库进行实体对齐和实体消歧。这一阶段的输出应该是从各个数据源融合的各种本体信息。
知识融合的对象包括知识体系的融合和实例的融合。
知识体系的融合就是两个或者多个异构知识体系进行融合,可以对相同的类别、属性、关系进行映射。
实例的融合是对来自两个不同知识库中的实例(包括实体实例、关系实例)进行融合。
知识融合的核心是计算两个知识图谱中两个节点或边之间的语义映射关系。知识图谱中最重要的是实体,在知识融合的过程中实体对齐和实体消歧是主要的工作。
实体对齐也被称作实体匹配,用来判断两个来自不同或者相同知识库中的实体是否表示同一对象的过程。实体对齐可以分为成对实体对齐和协同实体对齐两类不同的算法。成对实体对齐是独立判断两个实体是否对应同一对象的过程,通过匹配实体的属性判断它们是否对齐。协同实体对齐是从更大的范围考虑两个实体是否对应同一对象的过程,通过协调不同对象间的匹配情况达到全局最优。
方法:
传统的方法;是计算两个实体的相似度.
基于表示学习的方法就是把来自各个知识库的实体表示在同一个语义向量空间,然后计算两个实体的相似度。这样,实体对齐就转化为实体相似度计算的问题。
实体消歧的目标是消除指定实体的歧义。歧义是指同样一个词有可能所表达的含义是不同的。实体消歧任务从技术路线上可以分为实体链接和实体聚类两种类型:
实体链接是指给定目标实体列表,将实体指称项与目标实体列表中的对应实体进行链接,实现消歧。
实体聚类是指未给定目标实体列表,以聚类方式对实体指称项进行消歧。所有指向同一个目标实体的指称项被聚类到同一类别下,聚类结果中每一个类别对应一个目标实体。
知识推理
可以用于补全知识图谱和质量检测等。知识推理包含对知识的思考、认知和理解等过程,是认知世界的重要途径。
知识推理按照推理的过程分为逻辑推理和非逻辑推理:
逻辑推理又分为演绎推理(Deduction)、归纳推理(Induction)、设证推理(Abduction,也称溯因推理)。从推理方法上看,推理主要分为确定性推理、不确定性推理。
确定性推理大多指确定性逻辑推理,具有完备的推理过程和充分的表达能力,可以严格地按照专家预先定义好的规则准确地推导出最终结论。确定性推理很难应对真实世界中,尤其是对于网络大规模知识图谱中的不确定,甚至不正确的事实和知识。
不确定性推理也被称为概率推理,它并不是严格地按照规则进行推理,而是根据以往的经验和分析,结合专家先验知识构建概率模型,并利用统计计数、最大化后验概率等统计学的手段对推理假设进行验证或推测。不确定性推理可以有效地对真实世界中的不确定性建模。概率软逻辑是给定一组原子事实和绑定权重的规则,计算所有可能的原子事实真值取值为I的概率分布。
基于分布式的知识推理
分布式知识表示(Knowledge Graph Embedding)的核心思想是将符号化的实体和关系在低维连续向量空间进行表示,在简化计算的同时最大限度地保留原始的图结构。
基于分布表示的知识推理步骤如下。
- 实体关系表示:定义实体和关系在向量空间中的表示形式(向量/矩阵/张量)。
- 打分函数定义:定义打分函数,衡量每个三元组成立的可能性。
- 表示学习:构造优化问题,学习实体和关系的低维连续向量表示。根据打分函数的不同,我们可以把分布式表示知识推理分为两种类型,一种是采用基于距离打分函数来衡量三元组成立可能性的模型,称作位移距离模型;另一种是采用相似度计算的打分函数来衡量三元组成立可能性的模型,称作语义匹配模型。
知识加工:知识推理中重要的工作就是知识图谱的补全。常用的知识图谱的补全方法包括:基于本体推理的补全方法、相关的推理机制实现以及基于图结构和关系路径特征的补全方法。
是高层次的知识组织,使来自不同知识源的知识在同一框架规范下进行异构数据整合、消歧、加工、推理验证、更新等步骤,达到数据、信息、方法、经验以及人的思想的融合,形成高质量的知识库。
知识更新:是一个重要的部分。人类的认知能力、知识储备以及业务需求都会随时间而不断递增。因此,知识图谱的内容也需要与时俱进,不论是通用知识图谱,还是行业知识图谱,它们都需要不断地迭代更新,扩展现有的知识,增加新的知识。
质量评估就是对最后的结果数据进行评估,将合格的数据放入知识图谱中。
参考
数据科学一线
智能搜索和推荐系统
推荐下我自己建的Python学习群:[856833272],群里都是学Python的,如果你想学或者正在学习Python ,欢迎你加入,大家都是软件开发党,不定期分享干货,还有免费直播课程领取。包括我自己整理的一份2021最新的Python进阶资料和零基础教学,欢迎进阶中和对Python感兴趣的小伙伴加入!还可以扫码加VX领取资料哦!
