吴恩达课程笔记-第二课 高级学习算法(主讲神经网络)
目录
概论
神经网络模型基本建立流程
神经网络前向传播
基于TensorFlow的模型训练过程(基础版-模型,策略,算法)
神经元的激活函数选择
为什么要使用激活函数?
激活函数-softmax回归
多类别分类问题-softmax
一般神经网络模型-隐藏层用ReLU,输出层用Softmax
Tensorflow中损失函数计算产生的精度误差问题(Tensorflow代码-改进版)
多标签分类问题(Multi-label classification)
Adam下降算法代替梯度下降法
其他网络层类型(卷积层)
评估和诊断神经网络(当效果不好时,该怎么办?)
模型评估
模型选择&交叉验证
诊断方法:偏差和方差
正则化如何影响偏差和方差
如何评价偏差和方差的高低(过拟合or欠拟合)
学习曲线
根据方差、偏差优化模型
机器学习系统开发流程
误差分析(给模型改进方法进行排序)
添加更多数据(数据增强、数据生成)
迁移学习(预训练)
机器学习项目的完整周期
正负样本比例倾斜时的误差目标(精度、召回率)
精度与召回率间的权衡
决策树模型
构建决策树的关键
一组样本的纯度(用熵代表不纯度)
如何选择特征(信息增益)
决策树构建流程
One-hot编码(当特征的值不止两类)
输入特征值为连续值时(离散数字)
回归树(输出为数字而不是类别)
使用多个决策树(集成树)
有放回抽样
随机森林
XGBoost——最常用的决策树
何时使用决策树(决策树VS神经网络)
自己的疑问与解答
多层感知机(MLP)、全连接神经网络(FCNN)、前馈神经网络(FNN)、深度神经网络(DNN)与BP算法(反向传播)关系
模型的健壮性/鲁棒性
概论
本部分主要讲的是监督学习方法,其中最重要、最常用的方法是神经网络(深度学习)和XGBoost,神经网络擅长处理非结构化数据(图像、音频、文本等)及结构化数据,XGBoost擅长结构化数据(表格数据)。所以神经网络更加首选,但其训练周期长,而决策树训练更快
神经网络模型基本建立流程
神经网络前向传播

输入数据X矩阵中每一行是一条数据,其通过与W矩阵(一列代表一个神经元的参数,不同行代表不同特征的参数,这里说明输入是2个特征,该层3个神经元,所以2*3)进行矩阵相乘,再加上b,得到Z,一行对应一个样本,3列对应这一层有3个神经元,再利用sigmoid函数得到g(Z),即该层的输出,输入到下一层。
一般输入层也可看做layer0,然后是隐藏层layer1,layer2,layer3,最后输出层layer4,这里以4层为例
基于TensorFlow的模型训练过程(基础版-模型,策略,算法)

分为三步:
1-如何通过输入x,参数w,b来计算得到输出(模型 如sigmoid函数(logistic回归))
2-构造损失函数(策略 如交叉熵损失函数(logistic loss))
3-最小化损失函数的方法(算法 如梯度下降法)
其中,第三步中计算偏导是重点,利用反向传播算法。TensorFlow在fit函数中实现反向传播
神经元的激活函数选择
主要的四类激活函数:sigmoid,Relu函数(max(0,z)),线性函数(g(z)=z),softmax函数
在输出层,根据目标输出选择激活函数,如果是二分类问题一般选sigmoid函数,如果是多分类问题选择softmax。对于回归问题,如果有正有负,一般选y=x(线性相当于没有),如果结果一定是正的,选Relu函数
在隐藏层,一般都选择Relu函数,几乎不用sigmoid函数,因为Relu效率更高,而sigmoid函数左右都有平坦区,导致梯度下降慢。

为什么要使用激活函数?
答:如果不使用激活函数,也就是相当于激活函数都用线性激活函数linear的话,那么多层神经元的作用将和一层神经元一样,而并没有使模型复杂,所以在隐藏层需要ReLU激活函数

激活函数-softmax回归
softmax回归是逻辑回归的推广,它俩虽然都叫回归,但实际上是用于分类问题
损失函数Loss: 实际上只会由标签值决定,是哪个类别只计算该类别的-log(a_j)
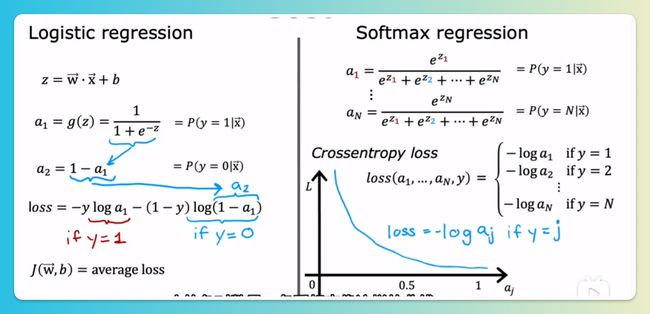
多类别分类问题-softmax
一般神经网络模型-隐藏层用ReLU,输出层用Softmax

softmax与其他三种激活函数的不同之处在于:以a1为例,其他三种激活函数a1只受z1影响,即只受一个神经元影响,但softmax的a1受z1~z10的影响,即受所有神经元影响。
Tensorflow中损失函数计算产生的精度误差问题(Tensorflow代码-改进版)

如果像之前一样,输出层激活函数用sigmoid,模型配置时不加参数,则形成的效果会先计算出中间量a,再计算loss,由于多了一步,误差也就增大了。所以改进方案是取消中间量a,直接把z的表达式代入,代码中的改变为最后一层激活函数为线性激活函数,把激活函数sigmoid和交叉熵损失封装在特殊函数中,即from_logists=True的作用。
这样做的缺点使代码易读性差(容易看不出输出层是sigmoid),但数字舍入误差变小了
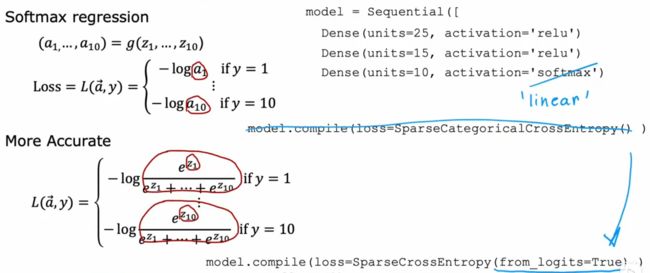
softmax这里同理,用改进代码,输出层输出的是z1,z2...z10的值,损失函数计算封装在了from_logists=True中
所以,改进的Tensorflow代码为

模型model输出的是z而不是a值(概率),所以预测时要加上tf.nn.softmax()转换为概率
同理,如果是逻辑回归,则用sigmoid(logit)转换成概率

多标签分类问题(Multi-label classification)
可能一张照片输入有多个关联标签,如检测图片中是否有轿车、公共汽车、行人,有两种方案

方案1:建立三个神经网络,分别进行预测,不推荐
方案2:只建立1个神经网络,输出层包含3个神经元,激活函数均用sigmoid,相当于3个二分类问题,分别判断是否有car, 是否有bus,是否有行人
Adam下降算法代替梯度下降法
梯度下降法中学习率α是固定的,有时可能过大有时过小,使得效率低
一种高级优化方法——"Adam"算法,可以自动调整学习率,提高损失函数下降效率
Adam基本思路为:如果每次下降方向相似,则增大学习率,如果每次下降方向差别太大,则缩小学习率。例如,对于10个参数w和1个b,每个参数都会有不同的学习率,所以会有11个学习率
tensorflow代码:

改变在模型配置中,使用Adam算法需要给初始learning_rate,之后会自动调参,调参时可以多尝试几个值
相比于梯度下降法,会使学习率选择更具有健壮性/鲁棒性(因为更能容错,容学习率选择的错)
一般都使用Adam算法代替梯度下降法
其他网络层类型(卷积层)
之前学过的隐藏层和输出层都是全连接层(dense layer),即该层中的所有神经元都从前一层中得到所有的激活
全连接层中每个神经元的输入都是上一层的所有输出
卷积层中每个神经元只关注输入图像的一个区域

优点:1-更快的计算速度;2-需要更少的训练数据(可减少过拟合)
如果神经网络中有多个卷积层,则这时网络成为卷积神经网络(convolutional neural network, CNN)
举例:以心电图判断是否得病为例,输入为100个时刻的电极差,输出为二分类问题

其中layer1和layer2都是卷积层,每个神经元都只分析上一层输出的部分,而不是全部,通过选择分析哪些部分可以组合成不同的网络,最后layer3输出层用sigmoid激活函数,输出为二分类。因为有多个卷积层,所以是卷积神经网络CNN
最新前沿模型Transformer、LSTM(长短期记忆网络)、attention(注意力模型)
评估和诊断神经网络(当效果不好时,该怎么办?)
例子:构建带正则化的线性回归模型,但发现训练出的模型效果不好,该怎么办?

可以选择:增加训练数据;减少特征;增加额外特征;增加多项式特征;改变正则项系数
如果做可以高效改善结果,就是本章的研究内容
模型评估
一般采用把数据集分为训练集train和测试集test来评估模型的性能

用训练集数据的最小化代价函数得到参数值,然后分别在测试集和训练集上计算代价函数,且没有正则项
随着训练次数增加,J_train都会减少,但如果J_test较大,则说明模型泛化能力差,需增加数据获提高正则项系数或改变模型
以上是回归问题,在分类问题中也是如此,但分类问题中可以用标签判断代替,J_test就相当于测试集中预测错误的次数,J_train是训练集中预测错误的次数
模型选择&交叉验证
对于如何选择模型,采用交叉验证的方法。把数据分为训练集(60% train)、交叉验证集(20% cross validation 简称验证集)、测试集(20% test)
专门用交叉验证集来选择模型
以回归问题为例

选择那个模型的交叉验证集代价函数最小,就选择该模型
最后得到的参数再在测试集上计算代价函数,以表明模型的泛化性(这也是单独用交叉验证集来选择模型而不是直接用测试集的原因 怕影响泛化能力)
该方法也可用于其他模型选择,例如神经网络
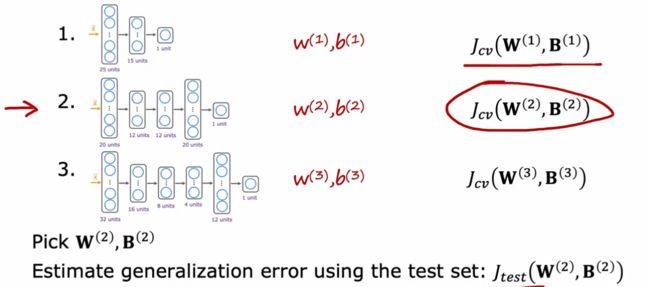
对于分类问题,在验证集上的代价函数一般用错误分类所占的百分比来表示。在训练集上得到参数,在交叉验证集上选择模型,确定后最后才用测试集上的结果代表模型泛化能力
诊断方法:偏差和方差
以简单的回归问题为例
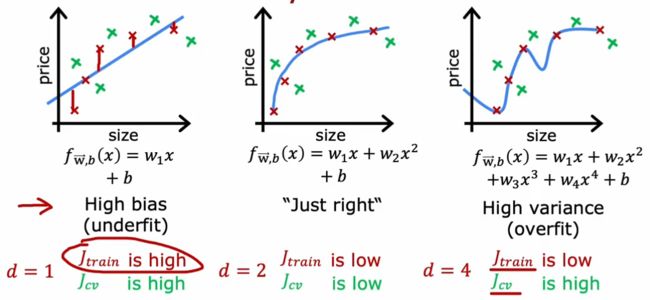
左边情况是高偏差(欠拟合),右边情况是高方差(过拟合),所以可以通过训练集和交叉验证集上的偏差和方差诊断是否欠拟合/过拟合
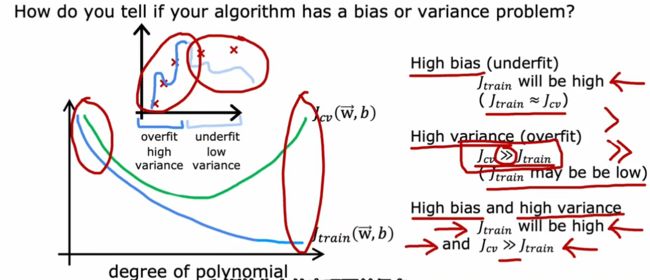
高偏差(欠拟合)说明算法在训练集上表现不好,高方差(过拟合)说明算法在交叉验证集的表现比训练集上差很多
可以用J_train代表偏差,J_cv-J_train代表方差
特殊情况(某些复杂的神经网络)会出现高偏差和高方差的情况,就是在某些部分过拟合,某些部分欠拟合,此时J_train很高,J_cv更高。此种情况很少
正则化如何影响偏差和方差
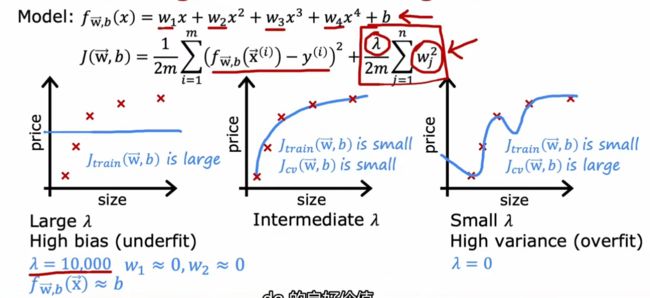
当正则项系数很大时,会牺牲拟合效果来简化模型,即出现欠拟合
当正则项系数很小时,模型会非常复杂,而以拟合效果为重,即出现过拟合
可使用交叉验证来选择正则项系数

选择使J_cv最小的正则项系数
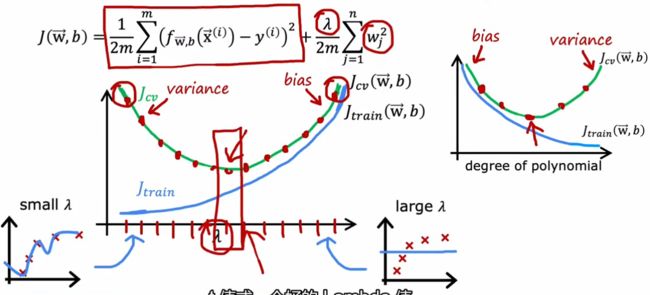
λ小时,方差大,过拟合;λ大时,偏差大,欠拟合,最后选择使J_cv最小的正则项系数
这与前面的模型选择时(横坐标为多项式次数)似乎是镜像对称。但在分别确定模型和正则项系数时均可采用交叉验证方法
如何评价偏差和方差的高低(过拟合or欠拟合)
建立期望误差基准的几种方法:1-人类的表现;2-类似算法的表现;3-基于经验

是否高偏差是看J_train和基准之间差值;是否高方差是看J_cv和J_train之间的差值
学习曲线
随样本数量增加,J_cv会逐渐减小,J_train会逐渐增加,但会小于J_cv
样本数量少时,过拟合问题严重,增加样本数量可减少过拟合问题
高偏差情况:

如果一个学习算法有很高的偏差,那增大训练数据本身不会有太多帮助,会让偏差更大。(此时重点是减少偏差,所以不宜增大样本而应把重点放在模型等)
高方差情况:
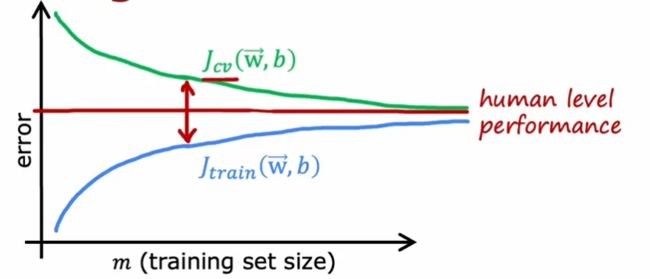
当方差大时,增大样本量是个好的解决办法(此时解决过拟合问题是重点)
根据方差、偏差优化模型
如果算法有高偏差(原因为不够复杂):1-尝试额外特征;2-尝试增加多项式特征;3-减小正则化项系数(让模型更复杂)
如果算法有高方差(原因为样本数量少或过于复杂):1-增加样本数量;2-尝试更少特征;3-增加正则化项系数(让模型更简单)
通用流程:
1-训练模型,看它在训练集上表现,可通过计算J_train,看它是否偏高
2-如果高偏差,则使用更强大的神经网络(更多隐藏层、每层更多神经元)。可不断重复1,2,直到J_train足够小,达到期望
3-看模型在交叉验证集上表现,即看方差是否偏高,计算J_cv-J_train,如果方差很大,则获取更多数据,不断循环。

该方法局限性:算力成本高; 扩大数据量不易
研究表明,当使用更强大的神经网络时(层数和神经元数更多),只要做好正则化,不会增加过拟合。
代码中增加正则化项:增加kernel_regularizer参数,括号内为正则项系数,每层可以选不一样的

机器学习系统开发流程
1-决定系统框架(模型、数据等)
2-训练模型
3-诊断模型(利用偏差、方差、误差诊断)
回到第一步改变模型(如:使神经网络模型变大;改变lambda正则化参数;增加数据;增加特征或减少特征)。
不断循环直到想要的性能

误差分析(给模型改进方法进行排序)
对于如何改进模型,偏差和方差第一重要,误差分析第二重要
针对交叉验证集,把预测错误的样本找出来,进行手动检查分析,找共同特点/属性
例如,垃圾邮件筛查,500份的交叉验证集中100份出错,进行手动分析,发现21份是医药相关,18份是钓鱼邮件,那就应该着重这两方面去解决问题。

如,对于医疗邮件问题:可着重增加该方面的样本数量;增加医药相关关键词特征
对于钓鱼邮件问题:可着重增加该方面样本数量;增加相关特征(如链接)
如果是5000个交叉验证样本中1000个出错,那每个都去查看的话看不过来,就可随机抽取1组(如100个)去进行手动分析。误差分析适合于人类擅长的问题
偏差和方差决定是否要增加样本、增加或减少特征;误差分析决定增加什么样的样本,增加或减少什么样的特征
添加更多数据(数据增强、数据生成)
添加更多的典型错误的数据,会更加有效
对于图像:可以旋转、放大、缩小、调对比度、取镜像
对于语音识别:加噪声(人群背景、汽车背景)、录音设备不良时录制
通过引入网格的随机扭曲(introducng distortions 引入失真)来增加数据量:

对于有干扰的视觉识别任务,如OCR图片中识别文字,除了真实数据外,可以利用电脑中的字体,用不同颜色、对比度、字体,生成数据

有一些应用中,很难获取更多数据,可应用迁移学习,关键思想是从几乎没有关联的任务中获取数据
迁移学习(预训练)
首先在大型数据集上进行训练,然后在较小的数据集上进一步参数调优
举例:先拿1百万数据、1000个类别的数据集进行训练网络,然后再把网络的最后一层变成对应数字的10个神经元进行训练。方法1:隐藏层参数都不变,只训练输出层参数(数据量非常少时采用);方法2:所有层参数都进行训练,但隐藏层初始值使用大数据集训练好的参数
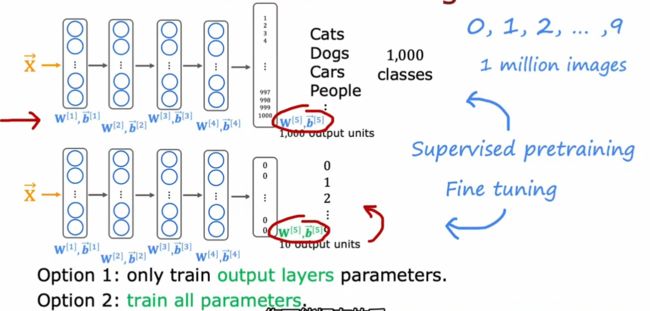
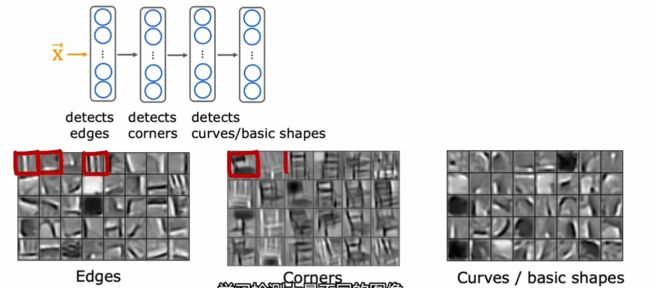
为什么迁移学习能起作用?
因为同一类型任务的工作流程基本一致。以图像任务为例,一般第一层检测边缘、第二层检测角、第三层检测基本形状。所以不同任务可以互用
注意:大任务和小任务需是同一类型(都是图像检测任务,图像的尺寸也需一致)
迁移学习总结(两个步骤):1-下载带有参数的神经网络(很少自己训练),这些参数已经在与目标应用相同输入类型的大型数据集上训练过了;2-根据自己目标任务进行微调
迁移学习中的成功应用:GPT-3、bert、ImageNet
机器学习项目的完整周期
全流程图:1-确定目标问题,如语音识别问题;2-收集数据和标签值;3-训练模型,根据偏差、方差、误差分析,进一步完善模型,可能需要补充特定数据集(可以数据增强,数据生成);4-部署模型,也许在应用中效果并不好,需要返回来训练模型、补充数据

部署(软件工程):通常采用API调用的方式,用专门服务器来进行神经网络模型预测

对于大的项目,一般需要专门的软件工程团队进行部署和监控数据,有了新的数据后可进一步优化模型
正负样本比例倾斜时的误差目标(精度、召回率)
此时准确率不是合适的判断标准,例如,100个样本中95个标签为1,5个标签为0,那么,用y=0也会有95%的正确率。此时应用精度和召回率
混淆矩阵:真阳性,假阳性,假阴性,真阴性
精度:在预测为1当中有多少预测正确(真阳性/(真阳性+假阳性)) TP/(TP+FP)
召回率:在实际为1当中有多少预测正确(真阳性/(真阳性+假阴性)) TP/(TP+FN)

精度与召回率间的权衡
结合车位检测比赛,精度precision是检测出来的车位中有多少是正确的,召回recall是在所有的车位中检测出来了多少
提高阈值会提高精确度,但会减小召回。降低阈值会牺牲精确度换取召回率

如果想自动选取阈值,可采用F1评分(F1 score):将精确率和准确率合成一个函数,F1强调二者中较低的值

F1的计算公式是数学中的调和平均数
决策树模型
决策树模型是和神经网络并列的两大好用模型。在很多比赛中都有应用决策树模型的。
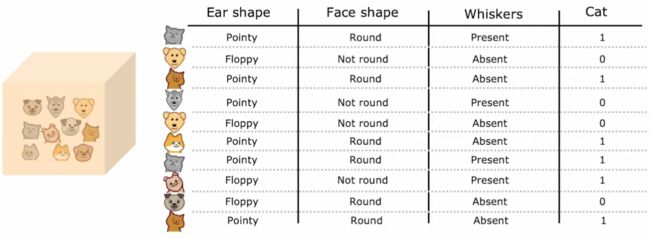
举例:判断是否为一只猫,三个特征,每个特征都两个取值。构建二叉树模型,最上面为根节点,中间的节点都称为决策节点,最底下的输出为叶子节点

构建决策树的关键
构建决策树需确定的关键两点:
- 要确定如何选择拆分每个节点的特征(选择特征的优先顺序)
- 节点何时停止分裂
- 1-100%同类;
- 2-达决策树深度(根节点为深度0,决策节点和叶子节点都算);
- 3-相邻两次纯度提升小于阈值;
- 4-样本数量过少就不再拆分
可以通过修改2,3,4阈值使决策树更小,更简单,以避免过拟合
一组样本的纯度(用熵代表不纯度)
用熵衡量一组样本的不纯度。熵越小纯度越高

按照熵的计算惯例,对数函数底取2,因为此时熵的峰值为1(数字好看)
如何选择特征(信息增益)
决定使用什么样的特征来划分一个节点取决于什么样的特征选择最能减少熵(最大化纯度)。熵的减少称为信息增益。
例如:有3种可选择的特征,每种都可计算两个分支的熵,因为需考虑分支样本数量,所以计算两个分支的加权平均熵,代表分支的不纯度,再用分裂前的熵-分裂后的加权平均熵,得到熵减(信息增益),选择熵减大(信息增益大)的特征

信息增益的基本公式:

其中p1代表类别1(是猫)在样本集中的比例,w_left代表左分支样本占总样本比例
决策树构建流程
1-从根节点开始,计算所有特征的信息增益(熵减),选择信息增益最大的特征进行分裂
2-根据选择特征划分数据,创建左右分支
3-直到满足停止分裂条件前重复分裂过程(每次分裂特征都是在没用过的里面选)
- 本节点均为同类别(熵为0)
- 达到深度,则直接变叶子节点不再分裂
- 信息增益小于阈值(熵减不够大)
- 节点样本数量小于阈值,不再分裂
大决策树的左右分支又都是小子决策树,这在计算机中用递归算法进行编程
增大深度,减少上面的3 4 项阈值,会让决策树模型更复杂,增大过拟合风险
One-hot编码(当特征的值不止两类)
当某个特征具有k个离散值时(超过2个),则用k个0/1来代替,把一个特征变成k个特征

如图,当耳朵形状这个特征具有3个值时,变成了3个0-1组合,其余两个特征不变,加起来是三个特征变成了5个特征
除了应用于决策树,one-hot编码也可用于神经网络,用于输入特征有多个类别时
输入特征值为连续值时(离散数字)
关键在于确定中间值——标准是信息增益最大的
取所有值排序的两两中间值作为候选值,如有10个训练样本(每个值都不同),则有9个候选阈值
分别计算信息增益,取信息增益最大的阈值,作为该特征的分割点

如图中,weight=9时信息增益比8和13时更大,所以更适合进行切分
回归树(输出为数字而不是类别)
关键点依然是选择特征
在分类问题中,我们使用熵来度量一组样本不纯度,而在回归问题中,我们用方差来代替熵
用分割前的样本方差减去分割后的加权平均方差,作为选择特征的指标(方差减少最大化)

使用多个决策树(集成树)
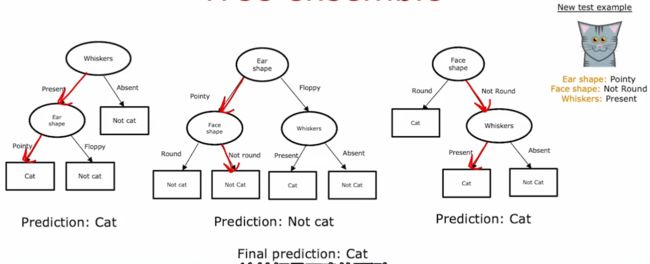
如果只建立单一的决策树,则健壮性差(当样本中有微小变化时,可能整个决策树都会从上到下变化),所以应建立多个决策树,使预测结果对其中任何一棵树都没那么敏感,增强模型健壮性
一个好的模型应具有健壮性:当观测数据(或其他相关信息)有微小变动时,模型结构和参数只能相应有些微小变化,并导致模型求解的结果也只能有相应的微小变化。
所以,应建立多个决策树,分别预测,然后投票决定结果。后面几个视频会讲如何建立这几个决策树。
有放回抽样
集成树(集成学习)中应用放回抽样
 10个样本,抽10次,可能里面也会有重复的,但没关系,这样可以构建一个决策树
10个样本,抽10次,可能里面也会有重复的,但没关系,这样可以构建一个决策树
通过这种方式,构建多个决策树,再进行集成 (Bagging 随机森林 并行集成)
随机森林
通过放回抽样的方式,建立B个决策树模型,预测时会得到B个结果,然后通过投票决定最终结果

当特征量大时,通常做法不是每个决策树都从所有特征里选,而是为了提升效率,随机选取部分特征,一般是总特征数开方
因为每个决策树的输入样本都会有细微变化,所以最后再综合考虑时就会使整体模型健壮性增强
XGBoost——最常用的决策树
在构建下一个新决策树时,在选取样本时会着重选取上个决策树处理效果不好的样本。并且在最终投票时,也要根据每个决策树的预测效果决定权重,而不是简单平均。这就是Boosting的基本思想。
Boosting流程:抽样时会着重提高抽到上一个决策树表现不好样本的概率。
Boosting中当今应用最广泛的是XGBoost(Extreme Gradient Boosting 极端梯度提升),其内置了正则化项;关于拆分条件及合适停止拆分都有默认选择;在Kaggle竞赛中XGBoost是一种具有高度竞争性的算法(XGBoost和神经网络是表现最好的两种算法)。
不需要进行有放回的采样,下一个决策树都会根据上一个的效果来进行建立(具体看李航的书)
简单使用流程:

何时使用决策树(决策树VS神经网络)
决策树和提升树的特点:
- 擅长处理表格数据(结构化数据)。无论分类还是回归,数据中是否有离散值,都可用决策树。
- 不擅长处理非结构化数据(图像、视频、音频、文本)
- 训练快是巨大优势
- 小型决策树具有可解释性
如果要用决策树或集成树解决问题,极力推荐XGBoost
神经网络特点:
- 可以处理任何类型数据,包括结构化和非结构化
- 训练周期长,比决策树慢
- 能够使用迁移学习,这非常重要
- 构建大型系统,集成多个模型时,使用神经网络会比决策树更容易(把不同神经网络模型集成在一起,可以使用梯度下降同时训练,但决策树一次只能训练一棵树)
自己的疑问与解答
多层感知机(MLP)、全连接神经网络(FCNN)、前馈神经网络(FNN)、深度神经网络(DNN)与BP算法(反向传播)关系
参考链接:(66条消息) 多层感知机(MLP)、全连接神经网络(FCNN)、前馈神经网络(FNN)、深度神经网络(DNN)与BP算法详解_生信小兔的博客-CSDN博客_多层感知机和全连接神经网络
第一部分讲关系,后面讲每个的推导
MLP是指模型采用的感知机模型;FCNN指从结构上看,每层中的神经元的输入都是上一层输出的全部,而不是部分(如果是部分就是卷积层);FNN是指从数据流动方向上看,数据是从左到右单向传递;BP反向传播是指训练时最常用的训练方法就是反向传播,利用这样BP算法来训练这样的神经网络,就可以称作BP神经网络。
BP神经网络一定是MLP, FCNN, FNN,但如果该神经网络不用BP算法进行训练,就不能叫做BP神经网络了。
DNN深度神经网络,对应的是浅层神经网络SNN。对于一般的FCNN/FNN/MLP,它们往往使用sigmoid作为激活函数,但是这个激活函数有一个缺点:随着神经元层数的增加,会出现梯度消失,为了避免梯度消失,可以减少神经元层数,也就是某种意义上的SNN。如果增加更多的神经元的层数,同时避免梯度消失,可以采用ReLU等激活函数,此时在某种意义上来说可以是深度神经网络。
模型的健壮性/鲁棒性
一个好的模型应具有健壮性:当观测数据(或其他相关信息)有微小变动时,模型结构和参数只能相应有些微小变化,并导致模型求解的结果也只能有相应的微小变化。
所以在决策树中一般会构建多个决策树而不是采用单一的决策树,以增强整体健壮性。