pandas学习笔记(1)

学习网址:kaggle
注:本文仅为个人总结,不作为任何学习资料
一、在pandas里有两种Core objects:DataFrame和Series
DataFrame的使用方法:
DataFrame有两个方向,纵向为index,横向为column
定义一个DataFrame的时候可以将Column和数据放在一起定义,也可以将数据和Column分开写,但是index是需要分开的
例1:
import pandas as pd
a=pd.DataFrame({'apple':[1,2,3],'banana':[4,5,6]},
index=['price','num','quality'])
这样定义出来的a形如:
| apple | banana | |
|---|---|---|
| price | 1 | 4 |
| num | 2 | 5 |
| quality | 3 | 6 |
例2:
import panda as pd
a=pd.DataFrame([[1,4],[2,5],[3,6]],
columns=['apple','banana'],
index=['price','num','quality'])
这样做出来的表和上面一样的
例1中定义出来的apple对应Column的第一列,而1,2,3为这一列上的数据值;例2中的数据是按照行来一行一行声明的。
Series和DataFrame定义方法类似,唯一不同的是,Series类似于python中的list,下面来看一下其定义方法:
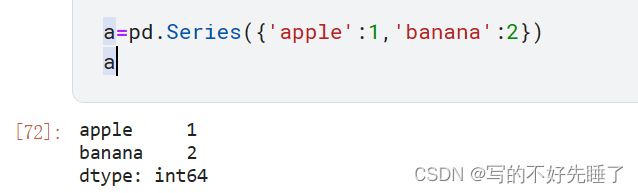
例1:
a=pd.Series({'apple':1,'banana':2})
结果如下所示:
例2:
a=pd.Series([1,2],index=['apple','banana'])

二、接下来是数据的选择,索引(?)
主要介绍的是loc和iloc
iloc只能用python形式的索引来索引即数据索引,并且使用0:9索引的时候返回的0~8,而loc索引时返回的是0 ~9,原因在kaggle课程里有详细讲解
loc介绍:
使用loc的时候是[a,b]其中a是index,而b是column

也可以不加b,单独用a:

iloc介绍:
iloc和loc基本相同,差别在于iloc的第二个参数不能用字符串只能用数据进行索引:

三、下面是一些数据处理涉及到的函数
使用describe函数描述序列的很多内容,比如说最大值、均值等,使用mean()可以返回均值,使用value_counts()返回各个数据的出现次数,unique()返回去重结果,median()返回中位数,idxmax()返回最大值对应的索引。
下面是map函数和apply函数的介绍:
map函数和apply函数中
map函数仅适用于Series,apply函数用于DataFrame上
举例:
map函数中括号内调用的参数为一个函数,这有点类似于sort函数的comp,而该函数可以是匿名函数,也可以是实在函数,在下面的例子中reviews是一个DataFrame类型的变量
例1:
a=reviews.points.map(
lambda p: p-reviews.points.mean()
)
例2:
def yh(a):
if(a==0):
return 1
else:
return 0
a=reviews.points.map(yh)
结果:

而对于apply函数,第二个参数可以选择’columns’或者是’index’,选择’columns’的时候传入函数的参数是一行,而选择’index’的时候传入函数的参数是一列
下面以’columns’参数为例来说明apply函数的用法
我之前认为apply函数只能作用于DataFrame,但事实上他也可以返回值,从而形成一个Series序列
例1:返回Series序列

例2:作用于DataFrame