异常检测——深度学习异常检测经典算法最终篇
本文转载自:https://blog.csdn.net/smileyan9/article/details/106587227/
《异常检测——从经典算法到深度学习》
- 0 概论
- 1 基于隔离森林的异常检测算法
- 2 基于LOF的异常检测算法
- 3 基于One-Class SVM的异常检测算法
- 4 基于高斯概率密度异常检测算法
- 5 Opprentice——异常检测经典算法最终篇
- 6 基于重构概率的 VAE 异常检测
- 7 基于条件VAE异常检测
5 Opprentice 系统
- 《异常检测——从经典算法到深度学习》
- 5 Opprentice 系统
-
- 5.0 ABSTRACT
- 5.1 INTRODUCTION
-
- 5.1.1 异常检测算法面临的挑战:
- 5.1.2 论文中介绍的方法依赖于两个关键观测(key observation):
- 5.1.3 论文的主要贡献:
- 5.2 BACKGROUND
-
- 5.2.1 KPIs 与 KPI Anomalies
- 5.2.2 Problem and Goal
- 5.3 OPPRENTICE OVERVIEW
-
- 5.3.1 核心思想
- 5.3.2 机器学习的挑战
- 5.4 DESIGN
-
- 5.4.1 体系结构
- 5.4.2 标签工具(Labeling Tool)
- 5.4.3 检测器 (Detector)
-
- 1)检测器用作提取器
- 2)检测器的选择
- 3)采样参数
- 5.4.4 机器学习
-
- 1)思考和选择
- 2)随机森林
- 5.4.5 配置分类阈值(Configuring cThld)
-
- 1) PC-Score: 选择合适 cThld 的指标
- 2)基于EWMA的 cThld 预测
- 5.5 EVALUATION
-
- 5.5.1 数据集
- 5.5.2 检测器与参数选择
- 5.5.3 随机森林的精度
-
- 随机森林 vs 基本检测器和基本探测器的静态组合
- 随机森林 vs 其他算法
- 5.5.4 增量训练 (Incremental Retraining)
- 5.5.5 PC-Score vs 其他精度指标
- 5.5.6 cThld 预测中,EWMA vs 5-fold
- 5.5.7 打标时间 vs 调谐时间(Labeling Time vs. Tuning Time)
- 5.5.8 检测时延和训练时间(Detection Lag and Training Time)
- 5.6 DISSCUSSION
- 5.7 RELATED WORK
- 5.8 CONCLUSION
5 Opprentice 系统
论文名称:Opprentice: Towards Practical and Automatic Anomaly Detection Through Machine Learning
年份:2015
论文下载地址:https://wws.lanzous.com/id06nxa
请读者注意
- 并不是对全部论文的翻译;
- 略过了一些背景介绍;
- 对一些内容进行了概括;
- 对于翻译可能引起争议的部分保留了原文;
- 如果有错误的地方请务必指出,一定改正,万分感谢!
5.0 ABSTRACT
主要内容包括以下几点:
- Opprentice: Operators’ apprentice. 操作员学徒。
- 操作人员的唯一手工任务是使用方便的工具定期地给异常数据打标签。将多个现有检测器并行应用于性能数据中,提取异常特征。
- 然后根据这些提取出来的特征来训练生成一个
随机森林(random forest) 分类模型,使用这个模型自动地选择合适的检测器的参数组合和阈值。 - 对世界顶级搜索引擎中三种不同的KPI,Opprentice可以自动满足或接近合理准确的效果(recall>=0.66 and precision >= 0.66)
- Opprentice 让操作员可以在几十分钟内完成以前需要十多天才可能完成的任务。
5.1 INTRODUCTION
5.1.1 异常检测算法面临的挑战:
- 异常的定义。现实生活中的异常很难有个明确的定义。
- 异常的检测。选择最合适的检测方法通常需要算法经验与KPI数据相关的专业知识。效果最优的参数与阈值通常高度依赖于真实数据,所有通常需要花费大量的时间来确定异常检测算法的所有参数值和阈值,有时候甚至需要组合多种异常检测算法。因此,为了找到合适的检测模型和确定合适的参数与阈值,通常需要多次执行这种耗时的迭代操作。(操作人员调参,重现训练模型)
5.1.2 论文中介绍的方法依赖于两个关键观测(key observation):
- 操作员可以直观地检查时间序列数据并标记他们识别的异常情况。操作员唯一需要手动做的事情就是定期给新来的数据打标签(例如每周)。由于异常情况通常很少发生,因此在专用标记工具的帮助下,标记时间是相当合理的。
- 不同检测模型测得的异常严重度自然可以作为机器学习的特征,因此每个检测模型都可以作为特征提取器。接着Opprenice根据已经标记的数据进行学习,自然而然地从操作人员的标记中捕获相关的专业知识(the domain knowledge),就跟一个聪明且勤奋的学徒一样。
特别的是,多个检测算法对KPI数据进行平行的特征提取。然后这些特征与标签就可以用来训练模型,比如说随机森林,自动地选择合适的检测参数组合和阈值。
5.1.3 论文的主要贡献:
- Opprentice 是第一个将机器学习应用于获取真实异常定义、自动组合和调整各种检测器以满足操作员精度偏好的检测框架。
- Opprentice 解决了将机器学习应用于此类问题的一些挑战:标签开销、不经常出现的问题、类不平衡以及不相关和冗余的特性,这些在第3.2条和第4条中有详细阐述。
- 在一个顶级的全球搜索引擎中构建和评估Opprentice,已经实现了14个现有的检测器并将其插入Oppertice。 对于三种不同业务的KPI数据,Opprentice 可以自动满足或接近合理的精度(recall ≥ 0.66 and precision ≥ 0.66)。
- 而且,尽管Opprentice 中最优参数组合会因为KPI数据的不同而改变,但 Opprentice 不断表现得和以前相似甚至比以前更好。
- 更重要的是,Opprentice 只需要几十分钟就能完成以前操作员可能需要几十天才能完车的事情。我们相信这是第一个不需要人工选择检测器、不需要参数配置和阈值调整的框架。
5.2 BACKGROUND
5.2.1 KPIs 与 KPI Anomalies
- KPIs: KPI 数据是时间序列数据,格式为(时间戳,数值)。本论文使用的是全球顶级搜索引擎中三类有代表性的数据。
- KPI Anomalies:KPI 时间序列数据还可以在不同的严重程度上呈现出几种意外的模式(例如,抖动、缓慢的上升、突然的上升和下降),例如突然下降20%或50%。
- 搜索引擎一周内三种主要的 KPI 对应图像:

- 不同KPI除了物理意义不同,它们的特征也不一样的。搜索引擎中三种类型KPI的特征表
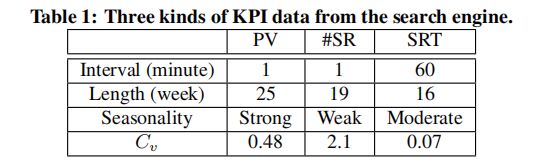
5.2.2 Problem and Goal
- 异常检测的基本目标是准确,识别出更多真实异常(ground truth),减少错误异常。
- 该论文使用 recall 和 precision 作为算法 Opprentice 的评测指标。
- 因为跟异常相关的数据很少,所以对那些检测器来说达到高 recall 和 高precision 是很难的事情。
- Opprentice 的一个质量目标:具有足够的自动化,因此操作人员不会参与选择和组合合适的探测器,或调整它们。
5.3 OPPRENTICE OVERVIEW
5.3.1 核心思想
- Opprentice 使用的是有监督学习;有监督学习现在比较流行。
- 在Oppertice中应用机器学习的高级理念,如图所示:

- 首先,操作员需要标记数据中的异常。
- 利用现有的基本异常检测器分别从多个角度量化数据的异常水平。
- 探测器的结果作为数据的特征,与操作员的标记构成训练集,然后利用机器学习算法建立分类模型。比如图2中的判定边界,由问号表示的点被称为异常。
- 优点如下:
- 节省操作员的时间。操作员只需要标记异常数据即可;
- Opprentice 是首个使用机器学习算法来提取特征的框架;而其他那些用于异常检测的机器学习算法都只是用作基本的异常检测器。
5.3.2 机器学习的挑战
尽管上述基于机器学习的思想似乎很有前途,但将其应用于机会设计却带来了许多内在的和实际的挑战。
- 标签开销(Labeling overhead) 我们开发了一个简单且方便的交互式界面作为打标签的工具,减少操作员的时间开销。
- 不完全异常案例(Incomplete anomaly) 训练集是否包含足够的异常情况会影响机器学习算法的性能。然而,由于异常在实际中发生的频率较低,任意的训练集不太可能覆盖足够的异常。例如,未来可能会出现新的异常类型。为了解决这个问题,我们使用新标记的数据 递增地重新训练分类器 。通过这种方式,Opprentice能够捕捉并学习初始训练集中没有出现的新类型异常。
- 样本类别不均衡(Class imbalance problem) 因为异常数据只占极少数样本,所以分类器可能更加趋向于把测试数据归类为正常数据。我们通过 调整机器学习分类器的阈值 来解决这个问题(从今以后把这个阈值叫做
cThld,后面将经常提到这个cThld)。 - 无关特征与冗余特征(Irrelevant and redundant features) 为了节省人工操作时间,我们既没有选择合适的检测器,也不调整其内部参数,而是使用具有不同参数的检测器提取特征。所以提取的特征中可能无关,也可能冗余,这可能会降低算法的精度。我们使用 集成学习算法来解决这个问题。
5.4 DESIGN
5.4.1 体系结构
Opprentice 的体系结构如下图所示。
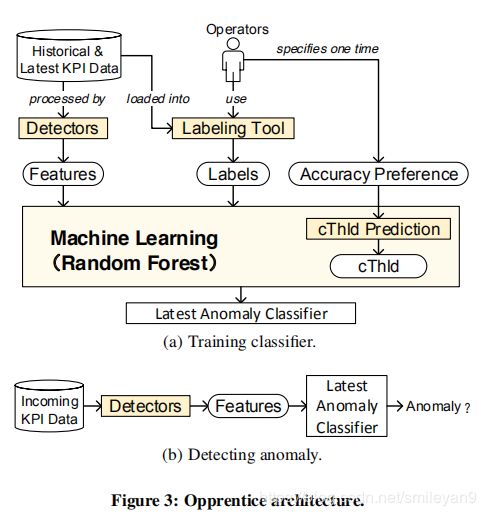
从操作者的角度来看,操作者通过两种方式与 Opprentice 进行互动(如下图中a部分)。
- 首先,操作员根据需要指定一个特定的精准度目标(偏好) (specify an accuracy preference),recall >= x, precision >= y. 我们假设指定的 x 与 y 不会改变。这个目标(preference) 将会用于指导
cThld(阈值) 的自动调整。 - 其次,操作员需要使用一个便捷的工具对最开始的历史数据中的异常进行标记,并且以后定周期进行标记(比如每周一次)。所有的数据只被标记一次。
从Opprentice 的角度来看
- 首先以如下方式训练出一个分类器:应用很多的检测器作为特征提取器,从原始数据中提取出多个特征,再加上操作人员的标签,可以用于某种机器学习算法(如本文中的随机森林),进行递增地对异常分类器进行训练。
- 其后,如上图(图3) b Detecting anomaly ,相同的检测器集合提取输入数据的特征,并且使用分类器对它们进行异常的检测与分类。注意,这里与以往的不同,这里的提取器只提取特征,而不检测异常。
接下来,我们将详细介绍每一组的设计。
5.4.2 标签工具(Labeling Tool)
我们开发了专门的工具,帮助操作者给异常打标签。

-
首先,加载KPI数据并以图像的形式展示出来,如图4所示。为了帮助操作人员识别异常,前一天的数据以及上一周的数据都会以浅色展示出来。
-
操作人员使用方向键 (arrow keys) 来浏览数据,比如放大区间,缩小区间,左移右移等等,使用鼠标左键标记异常,鼠标右键取消标记。请查看图4便可理解。
这里的标记与取消标记的对象(也就是图像中加深颜色的部分),可以理解为“目前浏览的窗口",也就是论文中的 window,这里记录一下,是因为后面的同样来自清华大学的异常检测方面的论文中,基于滑动窗口异常检测的想法,从本质上来讲极有可能跟这个手动地选择window有一定的联系。
使用这个工具进行打标工作效率很高,操作人员不需要逐个时间段进行标记,只需要标记出现异常的部分。首先他们看到的KPI曲线是一个相当放大的视图,在这个视图中,KPI曲线是不平滑曲线,所以异常部分对于操作人员来说是可见的。然后操作人员可以放大视图,定位异常出现的时间段,并通过窗口进行打标。在我们研究的KPI中,操作员只需要几分钟就能标记一个月的数据。
标记的一个问题是可能会引入误差,特别是在标记时,异常窗口的边界经常被扩大或缩小。然而,机器学习以其对噪声的鲁棒性而闻名。我们在第5条中的评估也证明了操作员的真实标签是可行的。
标记工具类似于WebClass,但是它只支持NetFlow数据,而不支持一般的时间序列数据。更重要的是,它只允许操作员将检测器已经识别的异常标记为假阳性或未知。相比之下,我们的标记工具使操作员能够自由标记所有数据,而不是标记检测结果。
5.4.3 检测器 (Detector)
我们接下来描述的内容如下:
- 异常的检测器如何用作异常特征的提取器;
- 如何选择检测器与 Opprentice 一起使用。
1)检测器用作提取器
我们使用统一的模式代表不同的检测器:
d
a
t
a
p
o
i
n
t
a
d
e
t
e
c
t
o
r
w
i
t
h
p
a
r
a
m
e
t
e
r
s
→
s
e
v
e
r
i
t
y
s
T
h
l
d
→
{
1
,
0
}
data\ point \ \ \underrightarrow{a\ detector\ with\ parameters} \ \ severity \ \ \underrightarrow{sThld} \ \ \{1,0\}
data point α、
β
\beta
β、
γ
\gamma
γ,而历史平均值有一个窗口长度参数。输入数据点的 severity 取决于检测器以及其内部参数。 检测器还需要阈值来将严重性转换成二进制输出(即有无异常),我们将此阈值称为 severity 阈值,简称 sThld。
因为 severity 描述了数据的异常程度,所以把 severity 当成异常检测的特征是正常的,为了产生特征,对于每个参数化检测器,我们对它们的参数进行采样,这样就可以得到几个固定的检测器。我们称这些具有特定采样参数的检测器为检测器配置。因此,这样的配置可以充当特征提取器。
d
a
t
a
p
o
i
n
t
c
o
n
f
i
g
u
r
a
t
i
o
n
(
d
e
t
e
c
t
o
r
+
s
a
m
p
l
e
d
p
a
r
a
m
e
t
e
r
s
)
→
f
e
a
t
u
r
e
data\ point \ \ \underrightarrow{configuration \ (detector + sampled\ parameters)} \ \ feature
data point α ∈[0,1]。当
α
\alpha
α 增大时,预测将会更加依赖于最近的数据而不是更久以前的历史数据。
因此,我们可以从
α
∈
0.1
,
0.3
,
0.5
,
0.7
,
0.9
\alpha \ \in {0.1, 0.3, 0.5, 0.7, 0.9}
α ∈0.1,0.3,0.5,0.7,0.9 中进行取样,从EWMA中或者五种典型的特征。
对于那些有多个参数和很大的参数区间的检测器,我们可以减小取样粒度。比如说,Holt-Winters 有三个 [0,1] 区间中的参数
α
,
β
,
γ
\alpha,\beta,\gamma
α,β,γ。我们为了限制取样的数目,我们可以对它们选择 {0.5,0.4,0.6,0.8} 几种数值,可以得到
4
3
=
64
4^3 = 64
43=64 个特征。其他类型的检测器可能需要窗口参数(window parameters),我们可以根据检测器的特点采用几个时间点、几天或者几周的窗口。例如,基于短窗口移动平均的检测器旨在识别局部异常,而时间序列分解通常使用一个周的窗口来捕获长期的异常行为(violations)。 虽然由于采样粒度相对较粗,这种采样策略不能保证我们能够找到最合适的参数(或特征),但我们只需要一组足够好的特征,而opprintice通过将它们结合起来就可以获得很好的精度。
5.4.4 机器学习
1)思考和选择
选择机器学习算法的时候要特别小心,因为在我们的问题中,存在冗余和不相关的特征,这是由于使用检测器时没有仔细评估而造成的。在一些机器学习算法中,如朴素贝叶斯、logistic回归、决策树和线性支持向量机,在处理这些训练数据时会表现得很差。另外,一个有前途的算法应该是参数较少且对其参数不敏感的,这样就可以很容易地应用于不同的数据集。本论文中采用的是随机森冷算法,它可以很好地处理噪音特征,在实际操作中效果很好。而且, 随机森林只有两个参数,并且算法效果对这两个参数不敏感。评估结果也展示随机森林算法效果更好,更加稳定。
请注意,我们确实了解特征选择是一种常用的解决方案,用于减轻不相关和冗余特征的影响。然而,本文并没有对特征选择进行深入的研究,而是将其作为未来的工作,因为它可能会带来额外的计算开销,而且随机森林本身也能很好地工作。
2)随机森林
预备工作 (preliminaries):决策树
略
随机森林(random forest):
一个随机森林是一个使用了很多个决策树的集成分类器。它的主要思想是,一群弱学习者(例如,个体决策树)可以集成为一个强学习者。为了建立不同的树,一个随机的森林增加了一些元素或随机性。首先,对每棵树进行原始训练集的子集训练。其次,树不是在每一级评估所有特征,而是每次只考虑特征的随机子集。因此,如果树不使用这些特征,一些树可能不受或更少地受到不相关和冗余特征的影响。所有的树都是这样建立的,没有修剪。然后,随机森林以多数票将这些树合并。也就是说,给定一个新的数据点,每个树都给出自己的分类。例如,如果100棵树中有40棵树将该点分类为异常,则其异常概率为40%。默认情况下,随机林使用50%作为分类阈值(即cThld)。
上述的随机性和集成特性使得随机森林比决策树对噪声更具鲁棒性,在面对无关和冗余特征时表现更好。
5.4.5 配置分类阈值(Configuring cThld)
1) PC-Score: 选择合适 cThld 的指标
我们需要配置 cThld 而不是使用默认数值(比如0.5),有两个原因:
- 数据集分类不均的问题(异常点可能是极少数)
- 操作人员可以根据自己的偏好来配置异常检测的精度和召回率。配置cThld 是一种 在精确性和召回率进行权衡的通用方法。
因此,我们应该适当地配置随机森林的 cThld,以满足操作人员的偏好。

在描述如何配置cThld之前,我们首先使用 PR (Precision Recall) 曲线图来提供一些直观信息。PR曲线被广泛用于评估二值分类器的准确性,尤其是在数据不平衡的情况下。通常,精确性和召回之间存在权衡。如上图所示(图6),根据PV数据训练和测试的随机森林导出的示例 PR 曲线。两种假定的操作者 偏好(1) “recall ≥ 0.75 and precision ≥ 0.6”和 偏好(2) “recall ≥ 0.5 and precision ≥ 0.9” 阴影矩形表示。cThlds 的配置即在PR曲线上寻找一个合适的点。在图6中,三角形符号由默认的 cThld = 0.5选择。
此外,我们还展示了另外两个精确度量的结果:
- F-score
- SD(1,1) 它选择到右上角的欧几里德距离最短的点,在这里精度和召回都是完美的。
我们在图6中看到,PR曲线在两个矩形内都有点,但是默认阈值只满足 偏好(2),而不满足 偏好(1);F-score 和 SD(1,1) 两种偏好都不能满足。这是因为这些指标选择cThld时没有考虑操作员的偏好。
基于上述事实,我们提出了一种简单而有效的基于 F-score 的准确度度量方法,即PC-score(preference centric Score),以明确考虑操操作人员的偏好。
首先,对于p r曲线上的每个点(r,p),我们计算其 PC-score 如下:
f
(
n
)
=
{
2
∗
r
∗
p
r
+
p
+
1
,
r
≥
R
a
n
d
p
≥
P
2
∗
r
∗
p
r
+
p
,
o
t
h
e
r
w
i
s
e
f(n)=
f(n)={r+p2∗r∗p+1,r+p2∗r∗p,r≥R and p≥Potherwise
其中的R和P是来自于操作人员的偏好 "recall
≥
R
\geq R
≥R and precision
≥
P
\geq P
≥P"。PC-score 基本上是用来衡量 (r,p) 的F-score。为了找到满足操作人员偏好的点(如果存在的话),当
r
≥
R
a
n
d
p
≥
P
r \geq R\ and\ p \geq P
r≥R and p≥P 时,我们给 F-score 计算公式加1,作为激励常数(an incentive constant)。由于 F-score 不超过1,这个激励常数确保满足偏好的分数必须比不满足偏好的分数具有更大的PC分数。因此,我们选择与 PC-score 最大的点对应的 cThld 参数。在图6中,我们看到基于 PC-score 选择的两个点分别位于两个阴影接收角内。请注意,在PR曲线在偏好区域内没有点的情况下,PC-score 无法找到所需的点,但它仍然可以选择近似的召回率和精确度。
2)基于EWMA的 cThld 预测
EWMA 在4.3.3 介绍过 (Exponentially Weighted Moving Average),一个基于预测的检测器
上面描述了如何在离线或“oracle”模式下根据PC-score 配置cThld。也就是说,我们在要检测的数据(也称为测试集)已经到达之后配置 cThld 。这些 cThld 是我们可以配置用于检测这些数据的最佳cThld,称为 best cThld 。然而,对于在线检测,我们需要预测 cThld 来检测未来的数据。
为此,另一种方法是 k-fold 交叉验证。首先,将历史训练集划分为相同长度的k个子集。在每个测试(总共k个测试)中,使用子集中的k-1训练分类器,并使用cThld候选者对其余的分类器进行测试。在k个测试中获得最小平均PC分数的候选用于将来的检测。在本文中,我们使用k=5,并以0.001的非常细的粒度扫描cThld的空间,即我们在[0,1]的范围内评估1000个cThld候选。
然而,我们发现这种交叉验证方法在我们的问题中并不十分有效(参加5.6)。一个可能的解释是,如图7所示,最佳 cThld 在数周内可能有很大的差异。因此,在交叉验证中,在所有历史数据上获得最高平均性能的 cThld 可能与未来一周的最佳 cThld 差别很大。

我们的方法是由图7中的另一个观察结果驱动的。也就是说,尽管最好的cthld会在几周内发生变化,但它们可能更类似于相邻几周的 cThld。一种可能的解释是,导致KPI异常的潜在问题可能会在它们真正修复之前持续一段时间,因此相邻的几周更有可能出现类似的异常,并需要类似的 cThld。因此,我们基于历史数据中最好的cThld,采用 cThld 来预测 第 i 周(或者第 i 个测试集)的 cThld。
特别的是,EWMA 通过以下方式工作:
c
T
h
l
d
i
p
=
{
α
∗
c
T
h
l
d
i
−
1
b
+
(
1
−
α
)
∗
c
T
h
l
d
i
−
1
p
,
i
>
1
5
f
o
l
d
p
r
e
d
i
c
t
i
o
n
,
i
=
1
cThld^p_i =
cThldip={α∗cThldi−1b+(1−α)∗cThldi−1p,5 fold prediction,i>1i=1
其中
c
T
h
l
d
i
−
1
p
cThld^p_{i-1}
cThldi−1p 是第 i-1 周最好的 cThld。
c
T
h
l
d
i
p
cThld^p_i
cThldip 是第 i 周预测的 cThld,也是第 i 周用于检测时用到的参数。
α
∈
[
0
,
1
]
\alpha \in [0,1]
α∈[0,1] 是平滑常数。第一周时,我们采用 5-fold 交叉验证的方法来初始化
c
T
h
l
d
1
p
cThld^p_1
cThld1p 。EWMA 简单但是在这里非常有效,因为它不需要大量的历史数据来启动。随着
α
\alpha
α 的增大, EWMA 更加容易得出最近最优 cThld,它在预测中有更大的影响。本论文中采用
α
=
0.8
\alpha=0.8
α=0.8 来快速捕捉 cThld 值。实验结果表明:基于cThld的EWMA 预测方法 比 5-fold交叉验证有更好的预测效果。
5.5 EVALUATION
我们使用Python、R和C++代码9500行来实现Opple和14个检测器。机器学习块基于scikit学习库。在本节中,我们使用来自顶级全球搜索引擎的三种KPI数据来评估Oppertice。这些数据由操作员使用我们的标记工具标记。
图8示出了评估流程。在前四个步骤中,我们用不同的方法比较了机会的各个组成部分的准确性。Opprentice 的准确性见第5.6节。除了准确性之外,Oppertice 的质量目标,即自动化,也通过直接将oppertice应用到三个不同的kpi,而无需调整来评估。唯一的手动操作是标记KPI数据。我们还询问了操作人员之前的检测器调整时间,并将其与标记时间(见5.7)进行了比较。最后,我们评估了 Oppertice 的在线检测和离线训练时间(见5.8)。接下来,我们首先描述第5.1节中的数据集和第5.2节中选择的检测器,然后展示评估结果。

5.5.1 数据集
我们从一个大型搜索引擎(见2.1)中收集了三种具有代表性的 KPI 数据(即PV、#SR和SRT)。这些数据由搜索引擎的操作员使用我们的标记工具标记。分别有7.8%、2.8%和7.4%的数据点被标记为PV、SR和SRT异常。虽然我们使用的数据来自搜索引擎,但它们并不仅仅是搜索引擎的特例。例如,根据以前的文献和我们的经验,我们使用的PV数据在视觉上与其他类型的体积数据相似。例如,其他基于Web的服务的PV、RTT(往返时间)和ISP的总流量以及在线购物收入。因此,我们相信这三种 KPI 足以评估机会的想法,我们认为,作为我们未来的工作,我们将使用来自搜索之外的其他领域的数据进行更广泛的评估。表2显示了从标记的数据集生成训练集和测试集的几种方法。

5.5.2 检测器与参数选择
根据探测器要求(见4.3.2),在这个概念验证原型中,我们使用14个广泛使用的探测器评估Opprentice(表3)

在本研究之前,我们研究的搜索引擎已经使用了其中的两个检测器。一种是Diff,它简单地利用当前点与最后一个时隙点、最后一天点和上周点之间的差异来测量异常严重性。另一种方法,即“差分平均法”,利用当前点与最后一个时隙点之差的移动平均值来测量严重性。这个检测器是用来发现连续的抖动。其他12个探测器来自于以前的文献。在这些检测器中,有两种不同的检测器使用中间值周围的MAD(中间值绝对偏差)而不是平均值周围的标准偏差来测量异常严重性。该补丁可以提高对缺失数据和异常值的鲁棒性。为了空间的利益,这些探测器的细节和它们产生严重性的方式没有进一步介绍,但是可以在表3的参考文献中找到。各探测器采样参数见表3。在这里,ARIMA的参数是根据数据估计的。对于其他探测器,我们扫描它们的参数空间。
总共,我们有14个探测器和133个配置,或133个随机森林特征。请注意,Opprentice不仅限于我们使用的探测器,而且可以包含新兴探测器,只要它们满足我们在第4.3.2节中的探测器要求。
5.5.3 随机森林的精度
现在我们展示评估结果。首先,我们比较了在离线模式下随机森林和其他检测方法的准确性。因为我们不知道其他方法的阈值,所以我们无法公平地比较特定的召回和精确性。或者,我们使用PR曲线下的面积(AUCPR)作为精度度量。AUCPR是在所有可能的阈值上检测性能的单个数字摘要。AUCPR范围从0到1。直观地说,AUCPR较大的检测方法更有可能获得较高的查全率和查准率。
随机森林 vs 基本检测器和基本探测器的静态组合
首先,在图9中,我们将随机森林与表中具有不同参数设置(133个配置)的14个基本检测器进行比较。三。我们还将随机森林与两种静态组合方法进行了比较:标准化模式[21]和多数投票[8]。这两种方法被设计用来组合不同的检测器,但不管它们的精度如何,它们都是同等对待的。为了便于比较,在本文中,我们还使用这两种方法将133个配置组合为随机林。以上方法都是从第9周开始检测数据。前8周作为随机森林的初始训练集。


在图9的左侧,我们看到对于AUCPR,随机林在图9(a)和图9(b)中排名第一,在图9(c)中排名第二,其中随机林的AUCPR仅比最高的低0.01。另一方面,两种静态组合方法的AUCPR始终排名较低。这是因为大多数配置是不准确的(在图9中AUCPR很低),因为我们没有手动选择合适的检测器或调整它们的参数。然而,这两种静态组合方法处理具有相同优先级的所有配置(例如,同等权重的投票)。因此,它们可能会受到不准确配置的严重影响。
图9的右侧显示了随机森林的PR曲线、两种组合方法和前3个最高AUCPR基本检测器。我们观察到,每个KPI的最佳基本检测器是不同的,这表明操作员对每个KPI的不同类型的异常感兴趣。表4显示了当这些方法的召回满足操作者的偏好时(召回≥0.66)的最大精确度。我们发现,对于所有的kpi,随机森林达到了很高的精度(大于0.8)。结果表明,随机森林的性能明显优于两种静态组合方法,并且对每个KPI的性能与最精确的基本检测器相似,甚至优于最精确的基本检测器。
随机森林 vs 其他算法
我们还比较了随机森林和其他几种机器学习算法:决策树、logistic回归、线性支持向量机(SVMs)和朴素贝叶斯。所有这些算法都在 表2 中的 I1 上进行了训练和测试。为了说明不相关特征(例如,图9中具有低AUCPR的配置)和冗余特征(例如,具有相似参数设置的检测器)的影响,我们通过第一次使用一个特征并每次添加一个以上特征来训练这些学习算法。这些特征是按照它们的相互信息的顺序添加的,这是特征选择的一个公共度量。在图10中,我们观察到,虽然其他学习算法的AUCPR是不稳定的,并且随着更多特征的使用而降低,但是即使使用了所有133个特征,随机森林的AUCPR仍然很高。结果表明,在实际应用中,随机森林对不相关和冗余特征具有很强的鲁棒性。

5.5.4 增量训练 (Incremental Retraining)
在演示了随机森林的准确性和稳定性之后,我们想展示不同训练集的效果。在本次评估和以下评估步骤中,我们将只关注随机森林。我们比较了表2中生成训练集的三种方法:I4、F4和R4。图11示出了不同训练集上随机森林的AUCPR。我们发现,在大多数情况下,I4(也称为增量再训练)比其他两个训练集表现更好。这个结果与前面提到的挑战一致,即任意数据集不太可能包含足够种类的异常。在图11(b)中,我们看到三个训练集产生相似的AUCPR。这意味着#SR的异常类型相对简单,变化不大,因此可以很好地被这些训练集捕获。总的来说,由于标记异常不需要花费太多时间(见5.7),我们认为增量再训练是生成训练集的更通用和准确的方法。

5.5.5 PC-Score vs 其他精度指标

到目前为止,我们已经展示了没有特定 cThld 的随机森林的离线AUCPR。接下来,我们评估用于配置 cThld 的不同精度度量。我们将提出的PC评分与默认的cThld、F-score 和SD(1,1)进行比较。具体来说,我们在 表2 中的 I1 上训练和测试随机林,并让这四个度量确定每个一周测试集的 cThld 。然后,我们使用每周的回忆和精确性来衡量他们的表现。请注意,此评估考虑脱机或oracle设置,我们假设在配置 cThld 时有测试集。我们将在5.6节中展示未来测试集(在线检测)的 cThld 预测。
图12分别示出了三种 KPI 的四个度量的结果。在左边的热图中,每个点代表一周的召回率(recall) 和精确性(precision)。第一行显示偏好下的结果(recall≥0.66,precision≥0.66),称为中度偏好。我们还评估了另外两种偏好:第二行对精确性敏感(recall≥0.6和precision≥0.8),第三行对召回率敏感(recall ≥ 0.8和 precision ≥ 0.6)。首选项由热图右上角的框表示。如果我们使用原始或降低的首选项(例如,向上缩放框),右侧的折线图将显示框内的点的百分比(满足首选项)。
通过对热图的分析,我们发现,当其他三个指标所得到的分数在不同偏好下保持不变时,PC-score 具有根据不同偏好调整查全率和查准率的能力。由于这一优势,我们在折线图中看到,无论是最初的偏好还是放大的偏好,PC-score 总是在框内获得最多的分数。
我们还注意到,要满足所有周的偏好并不容易,因为异常在某些周非常罕见。例如,我们发现在没有点满足中等偏好的周,PV和SR的异常分别比其他周少73%和78%。因此,不可避免地会产生更多的误报,以识别这些少数异常,从而导致低精度。此外,仅仅遗漏一些异常可能会导致召回率明显下降。幸运的是,由于这几周异常很少,相对较低的准确率或召回率不会导致大量的假阳性(false positive)或假阴性(false negative)。例如,如果有10个异常数据点,而我们识别了其中的4个(40%的召回率),我们将只漏掉6个异常数据点;在这种情况下,如果我们有40%的精度,我们将只识别6个误报。与我们一起工作的操作员表示,他们实际上可以处理少量的误报或漏报。
5.5.6 cThld 预测中,EWMA vs 5-fold
在此之前,我们展示了对cThld配置的不同度量的离线评估,发现PC得分优于其他三个。现在,我们评估了基于PC评分的在线cThld预测的性能,这也是Oppertice整体的检测精度。我们将 oppertice 使用的基于EWMA的方法与5倍交叉验证进行了比较。评估与第5.5节相似,但 cThld 预测仅使用历史数据(训练集)而非未来数据(测试集)。如前所述,由于异常在某些周内相当罕见,因此每周的结果可能有很大差异。为了得到一个稳定的结果,我们计算了4周移动窗口的平均召回率和精确度。窗口为每个步骤移动一天,以便我们可以获得更细粒度的结果。在这里,我们给出了在操作者实际偏好下的结果(recall ≥ 0.66,precision ≥ 0.66)。图13示出了每个窗口的召回率和精确度。离线检测结果(这里称为最佳情况)作为基线。

结果表明,对于PV、SR和SRT,与5倍交叉验证相比,EWMA在阴影区域内分别多出40%、23%和110%的点。共有8403个(7.3%)、2544个(2.1%)和86个(6.4%)数据点分别在三个关键绩效指标的测试集中(第9周后)被Oppertice识别为异常(未显示)。我们注意到有一些点落在阴影区域之外,例如图13(a)中58到70之间的窗口。这主要是因为那几周的异常非常罕见。 例如,在58到70之间的窗口中,平均只有4%的光伏数据的地面真值异常点。然而,如第5.5节所述,在这种情况下,稍低的精确度或召回率不会对操作者产生许多误报或漏报。总之,Oppertice 可以自动满足或近似于操作员的精度偏好。
5.5.7 打标时间 vs 调谐时间(Labeling Time vs. Tuning Time)
接下来,我们将展示标签的时间成本,这是操作员使用 Oppertice 时所需的唯一手动工作。图14显示了操作员使用我们的工具(4.2节)标记三种类型的 KPI 数据时的标记时间。结果表明,一个月数据的标记时间基本上随该月异常窗口数的增加而增加。异常窗口是指由一个标记动作产生的连续异常窗口。在这三个 KPI 中,SRT 每个月的数据标记时间较少,因为它的数据间隔是60分钟,因此一个月的数据点较少。总体而言,一个月数据的标注时间小于6分钟。PV、#SR和SRT的总标记时间分别为16、17和6分钟。标记开销低的一个直观原因是,操作员每次都标记一个异常窗口,而不是逐个标记单个异常数据点。异常窗口可以比数据中的异常点小得多(图14)

为了说明Oppertice如何帮助减少操作员的手动操作,我们还提供了一些操作员调整探测器时间的事件示例,包括他们学习探测器和了解其参数的时间。我们采访了三位来自搜索引擎的操作人员,他们都有过调试检测器的经验。第一个操作员使用 SVD,他说他花了大约8天时间调试探测器;第二个操作员使用 Holt-Winters 和 Historical Average,他花了大约12天时间调试这两个探测器;第三个操作员应用时间序列分解,他说在探测器实现之后,他还花了大约10天的时间来测试和调试探测器。在上述情况下,经过几天的调试,只有第一个操作员的检测器工作得比较好,而另外两个操作员对其检测器的精度仍然不满意,最后放弃了它们。我们在第5.3.1节中比较了 Oppertice 和这些基本探测器的准确性。
尽管上面报告的时间不是用于调整的确切时间,但它提供了手动调整检测器的开销和困难的基本概念。我们采访的运营商证实,探测器调谐非常耗时,他们对此既不感兴趣,也不感到舒适。总之,Opprentice 可以用快速方便的异常标记来代替耗时且枯燥的探测器调谐。
5.5.8 检测时延和训练时间(Detection Lag and Training Time)
检测时延原则上由特征提取时间和分类时间组成。我们使用Intel Xeon E5-2420 CPU和24GB内存在Dell PowerEdge R420 服务器上运行Oppertice。对于每个数据点,提取133个特征的总时间平均为0.15秒。分类所需时间很短,平均每个数据点不到0.0001秒。此外,每轮离线训练时间不到5分钟。由于所有的检测器都可以并行运行,随机林的训练也可以并行化,我们相信利用多线程技术和服务器集群上的分布式计算可以获得更好的性能。
5.6 DISSCUSSION
实际上,异常检测是复杂的。在这一部分中,我们讨论了异常检测的一些问题,并澄清了机会的范围。
- 异常检测,不排除故障(Anomaly detection, not troubleshooting):有时,尽管运营商承认 KPI 曲线中存在异常,但他们往往忽略这些异常,因为他们知道这些异常是由一些正常的活动(如服务升级和可预测的社会事件)引起的。然而,由于我们的研究重点是识别 KPI 数据的异常行为(本文称为异常检测),因此我们要求操作人员根据数据曲线本身来标记异常,而不考虑其背后的原因。异常检测是监控服务性能的第一个重要步骤。我们认为,检测结果应该报告给操作人员,让操作人员决定如何处理,或者更理想的是,输入到故障排除系统中,以分析根本原因并生成更可行的建议。例如,故障排除系统可能会发现异常是由于正常的系统升级引起的,并建议操作员忽略这些异常。然而,排除异常本身超出了我们的研究范围。
- 异常持续时间(Anomaly duration):持续异常的持续时间可能是发出警报的另一个重要考虑因素。在本文中,我们确实故意忽略了这个因素。一个原因是,这将使我们的模型过于复杂,无法显示核心思想。另一个是,基于我们检测到的点水平异常,实现持续时间滤波器相对容易。例如,如果操作员只对持续超过5分钟的连续异常感兴趣,可以通过简单的阈值过滤器来解决 。
- 跨相同类型的关键绩效指标进行检测(Detection across the same types of KPIs):一些KPI 属于同一类型,运营商通常关心它们的类似异常类型。例如,PV来自不同的 ISP。在这种情况下,运营商只需标注一个或几个关键绩效指标。然后,在这些标记数据上训练的分类器可用于检测相同类型的kpi。需要注意的是,为了对不同尺度的数据重用分类器,需要对基本检测器提取的异常特征进行规范化。我们计划在今后的工作中探索这个方向。
- 脏数据(Dirty data):一个众所周知的问题是,检测器经常受到“脏数据”的影响。脏数据是指数据中的异常或缺失点,它们会污染探测器,造成探测器的误差。我们用三种方法解决这个问题。
- a) 我们的一些检测器,例如加权MA和SVD,只能使用最近的数据生成异常特征。因此,它们可以快速消除脏数据的污染。
- b) 我们利用MAD[3,15]使一些检测器,如TSD,对脏数据更加健壮;
- c) 由于oppertice同时使用许多检测器,即使少数检测器受到污染,oppertice仍然可以自动选择和使用剩余的检测器。
- 学习限制(Learning limitations):基于监督学习的方法需要标记数据进行初始化。与直接应用基本检测器相比,这是额外的开销。幸运的是,现在的KPI数据很容易获得[1、4、9、12、14、17、26]。同时,标签也可以是有效的,成本较低的时间,正如我们之前所证明的,与标签工具。另一个问题是,基于学习的方法受到训练集中异常的限制。例如,异常可能很罕见,未来可能会出现新类型的异常。我们通过逐步地重新训练分类器来收集更多的异常案例和学习新出现的异常类型来解决这个问题。
- 检测精度(Detection accuracy):由于上述诸多实际挑战,异常检测是一项复杂而富有挑战性的任务。一直以来,要达到较高的准确率和召回率是很难的。我们也不能保证 Oppertice 能够始终满足运营商的精度偏好。但我们的评估表明,Oppertice 的准确性仍然是有希望的,特别是对于运营商在所研究的服务中的偏好。
5.7 RELATED WORK
在异常检测领域进行了大量的工作。研究人员使用不同的技术开发了许多探测器[1-24]。此外,研究人员试图解决探测器在实际应用中的几个挑战。
- a) 为了自动调整探测器的内部参数,Krishnamurthy等人。[11] 提出了一种多通道网格搜索方法,从数据中寻找合适的参数。Himura等人。[23]搜索参数以最大化检测到的事件的比率。相比之下,除了检测器内部参数外,我们还考虑了自动选择检测器及其阈值。
- b) 一些工作使用ROC曲线来评估不同检测器的性能,而不管它们的阈值是什么[9,14,26]。这项技术也用于我们的工作中。
- c) MAD用于提高检测器对脏数据的鲁棒性。我们还用MAD实现了两个检测器。
- d) 一些解决方案试图静态地将不同的探测器组合在一起[8,21]。我们和他们比较了机会。
- e) 机器学习也被应用于异常检测,但它是基本的检测器。相反,我们使用机器学习来组合不同的现有检测器。
异常检测的另一个重要挑战是获取地面真实性来评估探测器。三种常用的解决方案是:
- a) 使用域运算符识别或确认的真实异常[1、4、9、12、14、17、26];
- b) 通过将真实或预定义异常注入背景数据[9、14、18、19]来生成合成异常;
- c) 成对比较,将其他检测器报告的异常视为地面真理[1,8,10,17,18]。
因为我们的基本目标是满足运营商的需求,所以我们认为解决方案(a)在本文中更有意义。
5.8 CONCLUSION
将异常检测应用于基于 Internet 的服务在实践中具有挑战性。这是因为异常很难定量定义,现有的探测器在部署之前有参数和阈值需要调整。我们提出的框架 Oppertice 通过一种新的基于机器学习的方法来应对上述挑战。通过机器学习从真实数据和操作者的标签中获取不清晰的异常概念,同时通过机器学习可以自动组合大量现有的检测器来训练分类器来识别异常。我们对实际搜索kpi的评估表明,Oppertice 的性能始终与性能最好的基本检测器相似,甚至优于性能最好的基本检测器,后者可以针对不同的数据集进行更改。
据我们所知,Oppertice 是第一个将机器学习应用于获取实际异常概念、自动组合和调整各种已知检测器以满足操作员精度偏好的检测框架。新出现的检测器不必经过耗时且常常令人沮丧的参数调整,而是可以很容易地插入Oppertice,从而使前者更容易部署,后者更精确。此外,虽然机器学习是一个很有前途的解决方案,但在设计实际系统时需要小心,因为它会带来一些有趣的挑战,例如不平衡类和不相关的冗余特征。本文对其中的一些问题进行了探讨和解决。我们相信 Opperentice 提供了一种新的方案,以弥合实际操作需求与最先进异常检测器之间的差距。在我们未来的工作中,我们计划解决第6节中提到的几个问题,并将 Oppertice 的思想应用到其他网络操作任务中,如自动入侵检测和网络故障排除。
感谢您的 点赞、 收藏、评论 与 关注