深度学习armv8/armv9 cache的原理
快速链接:
.
个人博客笔记导读目录(全部)
- ARMv8/ARMv9架构精选系列–目录
- ARMV8/ARMV9/Trustzone/TEE安全课程
目录
-
-
-
- 1、为什么要用cache?
- 2、背景:架构的变化?
- 2、cache的层级关系 –--big.LITTLE架构(A53为例)
- 3、cache的层级关系 –-- DynamIQ架构(A76为例)
- 4、DSU / L3 cache
- 5、L1/L2/L3 cache都是多大呢
- 6、cache相关的术语介绍
- 7、cache的分配策略(alocation,write-through, write-back)
- 8、架构中内存的类型
- 9、架构中定义的cache的范围(inner, outer)
- 10、架构中内存的类型 (mair_elx寄存器)
- 11、cache的种类(VIVT,PIPT,VIPT)
- 12、Inclusive and exclusive caches
- 13、cache的查询过程(非官方,白话)
- 14、cache的组织形式(index, way, set)
- 15、cache line里都有什么
- 16、cache查询示例
- 17、cache查询原理
- 18、cache maintenance
- 19、软件中维护内存一致性 – invalid cache
- 20、软件中维护内存一致性 – flush cache
- 21、cache一致性指令介绍
- 22、PoC/PoU point介绍
- 23、cache一致性指令的总结
- 24、Kernel中使用cache一致性指令的示例
- 25、Linux Kernel Cache API
- 26、A76的cache介绍
- 27、A78的cache介绍
- 28、armv8/armv9中的cache相关的系统寄存器
- 29、多核之间的cache一致性
- 30、MESI/MOESI的介绍
-
-
1、为什么要用cache?
ARM 架构刚开始开发时,处理器的时钟速度和内存的访问速度大致相似。今天的处理器内核要复杂得多,并且时钟频率可以快几个数量级。然而,外部总线和存储设备的频率并没有达到同样的程度。可以实现可以与内核以相同速度运行的小片上 SRAM块,但与标准 DRAM 块相比,这种 RAM 非常昂贵,标准 DRAM 块的容量可能高出数千倍。在许多基于 ARM 处理器的系统中,访问外部存储器需要数十甚至数百个内核周期。
缓存是位于核心和主内存之间的小而快速的内存块。它在主内存中保存项目的副本。对高速缓冲存储器的访问比对主存储器的访问快得多。每当内核读取或写入特定地址时,它首先会在缓存中查找。如果它在高速缓存中找到地址,它就使用高速缓存中的数据,而不是执行对主存储器的访问。通过减少缓慢的外部存储器访问时间的影响,这显着提高了系统的潜在性能。通过避免驱动外部信号的需要,它还降低了系统的功耗

2、背景:架构的变化?

- DynamIQ是Arm公司2017年发表的新一代多核心微架构(microarchitecture)技术,正式名称为DynamIQ big.LITTLE(以下简称为DynamIQ),取代使用多年的big.LITTLE技术
- big.LITTLE技术将多核心处理器IP分为两个clusters,每个cluster最多4个核,两个cluster最多4+4=8核,而DynamIQ的一个cluster,最多支持8个核
- big.LITTLE大核和小核必须放在不同的cluster,例如4+4(4大核+4小核),DynamIQ的一个cluster中,可同时包含大核和小核,达到cluster内的异构(heterogeneous cluster),而且大核和小核可以随意排列组合,例如1+3、1+7等以前无法做到的弹性配置。
- big.LITTLE每个cluster只能用一种电压,也因此同一个cluster内的各核心CPU只有一种频率,DynamIQ内的每个CPU核心都可以有不同的电压和不同的频率
- big.LITTLE每个cluster内的CPU核,共享同一块L2 Cache,DynamIQ内的每个CPU核心,都有专属的L2 Cache,再共享同一块L3 Cache,L2 Cache和L3 Cache的容量大小都是可以选择的,各核专属L2 Cache可以从256KB~512KB,各核共享L3 Cahce可以从1MB~4MB。这样的设计大幅提升了跨核数据交换的速度。 L3 Cache是DynamIQ Shared Unit(DSU)的一部分

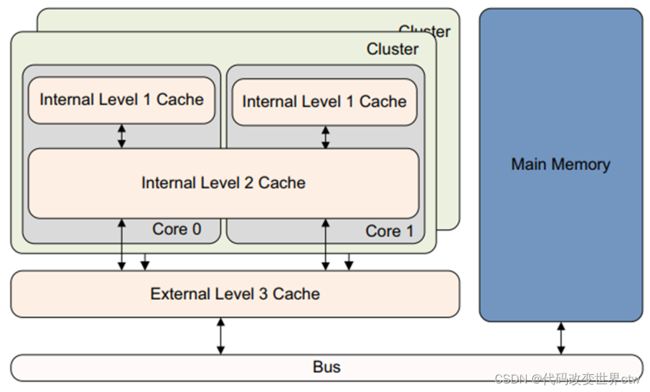
2、cache的层级关系 ––big.LITTLE架构(A53为例)

3、cache的层级关系 –-- DynamIQ架构(A76为例)
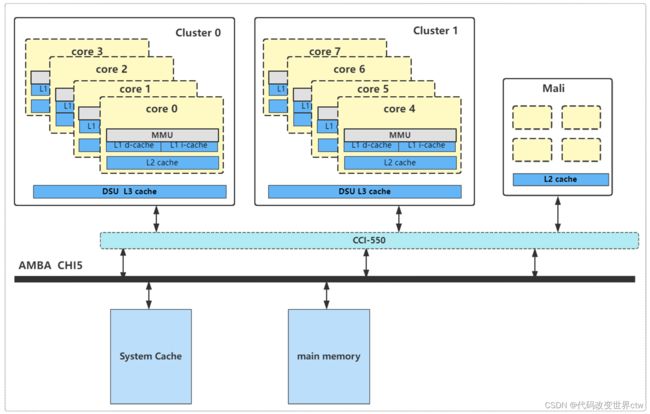
4、DSU / L3 cache
DSU-AE 实现了系统控制寄存器,这些寄存器对cluster中的所有core都是通用的。 可以从cluster中的任何core访问这些寄存器。 这些寄存器提供:
- 控制cluster的电源管理。
- L3 cache控制。
- CHI QoS 总线控制和scheme ID分配。
- 有关DSU‑AE 硬件配置的信息,包括指定的Split‑Lock 集群执行模式。
- L3 缓存命中和未命中计数信息
L3 cache
- cache size可选 : 512KB, 1MB, 1.5MB, 2MB, or 4MB. cache line = 64bytes
- 1.5MB的cache 12路组相连
- 512KB, 1MB, 2MB, and 4MB的caches 16路组相连
5、L1/L2/L3 cache都是多大呢
需要参考ARM文档,其实每一个core的cache大小都是固定的或可配置的。

6、cache相关的术语介绍
思考 :什么是Set、way、TAG 、index、cache line、entry?
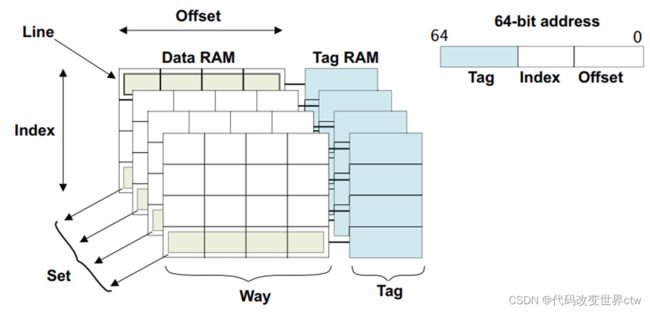
7、cache的分配策略(alocation,write-through, write-back)
-
读分配(read allocation)
当CPU读数据时,发生cache缺失,这种情况下都会分配一个cache line缓存从主存读取的数据。默认情况下,cache都支持读分配。 -
读分配(read allocation)写分配(write allocation)
当CPU写数据发生cache缺失时,才会考虑写分配策略。当我们不支持写分配的情况下,写指令只会更新主存数据,然后就结束了。当支持写分配的时候,我们首先从主存中加载数据到cache line中(相当于先做个读分配动作),然后会更新cache line中的数据。 -
写直通(write through)
当CPU执行store指令并在cache命中时,我们更新cache中的数据并且更新主存中的数据。cache和主存的数据始终保持一致。 -
读分配(read allocation)写回(write back)
当CPU执行store指令并在cache命中时,我们只更新cache中的数据。并且每个cache line中会有一个bit位记录数据是否被修改过,称之为dirty bit(翻翻前面的图片,cache line旁边有一个D就是dirty bit)。我们会将dirty bit置位。主存中的数据只会在cache line被替换或者显示的clean操作时更新。因此,主存中的数据可能是未修改的数据,而修改的数据躺在cache中。cache和主存的数据可能不一致

8、架构中内存的类型

9、架构中定义的cache的范围(inner, outer)
对于cacheable属性,inner和outer描述的是cache的定义或分类。比如把L1/L1看做是inner,把L3看做是outer
通常,内部集成的cache属于inner cache,外部总线AMBA上的cache属于outer cache。例如:
- 对于上述的big.LITTLE架构(A53为例)中,L1/L2属于inner cache,如果SOC上挂了L3的话,则其属于outer cache
- 对于上述的DynamIQ架构(A76为例)中,L1/L2/L3属于inner cache,如果SOC上挂了System cache(或其它名称)的话,则其属于outer cache
然后我们可以对每类cache进行单独是属性配置,例如:
- 配置 inner Non-cacheable 、配置 inner Write-Through Cacheable 、配置 inner Write-back Cacheable
- 配置 outer Non-cacheable 、配置 outer Write-Through Cacheable 、配置 outer Write-back Cacheable

对于shareable属性,inner和outer描述的是cache的范围。比如inner是指L1/L2范围内的cache,outer是指L1/L2/L3范围内的cache

以下再次对Inner/Outer属性做了一个小小的总结:

-
如果将block的内存属性配置成Non-cacheable,那么数据就不会被缓存到cache,那么所有observer看到的内存是一致的,也就说此时也相当于Outer Shareable。
其实官方文档,也有这一句的描述:
在B2.7.2章节 “Data accesses to memory locations are coherent for all observers in the system, and correspondingly are treated as being Outer Shareable” -
如果将block的内存属性配置成write-through cacheable 或 write-back cacheable,那么数据会被缓存cache中。write-through和write-back是缓存策略。
-
如果将block的内存属性配置成 non-shareable, 那么core0访问该内存时,数据缓存的到Core0的L1 d-cache 和 cluster0的L2 cache,不会缓存到其它cache中
-
如果将block的内存属性配置成 inner-shareable, 那么core0访问该内存时,数据只会缓存到core 0和core 1的L1 d-cache中, 也会缓存到clustor0的L2 cache,不会缓存到clustor1中的任何cache里。
-
如果将block的内存属性配置成 outer-shareable, 那么core0访问该内存时,数据会缓存到所有cache中
| Non-cacheable | write-through cacheable |
write-back cacheable |
|
|---|---|---|---|
| non-shareable | 数据不会缓存到cache (对于观察则而言,又相当于outer-shareable) |
Core0读取时,数据缓存的到Core0的L1 d-cache 和 cluster0的L2 cache, 如果core0和core1都读写过该内存,且在core0 core1的L1 d-cache中都缓存了该内存。那么core0在读取数据的时候,core0的L1 Dcache会更新,但core 1的L1 Dcache不会更新 | 同左侧 |
| inner-shareable | 数据不会缓存到cache (对于观察则而言,又相当于outer-shareable) |
Core0读取时,数据缓存的到Cluster0中所有cache | 同左侧 |
| outer-shareable | 数据不会缓存到cache (对于观察则而言,又相当于outer-shareable) |
Core0读取时,数据缓存的到所有cache | 同左侧 |
10、架构中内存的类型 (mair_elx寄存器)

11、cache的种类(VIVT,PIPT,VIPT)
MMU由TLB和Address Translation 组成:
- Translation Lookaside Buffer
- TAddress Translation

cache又分为;
- PIPT
- VIVT
- VIPT
![]()
12、Inclusive and exclusive caches

先讨论一个简单的内存读取,单核的. 如LDR X0, [X1], 假设X1指向main memory,且是cacheable.
(1)、Core先去L1 cache读取,hit了,直接返回数据给Core
(2)、Core先去L1 cache读取,miss了,然后会查询L2 cache,hit了,L2的cache数据会返回Core,还会导致这个cache line替换到L1中的某一行cache line
(3)、如果L1 L2都是miss,那么data将会从内存中读取,缓存到L1和L2,并返回给Core
接着我们再看一个复杂的系统,不考虑L3,多核的.
(1)、如果是inclusive cache,那么数据将会被同时缓存到L1和L2
(2)、如果是exclusive cache,那么数据只缓存到L1,不会缓存到L2
- Strictly inclusive: Any cache line present in an L1 cache will also be present in the L2
- Weakly inclusive: Cache line will be allocated in L1 and L2 on a miss, but can later be evicted from L2
- Fully exclusive: Any cache line present in an L1 cache will not be present in the L2
13、cache的查询过程(非官方,白话)

假设一个4路相连的cache,大小64KB, cache line = 64bytes,那么 1 way = 16KB,indexs = 16KB / 64bytes = 256 (注: 0x4000 = 16KB、0x40 = 64 bytes)
0x4000 – index 0
0x4040 – index 1
0x4080 – index 2
…
0x7fc0 – index 2550x8000 – index 0
0x8040 – index 1
0x8080 – index 2
…
0xbfc0 – index 255
14、cache的组织形式(index, way, set)

- 全相连
- 直接相连
- 4路组相连

例如 A76
-
L1 i-cache :64KB,4路256组相连,cache line为64bytes
-
TLB i-cache :全相连,支持4KB, 16KB, 64KB, 2MB,32M的页
-
L1 d-cache :64KB,4路256组相连,cache line位64bytes
-
TLB d-cache :全相连,支持4KB, 16KB, 64KB, 2MB,512MB的页
-
L2 cache :8路相连的cache,大小可选128KB, 256KB, or 512KB
15、cache line里都有什么

Each line in the cache includes:
• A tag value from the associated Physical Address.
• Valid bits to indicate whether the line exists in the cache, that is whether the tag is valid.
Valid bits can also be state bits for MESI state if the cache is coherent across multiple cores.
• Dirty data bits to indicate whether the data in the cache line is not coherent with external memory
• data
那么TAG里又都有什么呢??(S13 才会说这里的TAG等于物理地址里的TAG)
如下以A78为例,展示了TAG里都有什么

补充一点:TLB里都有什么? 同样以为A78为例;


16、cache查询示例

17、cache查询原理
先使用index去查询cache,然后再比较TAG,比较tag的时候还会检查valid标志位

18、cache maintenance

软件维护操作cache的指令有三类:
- Invalidation:其实就是修改valid bit,让cache无效,主要用于读
- Cleaning: 其实就是我们所说的flush cache,这里会将cache数据回写到内存,并清楚dirty标志
- Zero:将cache中的数据清0, 这里其实是我们所说的clean cache.
什么时候需要软件维护cache:
(1)、当有其它的Master改变的external memory,如DMA操作
(2)、MMU的enable或disable的整个区间的内存访问,如REE enable了mmu,TEE disable了mmu.
针对第(2)点,cache怎么和mmu扯上关系了呢?那是因为:
mmu的开启和关闭,影响了内存的permissions, cache policies
19、软件中维护内存一致性 – invalid cache

20、软件中维护内存一致性 – flush cache

21、cache一致性指令介绍
{, }

22、PoC/PoU point介绍
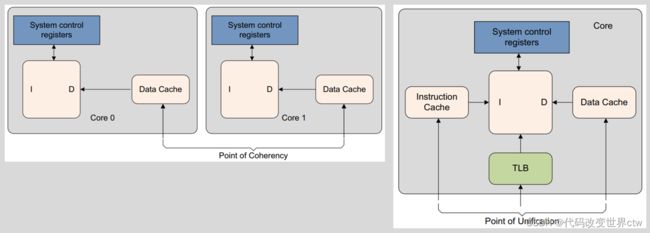
- PoC is the point at which all observers, for example, cores, DSPs, or DMA engines, that can access memory, are guaranteed to see the same copy of a memory location
- PoU for a core is the point at which the instruction and data caches and translation table walks of the core are guaranteed to see the same copy of a memory location
23、cache一致性指令的总结

24、Kernel中使用cache一致性指令的示例

25、Linux Kernel Cache API
linux/arch/arm64/mm/cache.S
linux/arch/arm64/include/asm/cacheflush.h
void __flush_icache_range(unsigned long start, unsigned long end);
int invalidate_icache_range(unsigned long start, unsigned long end);
void __flush_dcache_area(void *addr, size_t len);
void __inval_dcache_area(void *addr, size_t len);
void __clean_dcache_area_poc(void *addr, size_t len);
void __clean_dcache_area_pop(void *addr, size_t len);
void __clean_dcache_area_pou(void *addr, size_t len);
long __flush_cache_user_range(unsigned long start, unsigned long end);
void sync_icache_aliases(void *kaddr, unsigned long len);
void flush_icache_range(unsigned long start, unsigned long end)
void __flush_icache_all(void)
26、A76的cache介绍
A76
-
L1 i-cache :64KB,4路256组相连,cache line为64bytes
-
L1 d-cache :64KB,4路256组相连,cache line为64bytes
-
L2 cache :8路相连的cache,大小可选128KB, 256KB, or 512KB
-
L1 TLB i-cache :48 entries, 全相连,支持4KB, 16KB, 64KB, 2MB,32M的页
-
L1 TLB d-cache : 48 entries,全相连,支持4KB, 16KB, 64KB, 2MB,512MB的页
-
L2 TLB cache : 1280 entries, 5路组相连
-
L3 cache
cache size可选 : 512KB, 1MB, 1.5MB, 2MB, or 4MB. cache line = 64bytes
1.5MB的cache 12路组相连
512KB, 1MB, 2MB, and 4MB的caches 16路组相连

27、A78的cache介绍
A78
-
L1 i-cache :32或64KB,4路组相连,cache line为64bytes , VIPT
-
L1 d-cache : 32或64KB,4路组相连,cache line为64bytes, VIPT
-
L1 TLB i-cache :32 entries, 全相连,支持4KB, 16KB, 64KB, 2MB,32M的页
-
L1 TLB d-cache : 32 entries,全相连,支持4KB, 16KB, 64KB, 2MB,512MB的页
-
L2 TLB cache : 1024 entries, 4路组相连
-
L3 cache
cache size可选 : 512KB, 1MB, 1.5MB, 2MB, or 4MB. cache line = 64bytes
1.5MB的cache 12路组相连
512KB, 1MB, 2MB, and 4MB的caches 16路组相连

28、armv8/armv9中的cache相关的系统寄存器
ID Register

CTR_EL0, Cache Type Register

- IminLine, bits [3:0]
Log2 of the number of words in the smallest cache line of all the instruction caches that are controlled by the PE. - DminLine, bits [19:16]
Log2 of the number of words in the smallest cache line of all the data caches and unified caches that are controlled by the PE
29、多核之间的cache一致性
对于 Big.LITTLE架构
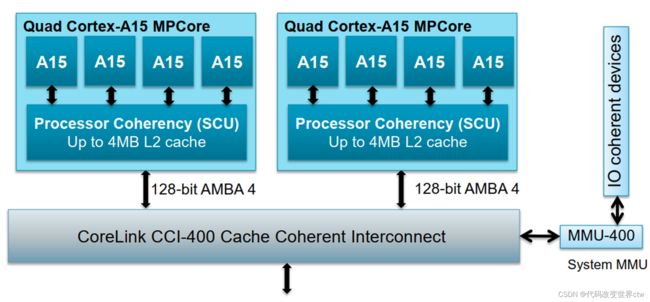
对于 DynamIQ架构

30、MESI/MOESI的介绍

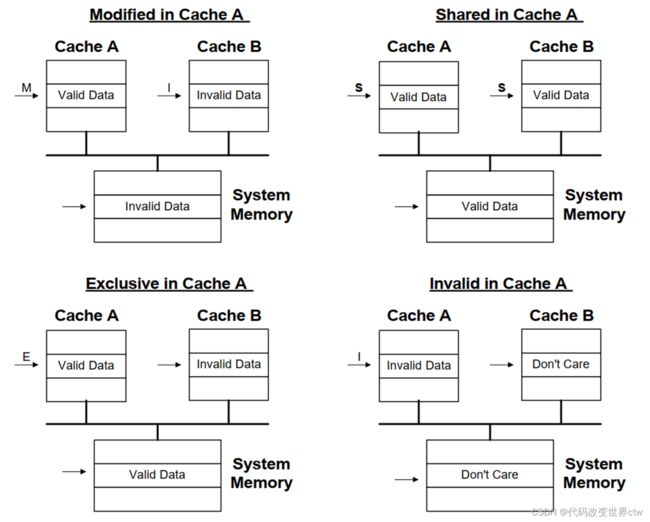

Events:
- RH = Read Hit
- RMS = Read miss, shared
- RME = Read miss, exclusive
- WH = Write hit
- WM = Write miss
- SHR = Snoop hit on read
- SHI = Snoop hit on invalidate
- LRU = LRU replacement
Bus Transactions:
- Push = Write cache line back to memory
- Invalidate = Broadcast invalidate
- Read = Read cache line from memory
