莫烦nlp——transformer(1)
视频链接:https://mofanpy.com/tutorials/machine-learning/nlp/intro-attention/
Transformer原理我看过几遍了,只是一直没用。多次注意力的思想是这次收获,以前只是明白它的结构。莫烦更多使用比喻介绍结构,没用公式或实际输入输出结构。
我做的李宏毅视频+博客的总结
语言多次注意力

使用了三次注意力,每次注意的时候都是基于上次注意后的理解。通过反复地回忆、琢磨才能研究透一句话背后的意思。所以,如果深刻理解是通过注意力产生的,那么肯定也不只使用了一次注意力。这种思路正是目前AI技术发展的方向之一,利用注意力产生理解,而且使用的也是多次注意力的转换。
RNN模型在通读语言后产生一个对句子全局的理解(句向量),然后再分别将全局理解和部分被注意的局部理解效应叠加,作为我后续任务的基础,比如基于全局和局部生成回复信息。但是这并不是我们刚刚提到的在注意力上再注意。
科研人员创造了另一种方法,他们说,根本没有什么全局理解,直接绕过RNN直接在词向量阶段就开始使用注意力,我们用一次一次的注意力产生的局部理解就能解决这个问题。不同层级的注意力带来的是不同层级上的理解。越是后面的注意,就是越深度的思考,这就是 Transformer 模型。
在理解一句话时
- 我们可以选择先读一遍,基于读过之后的理解上,再为后续处理分配不同的注意力
- 不通读,而是跳着读关键词,直接用注意力方法找出并运用这些关键词。
Transformer
Transformer 这种模型是一种 seq2seq 模型,是为了解决生成语言的问题。它也有一个 Encoder-Decoder 结构,只是它不像RNN中的 Encoder-Decoder。 之后我们将要介绍的 BERT 就是这个 Transformer 的Encoder部分,GPT就是它的 Decoder 部分,目前我们可以这样理解,后续我们会介绍他们之间的差别点。
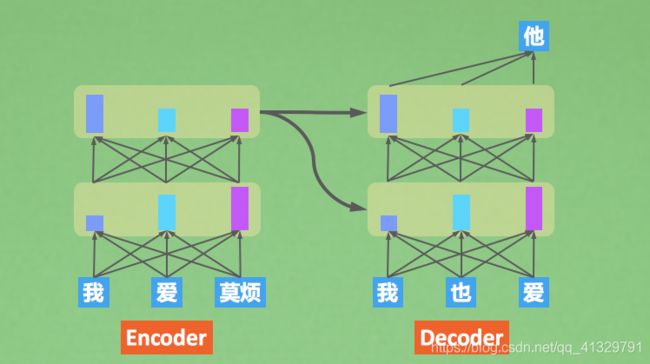
Encoder 负责仔细阅读,一遍一遍地阅读,每一遍阅读都是重新使用注意力关注到上次的理解,对上次的理解进行再一次转义。 Decoder 任务同Seq2Seq 的 decoder 任务一样,同时接收Encoder的理解和之前预测的结果信息,生成下一步的预测结果。
attention

它关注的有三种东西Query、Key、Value,这样做核心目的是快速准确地找到核心内容,换句话说:用我的搜索(Query)找到关键内容(Key),在关键内容上花时间花功夫(Value)。

我心中女神的样子就是Query,我拿着它(Query)去和所有的候选人(Key)做对比,得到一个要注意的程度(attention), 根据这个程度判断我要花多久时间仔细阅读候选人的材料(Value)。 这就是Transformer的注意力方式。
Multi-Head Attention
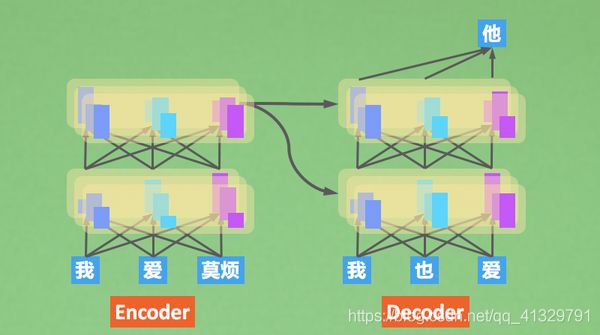
在同一层做注意力计算的时候,我多搞几次注意力。有点像我同时找了多个人帮我注意一下,这几个人帮我一轮一轮注意+理解之后, 我在汇总所有人的理解,统一判断。有点三个臭皮匠赛过诸葛亮的意思。
encoder-decoder连接
Self-attention的意识是Encoder只是自己和自己玩,自己捣鼓一句话的意思。
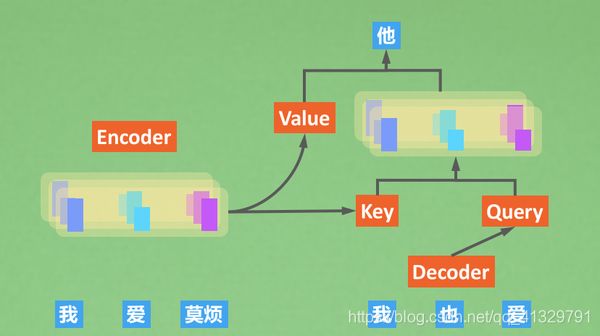
在Decoding时,decoder会向encoder借一下Key和Value,Decoder自己可以提供Query(已经预测出来的token)。使用我们刚刚提到的K,Q,V结合方式计算。 不过这张图里面还有些细节没有提到,比如 Decoder 先要经过Masked attention再和encoder的K,V结合,然后还有有一个feed forward计算,还要计算残差。
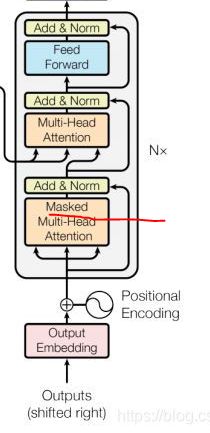
Masked attention: 不让decoder在训练的时候用后文的信息生成前文的信息。
decoder在第一层Masked Attention中用自己的Q、K、V,即自己和自己玩。
翻译时,我们使用真正的词作为decoder的输入,RNN是一个词接着一个词输入,然后预测,但Transform是同步进行的,它会同时处理整个句子,所以它不能使用后面的还没有预测出来的词。
position embedding
transformer的attention不像RNN,它没有捕捉到文字序列上的时序信息。那我们怎么让模型知道一句话的顺序呢? 这个有多种做法,比如让模型仔细学一个position embedding,或者你给一个有规律的position embedding就好了。
原始论文里描述了位置编码的公式(第3.5节),(李宏毅讲)左半部分的值由一个函数(使用正弦)生成,而右半部分由另一个函数(使用余弦)生成
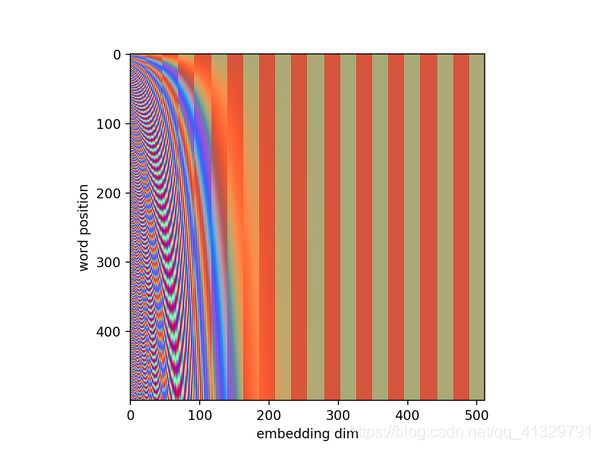
莫烦图
实战
结构简单地讲完了,有基础的同学才能联想到具体的数值操作。
通过代码发现:我一直忽略了预测的时候,decoder是没有label作为输入的,代码也没有inference
日期翻译的例子,任务:Decoder在生成语言的时候,也注意到Encoder的对应部分。
任务:
- 98年翻译成1998 ,而04年要翻译成2004,即区分20下半世纪与21上半世纪。
- 数字月份翻译成英文
- 年月日翻译成日月年
生成数据集
if __name__ == "__main__":
set_soft_gpu(False)
d = DateData(4000)
print("Chinese time order: yy/mm/dd ", d.date_cn[:3], "\nEnglish time order: dd/M/yyyy ", d.date_en[:3])
print("vocabularies: ", d.v2i)
print("x index sample: \n{}\n{}".format(d.idx2str(d.x[0]), d.x[0]),
"\ny index sample: \n{}\n{}".format(d.idx2str(d.y[0]), d.y[0]))
# 中文的 "年-月-日" -> "day/month/year"
"98-02-26" -> "26/Feb/1998"
Chinese time order: yy/mm/dd ['31-04-26', '04-07-18', '33-06-06']
English time order: dd/M/yyyy ['26/Apr/2031', '18/Jul/2004', '06/Jun/2033']
vocabularies: {'-': 1, '/': 2, '0': 3, '1': 4, '2': 5, '3': 6, '4': 7, '5': 8, '6': 9,
'7': 10, '8': 11, '9': 12, '': 13, '': 14, 'Apr': 15, 'Aug': 16,
'Dec': 17, 'Feb': 18, 'Jan': 19, 'Jul': 20, 'Jun': 21, 'Mar': 22, 'May': 23,
'Nov': 24, 'Oct': 25, 'Sep': 26, '': 0}
x index sample:
31-04-26
[6 4 1 3 7 1 5 9]
y index sample:
26/Apr/2031
[14 5 9 2 15 2 5 3 6 4 13]
DateData类
PAD_ID = 0
class DateData:
def __init__(self, n):
np.random.seed(1)
self.date_cn = []
self.date_en = []
for timestamp in np.random.randint(143835585, 2043835585, n):
date = datetime.datetime.fromtimestamp(timestamp)
self.date_cn.append(date.strftime("%y-%m-%d")) #年月日
self.date_en.append(date.strftime("%d/%b/%Y")) #日月年
self.vocab = set(
[str(i) for i in range(0, 10)] + ["-", "/", "" , "" ] + [
i.split("/")[1] for i in self.date_en]) # 把月份加到字典
self.v2i = {v: i for i, v in enumerate(sorted(list(self.vocab)), start=1)}
self.v2i["" ] = PAD_ID
self.vocab.add("" ) #set集合的函数add
self.i2v = {i: v for v, i in self.v2i.items()}
self.x, self.y = [], []
for cn, en in zip(self.date_cn, self.date_en): # 构造数据集
self.x.append([self.v2i[v] for v in cn]) #将word转化成id
self.y.append( #对应 26/Feb/1998
[self.v2i["" ], ] + [self.v2i[v] for v in en[:3]] + [
self.v2i[en[3:6]], ] + [self.v2i[v] for v in en[6:]] + [
self.v2i["" ], ])
self.x, self.y = np.array(self.x), np.array(self.y) #2维[sentences, length]
self.start_token = self.v2i["" ]
self.end_token = self.v2i["" ]
def sample(self, n=64): # 采样batch
bi = np.random.randint(0, len(self.x), size=n)
bx, by = self.x[bi], self.y[bi]
#np.full (shape, fill_value, dtype=None, order=‘C’)
decoder_len = np.full((len(bx),), by.shape[1] - 1, dtype=np.int32) #第一个词到创建Transformer实例
SparseCategoricalCrossentropy类
SparseCategoricalCrossentropy参数
将y_true变成了one-hot编码,使用Sparse
tf.math.equal函数或其他常用tf.where
返回布尔型的张量比较结果
- tf.where(cond, a, b)操作可以根据 cond 条件的真假从 a 或 b 中读取数据,其中 i 为张量的索引,返回张量大小与 a,b 张量一致,当对应位置中cond 为 True,o 位置从a 中复制数据;当对应位置中cond 为False,o 位置从b 中复制数据。
- 当 a=b=None 即 a,b 参数不指定时,tf.where 会返回 cond 张量中所有 True 的元素的索引坐标
tf.boolean_mask:通过布尔值 过滤元素
当 tensor 与 mask 维度一致时,return 一维
tf.linalg.band_part,旧版本tf.matrix_band_part;
功能是以对角线为中心,取它的副对角线部分,其他部分用0填充。
- num_lower:下三角矩阵保留的副对角线数量,从主对角线开始计算,相当于下三角的带宽。取值为负数时,则全部保留。
- num_upper:上三角矩阵保留的副对角线数量,从主对角线开始计算,相当于上三角的带宽。取值为负数时,则全部保留。
对象是一条条对角线
MODEL_DIM = 32
MAX_LEN = 12
N_LAYER = 3
N_HEAD = 4
DROP_RATE = 0.1
m = Transformer(MODEL_DIM, MAX_LEN, N_LAYER, N_HEAD, d.num_word, DROP_RATE)
class Transformer(keras.Model):
def __init__(self, model_dim, max_len, n_layer, n_head, n_vocab, drop_rate=0.1, padding_idx=0):
super().__init__()
self.max_len = max_len
self.padding_idx = padding_idx
self.embed = PositionEmbedding(max_len, model_dim, n_vocab)
self.encoder = Encoder(n_head, model_dim, drop_rate, n_layer)
self.decoder = Decoder(n_head, model_dim, drop_rate, n_layer)
self.o = keras.layers.Dense(n_vocab)
# from_logits将y_pred转化为概率(用softmax) 这是一个类
# “none” 自定义损失函数,reduction必须设置为None,返回每个样本的损失。
self.cross_entropy = keras.losses.SparseCategoricalCrossentropy(from_logits=True, reduction="none")
self.opt = keras.optimizers.Adam(0.002)
def call(self, x, y, training=None):
x_embed, y_embed = self.embed(x), self.embed(y) #position embedding
pad_mask = self._pad_mask(x) # 标记x中pad_id为true
encoded_z = self.encoder.call(x_embed, training, mask=pad_mask)
decoded_z = self.decoder.call(
y_embed, encoded_z, training, yz_look_ahead_mask=self._look_ahead_mask(y), xz_pad_mask=pad_mask)
o = self.o(decoded_z)
return o
def step(self, x, y):
with tf.GradientTape() as tape:
logits = self.call(x, y[:, :-1], training=True)
pad_mask = tf.math.not_equal(y[:, 1:], self.padding_idx) # 标记y中非pad_id为true
loss = tf.reduce_mean(tf.boolean_mask(self.cross_entropy(y[:, 1:], logits), pad_mask))
grads = tape.gradient(loss, self.trainable_variables) # 常规步骤
self.opt.apply_gradients(zip(grads, self.trainable_variables))
return loss, logits
def _pad_bool(self, seqs):
return tf.math.equal(seqs, self.padding_idx)
def _pad_mask(self, seqs):
mask = tf.cast(self._pad_bool(seqs), tf.float32)
return mask[:, tf.newaxis, tf.newaxis, :] # (n, 1, 1, step)
def _look_ahead_mask(self, seqs):
# 1-下三角为1 : 上三角不包含对角线为1
mask = 1 - tf.linalg.band_part(tf.ones((self.max_len, self.max_len)), -1, 0)
mask = tf.where(self._pad_bool(seqs)[:, tf.newaxis, tf.newaxis, :], 1, mask[tf.newaxis, tf.newaxis, :, :])
return mask # (step, step)
这里清晰看到transformer有那几个组成部分
mask
decoder的attention图,为什么是一个三角形? 原因在我在上面提到的,预测时,不能让后文的信息影响到前文,就会用一个look_ahead_mask将后文的信息给遮盖住。这个mask长成这样:
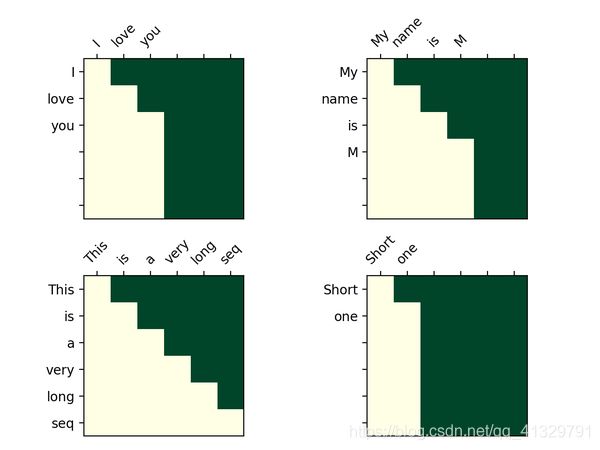
那问题又来了,为什么这个mask不是一个对角的三角形呢?原因是有些句子没那么长,也可以一起mask掉,我把这种叫做 pad_mask,像下图这样。

def masks(seqs):
mask = 1 - tf.linalg.band_part(tf.ones((5, 5)), -1, 0)
# [3,5]->[3,1,1,5] x:1(boardcast) y:[1,1,5,5] ---> [3,1,5,5]
mask = tf.where(tf.math.equal(seqs,0)[:, tf.newaxis, tf.newaxis, :], 1, mask[tf.newaxis, tf.newaxis, :, :])
print(mask)
x = tf.constant([[1,2,3,0,0],[4,3,2,1,0],[5,4,0,0,0]])
masks(x)
结果:
tf.Tensor(
[[[[0. 1. 1. 1. 1.]
[0. 0. 1. 1. 1.]
[0. 0. 0. 1. 1.]
[0. 0. 0. 1. 1.]
[0. 0. 0. 1. 1.]]]
[[[0. 1. 1. 1. 1.]
[0. 0. 1. 1. 1.]
[0. 0. 0. 1. 1.]
[0. 0. 0. 0. 1.]
[0. 0. 0. 0. 1.]]]
[[[0. 1. 1. 1. 1.]
[0. 0. 1. 1. 1.]
[0. 0. 1. 1. 1.]
[0. 0. 1. 1. 1.]
[0. 0. 1. 1. 1.]]]], shape=(3, 1, 5, 5), dtype=float32)
end
下一节介绍transformer的embedding、encoder、decoder代码