德州农工大学贺赟:向预训练语言模型注入专业领域知识
⬆⬆⬆ 点击蓝字
关注我们
AI TIME欢迎每一位AI爱好者的加入!
目前已经有很多工作尝试将外部知识融入到以BERT为代表的预训练语言模型中,它们主要集中在常识(Commonsense Knowledge)和开放领域知识(Open Domain Knowledge)。但是,有很多重要的任务需要用到专业的领域知识(Specialized Domain Knowledge),比如医疗自动问答需要BERT拥有一定的医学知识。
本次AI TIME策划的EMNLP 2020专题报告,特别邀请到来自德州农工大学的贺赟跟大家分享向预训练语言模型注入专业领域知识。

贺赟:德州农工大学(Texas A&M University)博士四年级,导师是James Caverlee教授。研究方向包括推荐系统,信息检索和自然语言处理。

一、 前言
EMNLP2020收录了我们最近的两篇文章:
1)Infusing Disease Knowledge into BERT for Health Question Answering, Medical Inference and Disease Name Recognition
https://arxiv.org/pdf/2010.03746.pdf
2)PARADE:A New Dataset for Paraphrase Identification Requiring Computer Science Domain Knowledge
https://arxiv.org/pdf/2010.03725.pdf
在第一篇中,我们将疾病相关的知识(Disease Knowledge)注入到BERT中,在消费者健康问答(Health Question Answering), 医学语言推理(Medical Language Inference), 疾病名称识别(Disease Name Recognition)三个任务上都取得了更好的效果。
在第二篇中,我们构建了一个新的paraphrase identification数据集称作PARADE,用于检验自然语言模型是否能很好的融合专业领域知识。比如在下面的例子中,Definition 1 和 Definition 2都是在描述计算机领域中的类型推断(Type Inference)这个概念, 所以它们是同义转述(paraphrase)。但是这两句话极少有相似的表述(Lexical divergence),所以BERT将它们判别为不是同义转述(non-paraphrase)。因此,能否对这样的例子进行正确判断,可以验证模型是否很好的融合了计算机领域的专业知识。

PARADE数据集已经公开,欢迎大家下载和使用。接下来本文主要讲第一篇。
二、疾病知识对生物医学NLP任务的帮助
疾病对于人类社会有着重大的影响,例如新冠肺炎已经在全球夺走了超过100万人的生命。疾病也是生物医学中的重要研究课题之一,同时也经常出现在生物医学自然语言处理的任务中。疾病的知识是关于疾病的各个方面(Aspect)的信息,比如症状、诊断和治疗。以新冠肺炎为例如下:
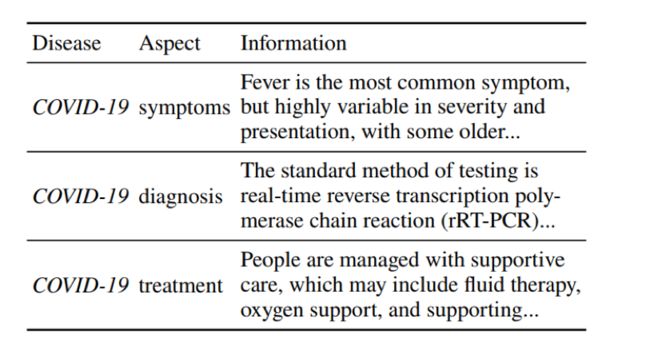
专业的疾病知识对于许多与健康相关的生物医学自然语言处理(NLP)任务至关重要,例如:消费者健康问答、医学语言推理、疾病名称识别。
消费者健康问答例子如下所示:

医学语言推理例子如下所示:

疾病名称识别例子如下所示:

对于这些任务,NLP模型捕获疾病知识至关重要,即疾病描述文本与其相应的疾病(Disease)和方面(Aspect)的语义关系。
对于消费者健康问答例子,如果模型可以在语义上将“ ...实时逆转录聚合酶链反应...”(疾病描述文字)与COVID-19(疾病)的诊断(方面)联系起来,模型可以更准确的从候选答案中选出正确的答案。
对于医学语言推理的例子,如果模型知道失语症的症状,那么上面例子可以很轻易就被预测对。
对于疾病识别的例子,如果模型可以在语义上将“ CTG扩展”与肌强直性营养不良(疾病)的原因(方面)联系起来,则它们更容易发现这种疾病名称。
因此作者们把疾病的症状、诊断和治疗等方面的知识注入到预训练语言模型中,对医疗相关的NLP任务是有帮助的。
三、预训练语言模型
3.1 BERT
负采样
BERT这样的预训练语言模型已经在NLP领域取得了巨大的成功。使用Transformer作为算法的主要框架,通过对大型无标注的文本据进行预训练来调整其参数,然后对下游任务进行进一步的微调。BERT通过Mask Language Model(MLM)和Next Sentence Prediction(NSP)在文本语料上进行预训练的。
3.2医疗相关的BERT模型
负采样
把疾病知识注入到预训练语言模型BERT中,衍生出了很多BERT的变体。比如BioBERT 、ClinicalBERT 、BlueBERT 、SciBERT。
BioBERT:是第一个在生物医学语料库上经过预训练的BERT。使用BERT的预训练参数(108M)对其进行初始化,然后通过PubMed摘要(4.5B词)和PubMed Central全文文章(13.5B词)进行进一步训练。
ClinicalBERT:是从BioBERT v1.0初始化的BERT模型,并在MIMIC-III v1.4患者笔记数据库中约200万的数据进一步进行训练。
BlueBERT:使用BERT的预训练参数(108M)对其进行初始化,然后在PubMed摘要和临床笔记的生物医学语料库中进行进一步训练。
SciBERT:使用BERT的预训练参数(108M)对其进行初始化,然后在来自Semantic Scholar的1.14M论文上进行预训练,其中18%计算机科学领域的论文,生物医学领域的论文占82%。
3.3 论文核心思想
负采样
作者们提出了一种新的疾病知识注入方法,利用疾病知识显着增强BERT模型效果。核心思想是训练BERT从疾病描述文本中推断出相应的疾病(比如COVID-19)和方面(比如诊断),并借助来自Wikipedia的弱监督信号来实现。
给定从疾病的Wikipedia文章的一部分(通常描述一个方面)中摘录的一段话,BERT被训练去推断相应部分的标题(方面名称)和相应文章的标题(疾病名称)。
作者们构建了包含疾病和方面的辅助语句,例如“ COVID-19的诊断是什么?”并将此句子插入相应段落的前面。掩盖疾病名称(COVID-19)和方面(诊断),然后让模型进行推断,BERT学习到如何将疾病描述文本与相应的方面(诊断)以及疾病名称进行语义关联。
四、 疾病知识注入训练
我们的目标是将BERT预训练语言模型与疾病知识集成在一起,以在各种医学领域任务中实现更好的性能,包括健康问答、医学语言推理和疾病名称识别。我们需要思考一下问题:我们应该关注哪些疾病和方面?我们如何将疾病知识注入BERT?模型的训练目标是什么?
4.1 来自维基百科的弱监督知识灌输
负采样
作者们让BERT模型在一篇描述疾病的文章中推断出相应的疾病和方面。模型需要捕捉疾病描述文本与疾病方面的语义关系。这里需要有标注的文本,或者提供弱监督的方法和数据。
考虑了从疾病相关的论文、临床记录或生物医学网站上的数据,其主题(疾病和方面)很难确定的。医学专家注释既费时又昂贵,并且没有一个好的方法进行而自动标注。
这里我们考虑使用维基百科的数据进行弱监督知识灌输,它可以较好的进行自动标注。维基百科数据如下所示:

作者们利用维基百科的结构作为弱监督信号,在多数情况下每种疾病的方面都在维基百科的文章里分成了几个部分,如上图所示。
维基百科文章的章节标题(如diagnosis)就是章节所描述的主题方面,文章的标题就是主题疾病(如COVID-19)。作者们通过维基百科来获得的文章,从MeSH中提取5853个疾病名称,通过正则表达式提取疾病方面以及对应的章节文本,共收集到14617篇描述疾病的章节。
4.2疾病和方面预测的辅助句
负采样
另外一个问题是提取的段落不一定提到相应的疾病名称和方面,作者们解决这样的问题的办法是在文章段落前面添加一个辅助句子。“What is the [Aspect] of [Disease]? 如下图所示:

在相应段落的开头插入上面的辅助句,形成一个新的段落。BERT被训练来预测掩蔽的[Disease]和[Aspect]。
4.3训练的目标和细节
负采样
作者提出训练目标结合[Disease]和[Aspect],具体公式如下:
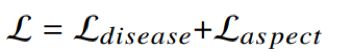
作者们考虑在softmax归一化之前最大化原始logit(Zt),以保留更多有用的信息。根据经验,我们将logit的倒数加到交叉熵损失中:disease Loss函数如下:
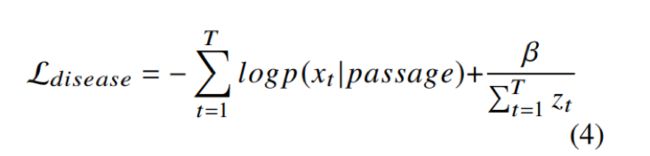
β平衡两个部分的参数。
五、实验结果
5.1 任务
负采样
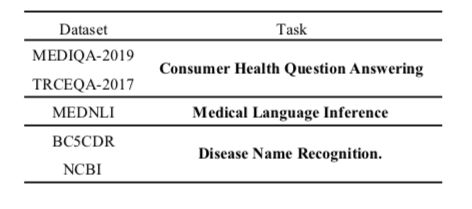
在三种医疗相关任务(健康问答、医学语言推理和疾病名称识别)上验证效果,并将疾病知识输入到六种BERT及其变体中,包括BERT,ALBERT,BioBERT,ClinicalBERT,BlueBERT和SciBERT,其中BioBERT,ClinicalBERT,BlueBERT和SciBERT引入了生物医学领域文本预训练。数据集对应的任务如下表:
5.2 总体结果
负采样
整体实验结果如下:
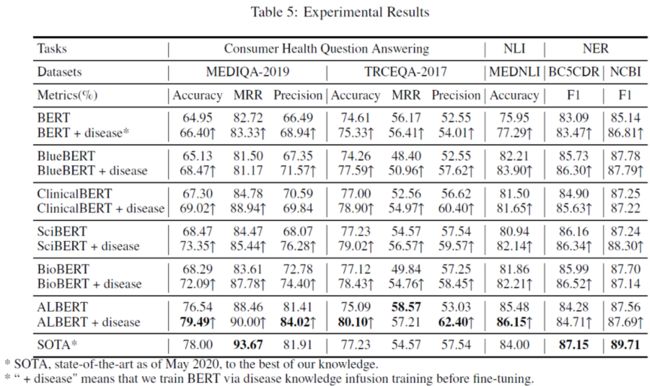
上表为实验结果,其中+disease为注入疾病知识的模型。经由表格可以发现,疾病知识注入有效提升了预训练模型大部分任务上的效果。在未使用大规模医疗数据预训练的模型中,ALBERT + disease在MEDIQA-2019和MEDNLI达到SOTA。在如BioBERT等使用了大规模医疗数据预训练上同样有提升。另外,使用生物医疗领域数据预训练的模型在这几个任务上效果好于未使用专业领域语料预训练的BERT-base。
5.3 消融实验
负采样
作者分别删除了辅助句子、标题预测以及疾病预测这三个子任务,同时还比较了只用随机掩盖的效果。如下表所示:
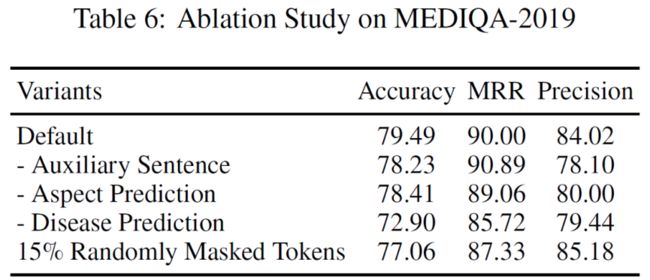
作者对引入的几个与训练任务在MEDIQA-2019数据集上进行了消融实验。实验结果表明作者引入的几个子任务对于模型在该数据集上效果提升均有较大帮助,其中删除Disease Prediction对于效果影响最为明显。
总结
作者们提出了一种在预训练语言模型上注入专业知识的方法,让BERT增加疾病相关的知识。作者们提出的方法可以增强通用BERT模型(例如BERT和ALBERT)和生物医学BERT模型(例如ClinicalBERT和BioBERT)在生物医学自然语言处理(NLP)任务的效果。并且刷新了MEDIQA-2019 and MEDNLI 两个数据集的最优结果。
整理:李键铨
审稿:贺赟
排版:杨梦蒗
本周直播预告:


AI TIME欢迎AI领域学者投稿,期待大家剖析学科历史发展和前沿技术。针对热门话题,我们将邀请专家一起论道。同时,我们也长期招募优质的撰稿人,顶级的平台需要顶级的你,请将简历等信息发至[email protected]!
微信联系:AITIME_HY

AI TIME是清华大学计算机系一群关注人工智能发展,并有思想情怀的青年学者们创办的圈子,旨在发扬科学思辨精神,邀请各界人士对人工智能理论、算法、场景、应用的本质问题进行探索,加强思想碰撞,打造一个知识分享的聚集地。

更多资讯请扫码关注
(直播回放:https://b23.tv/rHuLsH)
(点击“阅读原文”下载本次报告ppt)