基于YOLOv5实现中药饮片识别(含源码)【目标检测项目】
一. 项目背景
中医药文化是中华民族传统文化的瑰宝之一,历史源远流长。中药饮片是中药材在中医药理论指导下,结合药材自身性质及调剂、制剂要求,按照特定炮制方法加工而成,是中医临床开方施治的基础。但中药种类繁多,单凭肉眼难以长时间高效准确地对其识别与分类。
近年来,深度学习技术在图像识别领域取得较大进展,其特征学习方法和深层结构可自动学习图像高层语义信息,拟合复杂模型的能力增强。结合YOLOv5,我们可以实现中药饮片实时目标检测。
二. 项目环境配置
| 工具 | 版本 |
|---|---|
| 操作系统 | Windows 10 家庭中文版 |
| IDE | PyCharm 2019.1.1(Professional Edition) |
| Python | Anaconda Python 3.8 |
| Pytorch | torch 1.7.1+cu101 |
| CUDA | V11.0.194 |
| cuDNN | 8.0.5 |
| 显卡 | NVIDIA GeForce MX 150 |
附上虚拟环境所需的所有的模块:
(yolov5) C:\Users\Tianle Hu>pip list
Package Version
---------------------- ---------------------
absl-py 0.12.0
cachetools 4.2.1
certifi 2020.6.20
chardet 4.0.0
cycler 0.10.0
Cython 0.29.22
future 0.18.2
google-auth 1.28.0
google-auth-oauthlib 0.4.3
grpcio 1.36.1
idna 2.10
kiwisolver 1.3.1
labelImg 1.8.5
lxml 4.6.3
Markdown 3.3.4
matplotlib 3.3.4
numpy 1.20.1
oauthlib 3.1.0
opencv-python 4.5.1.48
pandas 1.2.3
Pillow 8.1.2
pip 21.0.1
protobuf 3.15.6
pyasn1 0.4.8
pyasn1-modules 0.2.8
pycocotools 2.0.2
pyparsing 2.4.7
PyQt5 5.15.4
PyQt5-Qt5 5.15.2
PyQt5-sip 12.8.1
python-dateutil 2.8.1
pytz 2021.1
PyYAML 5.4.1
requests 2.25.1
requests-oauthlib 1.3.0
rsa 4.7.2
scipy 1.6.2
seaborn 0.11.1
setuptools 52.0.0.post20210125
sip 4.19.13
six 1.15.0
tensorboard 2.4.1
tensorboard-plugin-wit 1.8.0
thop 0.0.31.post2005241907
torch 1.7.1+cu101
torchaudio 0.7.2
torchvision 0.8.2+cu101
tqdm 4.59.0
typing-extensions 3.7.4.3
urllib3 1.26.4
Werkzeug 1.0.1
wheel 0.36.2
wincertstore 0.2
三. 制作数据集
- 通过爬虫爬取164类中药饮片图像,以每一类中药名命名该文件夹,如下图所示(仅展示了前10类中药饮片):

这里我们取十味中药作为我们目标检测的对象:

- 我们将这十味中药放置到data文件夹下面的images中,格式均为.jpg
项目文件夹架构如下:
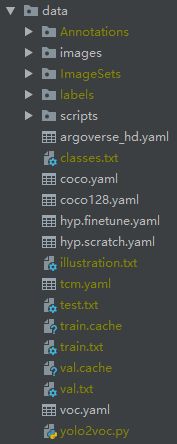
data目录下包含Annotations, images, ImageSets, labels 四个文件夹:
| 文件夹名 | 备注 |
|---|---|
| Annotation | 存储 xml 文件 |
| images | 存储 jpg 格式图片 |
| ImageSets | 存储 txt 格式文件,包含分类和检测的数据集分割文件 |
| labels | 存储 txt 格式文件,包含label标注信息 |
ImageSets文件夹包含四个 txt 文件:
| 文件夹名 | 备注 |
|---|---|
| train.txt | 包含训练集图像名称 |
| val.txt | 包含验证集图像名称 |
| trainval.txt | 包含训练集和验证集的合集图像名称 |
| test.txt | 包含测试集图像名称 |
- 数据集标注
采用LabelImg进行标注,如果带yolo转换格式的就直接用该格式进行标注,如果没有的话可以选择PascalVOC格式,然后再进行转换即可。
下图展示的是对艾叶图像数据集的标注:
images文件夹下包含原始中药图像数据集:
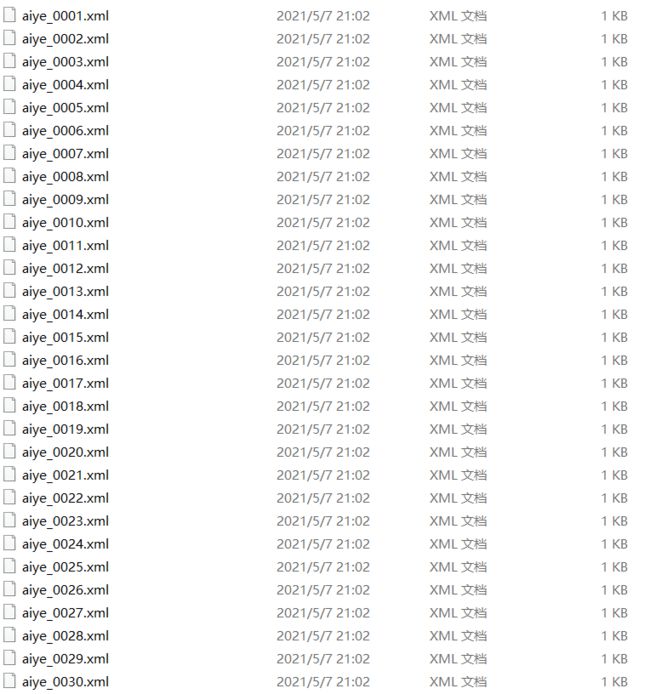
如果是使用PascalVOC进行图像数据集标注的话会生成xml文件,我们将其保存到data文件夹下的Annotations文件夹进行保存:
如果是直接使用了yolo格式进行图像数据集标注的话则可以在data文件夹下的labels的文件夹下得到 .txt 文件:
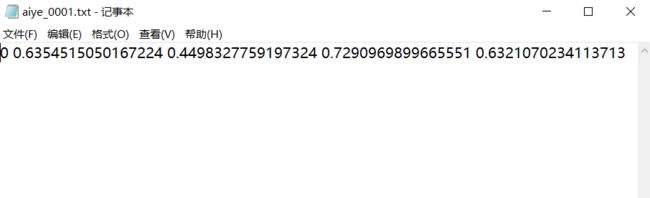
第一列的 0 表示类别,后面四列数据表示标注时候的bunding框的信息。 - 运行
makeTxt.py将数据集按照8:1:1的比例来划分训练集、验证集、测试集(随即分类) - 运行
voc_label.py将图片数据集标注后的xml文件中的标注信息读取出来并写入txt文件,运行后在labels文件夹中出现所有图片数据集的标注信息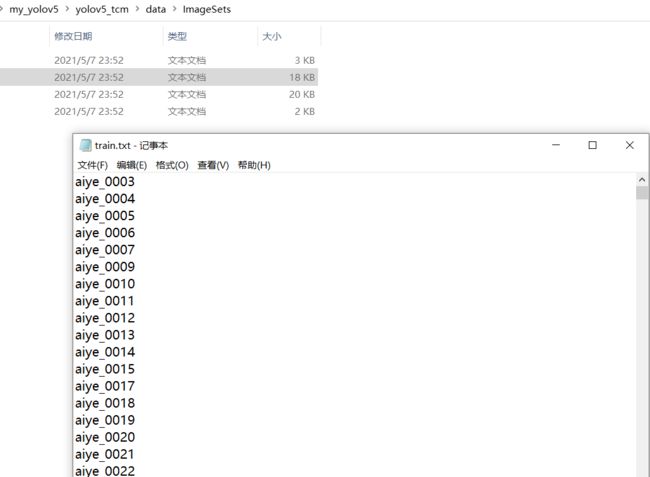
四. yaml文件修改
- 目录:
data/tcm.yaml
修改数据集分类数nc为10,修改分类名称names:
# COCO 2017 dataset http://cocodataset.org
# Download command: bash yolov5/data/get_coco2017.sh
# Train command: python train.py --data ./data/coco.yaml
# Dataset should be placed next to yolov5 folder:
# /parent_folder
# /coco
# /yolov5
# train and val datasets (image directory or *.txt file with image paths)
train: data/train.txt # 1700 images
val: data/val.txt # 100 images
test: data/test.txt # 100 images for submission to https://competitions.codalab.org/competitions/20794
# number of classes
nc: 10
# class names
names: [ 'aiye', 'gouqizi', 'baifan', 'juemingzi', 'chenpi', 'honghua', 'sangshen', 'shanzha', 'xiakucao', 'xixin' ]
# Print classes
# with open('data/coco.yaml') as f:
# d = yaml.load(f, Loader=yaml.FullLoader) # dict
# for i, x in enumerate(d['names']):
# print(i, x)
2.目录:model/yolov5*.yaml
这里的*代表了四个文件:

可以选择其中的某一个模型使用,并修改其中的数据集分类数nc为10:
# parameters
nc: 10 # number of classes
depth_multiple: 0.33 # model depth multiple
width_multiple: 0.50 # layer channel multiple
# anchors
anchors:
- [10,13, 16,30, 33,23] # P3/8
- [30,61, 62,45, 59,119] # P4/16
- [116,90, 156,198, 373,326] # P5/32
# YOLOv5 backbone
backbone:
# [from, number, module, args]
[[-1, 1, Focus, [64, 3]], # 0-P1/2
[-1, 1, Conv, [128, 3, 2]], # 1-P2/4
[-1, 3, C3, [128]],
[-1, 1, Conv, [256, 3, 2]], # 3-P3/8
[-1, 9, C3, [256]],
[-1, 1, Conv, [512, 3, 2]], # 5-P4/16
[-1, 9, C3, [512]],
[-1, 1, Conv, [1024, 3, 2]], # 7-P5/32
[-1, 1, SPP, [1024, [5, 9, 13]]],
[-1, 3, C3, [1024, False]], # 9
]
# YOLOv5 head
head:
[[-1, 1, Conv, [512, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 6], 1, Concat, [1]], # cat backbone P4
[-1, 3, C3, [512, False]], # 13
[-1, 1, Conv, [256, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 4], 1, Concat, [1]], # cat backbone P3
[-1, 3, C3, [256, False]], # 17 (P3/8-small)
[-1, 1, Conv, [256, 3, 2]],
[[-1, 14], 1, Concat, [1]], # cat head P4
[-1, 3, C3, [512, False]], # 20 (P4/16-medium)
[-1, 1, Conv, [512, 3, 2]],
[[-1, 10], 1, Concat, [1]], # cat head P5
[-1, 3, C3, [1024, False]], # 23 (P5/32-large)
[[17, 20, 23], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)
]
五. 超参数设置
train.py
| 主要超参数 | 含义 |
|---|---|
| weights | 权重文件即 yolov5s.pt |
| cfg | 模型配置文件含网络结构即 yolov5*.yaml |
| data | 数据集配置文件即 tcm.yaml |
| epochs | 训练总轮次 |
| batch-size | 批处理大小,每次训练所选取的样本数,建议调小一些(我调了2) |
| img-size | 图像分辨率,默认是640 × 640 |
| project | 训练结果所存放的路径,默认为runs/train |
| name | 训练结果所在文件夹的名称,默认为exp |
| device | 训练设备,使用GPU |
| log-artifacts | 记录最终训练的模型,即last.pt |
parser = argparse.ArgumentParser()
parser.add_argument('--weights', type=str, default='yolov5s.pt', help='initial weights path')
parser.add_argument('--cfg', type=str, default='models/yolov5s.yaml', help='model.yaml path')
parser.add_argument('--data', type=str, default='data/tcm.yaml', help='data.yaml path')
parser.add_argument('--hyp', type=str, default='data/hyp.scratch.yaml', help='hyperparameters path')
parser.add_argument('--epochs', type=int, default=100)
parser.add_argument('--batch-size', type=int, default=4, help='total batch size for all GPUs')
parser.add_argument('--img-size', nargs='+', type=int, default=[640, 640], help='[train, test] image sizes')
parser.add_argument('--rect', action='store_true', help='rectangular training')
parser.add_argument('--resume', nargs='?', const=True, default=False, help='resume most recent training')
parser.add_argument('--nosave', action='store_true', help='only save final checkpoint')
parser.add_argument('--notest', action='store_true', help='only test final epoch')
parser.add_argument('--noautoanchor', action='store_true', help='disable autoanchor check')
parser.add_argument('--evolve', action='store_true', help='evolve hyperparameters')
parser.add_argument('--bucket', type=str, default='', help='gsutil bucket')
parser.add_argument('--cache-images', action='store_true', help='cache images for faster training')
parser.add_argument('--image-weights', action='store_true', help='use weighted image selection for training')
parser.add_argument('--device', default='', help='cuda device, i.e. 0 or 0,1,2,3 or cpu')
parser.add_argument('--multi-scale', action='store_true', help='vary img-size +/- 50%%')
parser.add_argument('--single-cls', action='store_true', help='train multi-class data as single-class')
parser.add_argument('--adam', action='store_true', help='use torch.optim.Adam() optimizer')
parser.add_argument('--sync-bn', action='store_true', help='use SyncBatchNorm, only available in DDP mode')
parser.add_argument('--local_rank', type=int, default=-1, help='DDP parameter, do not modify')
parser.add_argument('--workers', type=int, default=8, help='maximum number of dataloader workers')
parser.add_argument('--project', default='runs/train', help='save to project/name')
parser.add_argument('--entity', default=None, help='W&B entity')
parser.add_argument('--name', default='exp', help='save to project/name')
parser.add_argument('--exist-ok', action='store_true', help='existing project/name ok, do not increment')
parser.add_argument('--quad', action='store_true', help='quad dataloader')
parser.add_argument('--linear-lr', action='store_true', help='linear LR')
parser.add_argument('--upload_dataset', action='store_true', help='Upload dataset as W&B artifact table')
parser.add_argument('--bbox_interval', type=int, default=-1, help='Set bounding-box image logging interval for W&B')
parser.add_argument('--save_period', type=int, default=-1, help='Log model after every "save_period" epoch')
parser.add_argument('--artifact_alias', type=str, default="latest", help='version of dataset artifact to be used')
opt = parser.parse_args()
六. 训练模型
- 至此项目全部配置完毕,执行train.py进行训练,这里我设置
epochs为100,使用GPU的话大概是4 - 5h。
出现如下程序运行界面则说明已开始训练,耐心等待即可:


- 使用
tensorboard进行训练结果可视化
(base) C:\Users\Tianle Hu>activate yolov5
(yolov5) C:\Users\Tianle Hu>f:
(yolov5) F:\>cd F:\PycharmProjects\my_yolov5\yolov5_tcm
(yolov5) F:\PycharmProjects\my_yolov5\yolov5_tcm>tensorboard --logdir runs/train/exp4
TensorFlow installation not found - running with reduced feature set.
Serving TensorBoard on localhost; to expose to the network, use a proxy or pass --bind_all
TensorBoard 2.4.1 at http://localhost:6006/ (Press CTRL+C to quit)

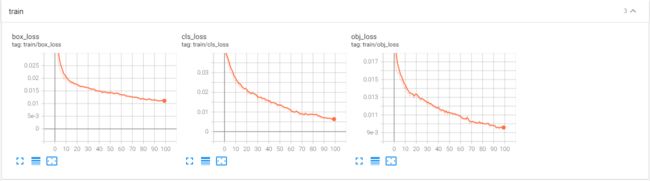

- 最终训练结果

- 训练好的权重文件

| 权重文件名 | 含义 |
|---|---|
| best.pt | 训练100个epochs后所得到的最好的权重 |
| last.pt | 最后一轮训练所得到的权重 |
七. YOLOv5 实现中药饮片实时目标检测
detect.py
parser = argparse.ArgumentParser()
parser.add_argument('--weights', nargs='+', type=str, default='runs/train/exp4/weights/best.pt', help='model.pt path(s)')
parser.add_argument('--source', type=str, default='0', help='source') # file/folder, 0 for webcam
parser.add_argument('--img-size', type=int, default=640, help='inference size (pixels)')
parser.add_argument('--conf-thres', type=float, default=0.25, help='object confidence threshold')
parser.add_argument('--iou-thres', type=float, default=0.45, help='IOU threshold for NMS')
parser.add_argument('--device', default='', help='cuda device, i.e. 0 or 0,1,2,3 or cpu')
parser.add_argument('--view-img', action='store_true', help='display results')
parser.add_argument('--save-txt', action='store_true', help='save results to *.txt')
parser.add_argument('--save-conf', action='store_true', help='save confidences in --save-txt labels')
parser.add_argument('--classes', nargs='+', type=int, help='filter by class: --class 0, or --class 0 2 3')
parser.add_argument('--agnostic-nms', action='store_true', help='class-agnostic NMS')
parser.add_argument('--augment', action='store_true', help='augmented inference')
parser.add_argument('--update', action='store_true', help='update all models')
parser.add_argument('--project', default='runs/detect', help='save results to project/name')
parser.add_argument('--name', default='exp', help='save results to project/name')
parser.add_argument('--exist-ok', action='store_true', help='existing project/name ok, do not increment')
opt = parser.parse_args()
| 主要超参数 | 含义 |
|---|---|
| weights | 选用训练的权重 |
| source | 检测图片/视频数据,'0’表示电脑自带摄像头 |
| conf-thres | 置信度阈值,检测到的对象属于特定中药的概率 |
| project | 检测结果所存放的路径,默认为runs/detect |
| view-img | 是否展示检测之后的图片/视频,默认False |
修改完detect.py文件后执行即可调用电脑自带摄像头进行中药实物实时目标检测:

我这里拿的iPad搜索图片放在电脑自带摄像头面前进行检测的,图片有点糊,所以显示效果不太好,如果换中草药实物的话识别结果会更好一些。
八. 总结
中医药是国家的瑰宝,是老祖宗流传下来的精髓,传承并发扬丰富多彩的中医药文化是我们的使命,结合现代科学技术,进一步提升中医药文化的地位并充分发挥其价值对我们的的生产生活都大有裨益。