编码器-解码器网络:神经翻译模型详解
来源:macbrennan90.github
编译:weakish
转载自:论智
编者按:Mac Brennan详细讲解了用于机器翻译的编码器-解码器架构。

概要
本文将讲解如何创建、训练一个法翻英的神经翻译模型。本文的重点是解释概念,具体的项目代码请参考配套的Jupyter notebook(链接见文末)。
这篇文章大致分成两部分:
理解模型概念
简短总结模型表现
这篇文章参考了PyTorch序列到序列教程,不过试图更深入一点。感谢Sean Robertsan和PyTorch提供了这么棒的教程。
理解模型
编码器-解码器网络是一个很成功的翻译模型。这个模型接受一个序列作为输入,并将序列中的信息编码为中间表示。然后解码器解码中间表示为目标语言。在我们的这个项目中,输入序列是法语句子,输出是相应的英语翻译。
在我们深入编码器和解码器如何工作之前,我们需要了解下模型是如何表示我们的数据的。在对模型的工作机制一无所知的情况下,我们可以合理地推测如果我们给模型一个法语句子,模型能给我们对应的英语句子。也就是说,输入一个单词序列,模型应该输出另一个单词序列。然而,模型只不过是一组参数,在输入上进行多种运算。模型并不知道什么是单词。类似ASCII编码将字母映射到数字,我们的单词也需要转成数值表是。为此,数据集中的每个唯一的单词需要有一个唯一的索引。模型接受的实际上不是一个单词序列,而是一个索引序列。
一次传入一个句子,这没什么问题。不过,怎样才能一次传入多个句子以加速训练过程呢?句子长短不一。这些数字序列又该如何组织呢?答案是输入序列将表示为维度等于(batch大小 × 最大句子长度)的张量(矩阵)。这样就可以一次输入一组句子,短于数据集中最长句的句子可以用事先确定的“补齐索引”补齐。如下图所示:

编码器
词嵌入
输入张量让我们能够以索引序列的形式输入多个句子。这个方向是对的,但这些索引并没有保留什么信息。索引54代表的单词,和索引55代表的单词可能全无关系。基于这些索引数字进行计算没什么意义。这些索引需要以其他格式表示,让模型可以计算一些有意义的东西。一种更好的表示单词的方法是词嵌入。
词嵌入用N维向量表示每个单词。相似单词具有相似词嵌入,在N维嵌入空间中距离相近。词嵌入基于在某种语言任务上训练的模型得到。幸运的是,其他研究人员已经完成了这项工作,同时发布了相关成果。我们的项目使用的是FastText的300维词嵌入。
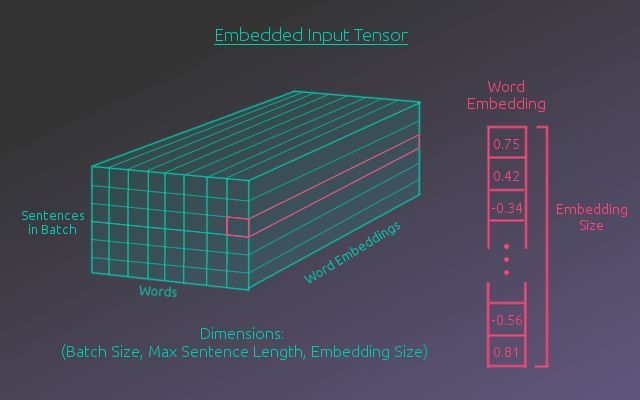
将输入句子表示为词嵌入序列后,可以传入编码器的循环层。
编码器架构
上述嵌入过程通过一个嵌入层完成。整个编码器的架构如下图所示。

从上图我们可以看到,输入张量通过嵌入层之后,到达双向RNN层。双向RNN既从前往后处理序列,又从后往前处理序列。从后往前处理序列时,已经看过整个序列。
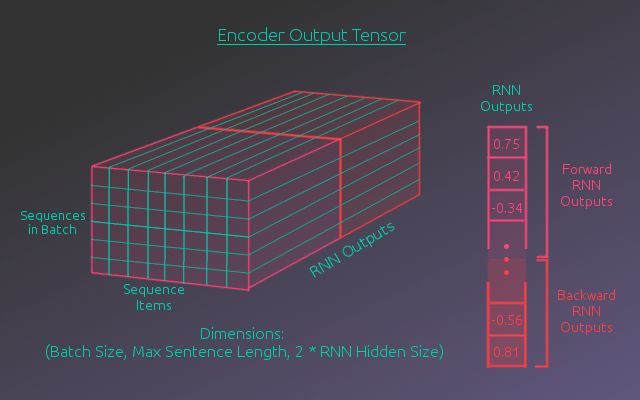
获取嵌入输入张量后,RNN逐步处理序列中的每一项(单词)。在每次迭代中,输出一个长度等于编码器隐藏尺寸的编码向量。RNN并行处理批次中的每个样本。每一步的输出可以看成一个大小为(batch大小 × 编码向量大小)的矩阵,不过实际上整个RNN所有步骤输出一个最终张量。
在处理序列的每一步中,RNN的隐藏状态传给接受序列下一项作为输入的RNN的下一次迭代。迭代同时为批次中的每个样本输出一个编码向量。序列处理的每一步都输出这样一个“矩阵”,并与相应的反向处理序列的RNN步骤输出的矩阵相连接。在我们的项目中,RNN单元使用了两个循环层,中间隔着一个dropout层。另外,我们比较了两种不同的RNN:LSTM(长短时记忆网络)和GRU(门控循环单元)。

RNN层的最终输出是一个张量,其中每步的“矩阵”输出堆叠在一起,如下图所示。
解码器
编码器的最终隐藏状态可以传给另一个RNN(解码器)。该RNN的每个输出都是输出序列中的一个单词,并作为RNN下一步的输入。然而,这样的架构需要编码器编码整个输入序列为最终隐藏状态。相反,如果使用注意力模型,解码器不仅接受最终隐藏状态作为输入,还接受编码器处理输入序列的每一步的输出作为输入。编码器可以赋予编码器输出不同的权重,在计算解码器输出序列的每次迭代中使用。
解码器循环层的最终输入为注意力加权的编码器输出和循环单元前一步的预测单词索引。下为这一过程的示意图,其中“Context”(上下文)表示编码器输出张量。为了简化图形,示意图中省略了嵌入层。
下面让我们详细讨论下注意力模块加权编码器权重的方式。
注意力
回顾下编码器输出张量,序列维度的每一项保存了RNN输出的向量。注意力模块就批次中的每个样本在序列维度上取这些向量的加权和。这样,每个样本得到一个向量,表示当前输出序列步骤计算所需的相关信息。
下面我们将举一个具体的例子。如果输入句子的第一个单词包含了给定输出单词所需的所有最重要的信息,那么第一个单词分配的权重是一,其他各项权重为零。也就是加权向量等于输入句子的第一个单词对应的向量。
模型需要学习如何分配这些权重,所以我们使用了一个全连接层。序列中的每个单词对应一个权重,所以权重数量等于最长句子长度。权重之和应等于一,所以全连接层将使用softmax激活函数。注意力模块将接受解码器先前的隐藏状态与解码器前一步输出的预测单词的词嵌入的连接作为输入,从而决定这些权重的值。下为这一过程的示意图。

计算出这些权重之后,就批次中的每个样本,对权重和编码器输出应用矩阵乘法,得到整个序列的编码向量的加权和。表示批次中每个样本的编码器输出的矩阵,可以看成编码器张量的一个水平切片。下为单个样本的计算过程示意图。实际运算时堆叠批次中的每个样本以构成维度为(batch大小 × 2 × 编码器隐藏向量)的矩阵,得到加权编码器输出。

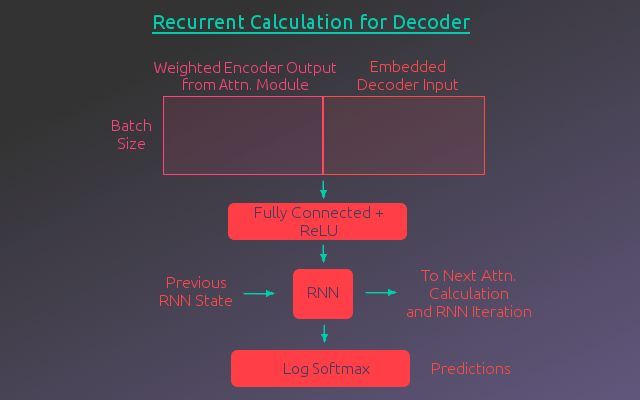
循环计算
编码器输出经注意力模块加权后,可以传给解码器的RNN层了。RNN层同时接受解码器上一步预测的单词的词嵌入作为输入。RNN不直接接受这两个矩阵的连接作为输入,它们在此之前还需通过一个使用ReLU激活的全连接层。这一层的输出作为RNN的输入。
RNN的输出传给一个全连接层,该全连接层使用对数softmax激活,节点数等于输出语言的词汇量。这一层的输出表示对输出序列中的下一个单词的预测。这个单词和RNN的隐藏状态传至注意力模块和RNN的下一步,用来计算序列的下一项。下为这一过程的示意图。不断重复这一过程,直到整个输出序列输出完毕。
训练模型
为训练模型,我们需要计算一个损失函数,反向传播误差以更新模型参数。我们的模型计算的损失函数为输出预测和目标翻译之前的负对数似然,在序列上累加,在批次中取均值。在整个数据集上重复这一过程,经过足够多的epoch后达到要求的结果。
然而,训练语言模型要稍微复杂一点。因为解码器依赖序列前面的项预测后面的项,较早的误差会带偏整个序列。这使得模型学习起来很困难。为了解决这一问题,我们使用了一种称为教师强制(teacher forcing)的技术。这一技术的思路是某些批次(通常是随机选择半数)不将解码器前一步的预测传给下一步,而是将前一步的目标翻译传给下一步。应用教师强制时,解码器每一步的计算使用的是正确的前序单词。这一技术大大降低了训练模型的难度。
创建和训练模型的细节参见配套的Jupyter notebook(链接见文末)。下面简短地总结下模型的表现。
数据集
我们使用了两个数据集。第一个数据集相对简单,词汇量较低,句式看起来也不怎么多样。不过,它倒是有一个优势,训练起来相对较快。第二个数据集更加多样化,尽管句长较短,但词汇量较高,句式也更加多样。
简单数据集
样本数:137861
法语词汇量:356
英语词汇量:228
最长法语句长度:23个单词
最长英语句长度:17个单词
样本示例:
法语句 paris est jamais agréable en décembre , et il est relaxant au mois d' août .
英语句 paris is never nice during december , and it is relaxing in august .
法语句 elle déteste les pommes , les citrons verts et les citrons .
英语句 she dislikes apples , limes , and lemons .
法语句 la france est généralement calme en février , mais il est généralement chaud en avril .
英语句 france is usually quiet during february , but it is usually hot in april .
法语句 la souris était mon animal préféré moins .
英语句 the mouse was my least favorite animal .
法语句 paris est parfois clémentes en septembre , et il gèle habituellement en août .
英语句 paris is sometimes mild during september , and it is usually freezing in august .
多样化数据集
样本数:139692
法语词汇量:25809
英语词汇量:12603
最长法语句长度:10个单词
最长英语句长度:10个单词
法语句 je vais laver les plats
英语句 ill wash dishes
法语句 les nouvelles les rendirent heureux
英语句 the news made them happy
法语句 globalement la conférence internationale fut un succès
英语句 all in all the international conference was a success
法语句 comment marche cet appareil photo
英语句 how do you use this camera
法语句 cest ton jour de chance
英语句 this is your lucky day
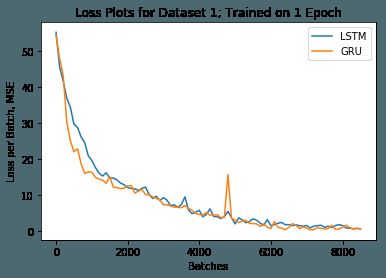
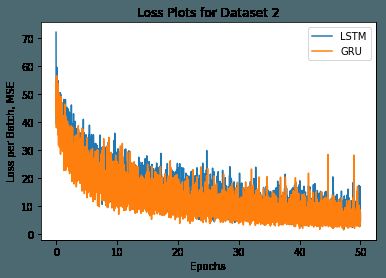
损失图形
如前所述,我们分别实现了双向LSTM和双向GRU。
在第一个数据集上训练一个epoch后的损失图形如下:
在第二个数据集上训练50个epoch后的损失图形如下:
翻译样本和注意力可视化
翻译样本:简单数据集
如上一节所示,在简单数据集上训练一个epoch后,LSTM和GRU都能非常精准地生成正确翻译。然而,模型在翻译句子时看起来并没有用到注意力机制。下面是3个翻译示例,以及相应的输出序列的注意力权重。从这些例子来看,注意力权重说不上随机,但也没有落在我们期望的单词上。
示例一
输入句
californie est sec en janvier , mais il est généralement occupé en mars .
输出句
california is dry during january , but it is usually busy in march .
LSTM模型输出
california is dry during january , but it is usually busy in march .
GRU模型输出
california is dry during january , but it is usually busy in march .

示例二
输入句
new jersey est généralement chaud en juin , et il est parfois merveilleux en hiver .
输出句
new jersey is usually hot during june , and it is sometimes wonderful in winter .
LSTM模型输出
new jersey is usually warm during june , and it is sometimes wonderful in winter .
GRU模型输出
new jersey is usually hot during june , and it is sometimes wonderful in winter .

示例三
输入句
les fraises , les mangues et le pamplemousse .
输出句
i like strawberries , mangoes , and grapefruit .
LSTM模型输出
i like strawberries , mangoes , and grapefruit .
GRU模型输出
i like strawberries , mangoes , and grapefruit .
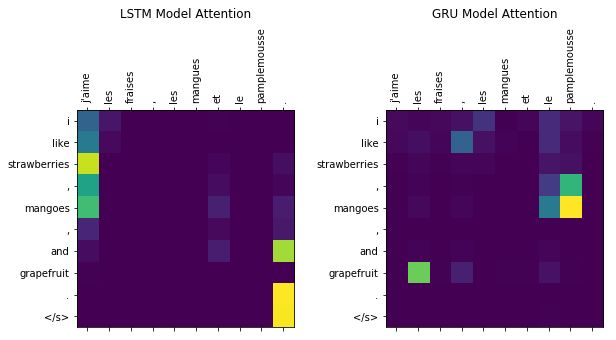
翻译样本:多样化数据集
我们的模型能够正确翻译更加多样化的句子。不过,这需要长很多的时间训练,总共花了50个epoch才得到看起来合理的结果。下面显示了其中几个示例。GRU模型的注意力权重开始揭示模型使用了注意力机制,但LSTM模型看起来仍然没有学习利用注意力机制。这可能是因为LSTM可以访问保存了长期依赖的单元状态。也许注意力计算没能为模型提供足够有用的信息,使模型优先学习更好的注意力计算的参数。
示例一
输入句
jai perdu mon intérêt pour le golf
输出句
ive lost interest in golf
LSTM模型输出
i lost my interest golf
GRU模型输出
ive lost interest in golf

示例二
输入句
le livre était meilleur que le film
输出句
the book was better than the movie
LSTM模型输出
the book was better than the movie
GRU模型输出
the book was better than the movie

示例三
输入句
quel genre de trucs le weekend
输出句
what sort of things do you do on weekends
LSTM模型输出
what sort of things do you do on weekends
GRU模型输出
what sort of stuff do you do on weekends

结语
GRU模型演示了注意力计算让模型重点关注编码序列的不同部分。然而,我们并不清楚为什么LSTM看起来要么没有利用注意力信息,要么基于一种不同的方式使用注意力信息。如果有更多时间,我们想调查下这是为什么。如果使用句长更长的数据集还会这样吗?还可以和不带注意力机制的简单编码器-解码器网络比较一下,看看表现是否优于不带注意力机制的架构,如果优于不带注意力机制的架构,那么是在哪些情况下?
我们选择的架构和PyTorch教程中的模型略有不同。这个项目使用的模型使用了batching,而原教程中的模型每次处理一个序列。因此,原模型不必处理输出补齐。我们本来觉得batching可以通过并行化缩短训练时间,但原模型声称只需大约40分钟就可以在CPU上完成训练,而这个项目所用的模型在GPU上训练了将近12小时,才得到良好的翻译。
一些改进也许可以弥合这一差异。首先,PyTorch有内置的处理补齐序列的函数,这样循环单元不会看到补齐项。这可能提高模型的学习能力。其次,第二个数据集没有处理成token,只是直接移除了标点。这可能导致转换单词为索引时,一些单词无法辨识。这意味着它们会被替换为未知token,使模型更难识别句子的内容。尽管还有提升的空间,总体上而言这个项目是成功的,因为它能够成功地翻译法语为英语。
相关链接
Jupyter notebook:https://nbviewer.jupyter.org/github/macbrennan90/translation-model/blob/master/translation-model.ipynb
PyTorch序列到序列教程:https://pytorch.org/tutorials/intermediate/seq2seq_translation_tutorial.html
原文地址:https://macbrennan90.github.io/neural-translation-model.html
推荐阅读:
一大批历史精彩文章啦
中国法研杯 --- 司法人工智能挑战赛
