Learning Representations For Images With Hierarchical Labels(一、二)
目录
Chapter 1 Introduction
1.1 Motivation
1.1.1 利用标签之间的相互关系
1.1.2 长尾数据分布
1.1.3 视觉相似性并不意味着语义相似性
1.1.4 揭开黑盒模型
1.2 预测馆藏的分类
1.2.1 ETHEC数据集:一种新的基于标签层次结构的昆虫学图像数据集
1.3 Contributions
1.3.1 注入标签层次信息以改进CNN分类器
1.3.2 通过联合嵌入标签和图像来执行图像分类
1.3.3 贡献
1.4 大纲
Chapter 2 Problem Statement & Background
2.1 相关工作
2.1.1 基于嵌入的文本和语言模型
2.1.2 基于嵌入的图像模型
2.1.3 基于卷积神经网络的模型
2.2 背景知识
2.2.1 顺序嵌入 Order-Embeddings
2.2.2 欧式锥
2.2.3 双曲锥
2.2.4 双曲空间中的优化
2.3 数据集
2.3.1 层次化的CIFAR-10
2.3.2 层次化的Fashion MNIST
2.3.3 ETH昆虫学收藏数据集
ETHEC数据集项目
ETHEC数据集的整理和合并
ETHEC小型数据集
2.4 CNN主干网络
2.4.1 AlexNet
2.4.2 VGG
2.4.3 Resnet
Chapter 1 Introduction
1.1 Motivation
这项工作试图利用分层标签形式的语义信息。作者提出,当提供这样的指导时,视觉模型的性能优于层次不可知的模型。作者还展示了如何通过使用更明确的表示模型(如Embedding)来实现图像分类任务,从而提高这些模型的可解释性。
1.1.1 利用标签之间的相互关系
这种模型仅根据视觉信号进行分类。这些模型只捕获标签-图像的相互关系,不使用有关标签间交互的其他可用信息,这些信息可以提高性能,并使模型更易于理解。
1.1.2 长尾数据分布
数据分布不平衡是现实世界机器学习环境中常见的现象。通常情况下,某些类只有少数图像可用。一个合理的解释是,科学家感兴趣的对象在该数据领域中的确很少出现。在生命科学中,它可能是一种罕见的异常现象,而在基于图像的数据集中,它可能是一种比其他物体更不常见的物体。
如果要以层次结构或有向无环图(DAG)的形式排列标签,则表示更抽象数据的类通常会占据上层,而更具体的类则是它们的后代,从而形成层次结构的下层。数据分布是这样的:上层的类较少,但对于给定的标签,平均而言,有更多的数据点。当向下移动到标签层次结构中的较低级别时,分布逐渐改变趋势。在最底层有大量的标签,但每个标签的数据量最少。这导致了长尾分布的形成,上层的阶级贡献了大量的样本,而下层的阶级形成了长尾。
这种长尾分布并不最适合机器学习模型,因为机器学习模型的泛化能力在很大程度上依赖于每个标签的大量数据的可用性。在存在长尾分布的情况下,利用辅助信息可能会有所帮助。通过这种方式,再加上视觉特征,该模型能够将不同级别的类关联起来,并可以利用层次结构中数据丰富的上层的信息。
例如,如果层次结构中较低的特定标签只有少量数据,则如果将有关层次结构的信息注入到模型中,它仍然可以通过其同级(即共享同一父级)共享有关标签的可视信息。通常,同级概念或属于层次结构的同一子树的概念之间存在共性,如果使用有关标签-标签交互的信息,模型可以利用这些共性。
1.1.3 视觉相似性并不意味着语义相似性
视觉模型依靠图像的特征来区分不同的对象。但语义相关的类往往会表现出明显的视觉差异。有时甚至可能出现这样的情况——单个标签的视觉特征的类内方差大于类间方差。在这样的场景中,两个具有不同视觉外观的实例的学习表示会相互排斥,从而间接影响模型的图像理解能力。在图1.1中,可以看出,语义相似性和视觉相似性是怎样不同的两个概念,但它们对于实现更好的视觉理解是必不可少的。
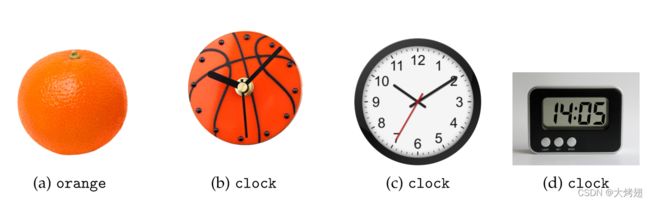 图1.1.虽然(a)中的橙子和(b)中篮球背景的时钟在视觉上有相似之处,但它们在语义上是不相关的。另一方面,数字、有长短针的和篮球主题的时钟在视觉上彼此不同,但在语义上相似,因为它们都是时钟的实例。通过以标签层次结构的形式引入辅助信息,只关注视觉特征的模型可以避免这种混淆。
图1.1.虽然(a)中的橙子和(b)中篮球背景的时钟在视觉上有相似之处,但它们在语义上是不相关的。另一方面,数字、有长短针的和篮球主题的时钟在视觉上彼此不同,但在语义上相似,因为它们都是时钟的实例。通过以标签层次结构的形式引入辅助信息,只关注视觉特征的模型可以避免这种混淆。
1.1.4 揭开黑盒模型
如果人类负责对图像进行分类,自然的方法是识别图像的成员,以抽象概念或标签,然后转向越来越详细的标签,以提供对所讨论对象更细粒度的理解。即使一只未经训练的眼睛无法区分阿拉斯加雪橇犬和西伯利亚哈士奇犬,它也更有可能至少正确理解哺乳动物及其子概念狗的概念。同样,使用标签层次结构来指导分类模型,我们能够弥合机器和人类处理视觉理解的方式上的差距。加入这些辅助信息会积极影响图像理解模型的可解释性和可解释性。
1.2 预测馆藏的分类
这项工作的主要目标之一是协助自然藏品、博物馆和其他类似组织维护包括动植物在内的大型生物多样性图书馆。许多业余收藏家一生都在收藏昆虫和蝴蝶。最终,其中大部分都被捐赠给了收藏品和博物馆。
收藏需要根据分类学对这些标本进行分类。这个过程包括聘请一名专门研究这些生物体特定科的外部专家。分类过程不仅成本高昂,而且还受到可聘请专家数量的限制。如果在完成这项资源密集型任务之前,可以先进行预分类,根据它们的科、亚科、属和物种顺序对这些标本进行分类,这将使整个过程更加经济。
在数据和机器学习的帮助下,非专业人士可以简化这种重复性学习,从而在很大程度上降低成本。在这项工作中,我们特别关注昆虫学,尤其是蝴蝶。ETH收集的数字化版本用于创建数据集[11],以使用本研究中研究的方法进行实证分析。
1.2.1 ETHEC数据集:一种新的基于标签层次结构的昆虫学图像数据集
ETH昆虫学采集(ETHEC)数据集[11]直接取自现场,代表了真实世界的数据集,不仅在每个样本的图像数量方面存在不平衡现象,而且在类及其后代子类之间也存在显著差异,因为其中一些子树节点的大小是不成比例的。在图1.3中,我们展示了ETEC层次结构中每个标签的数据分布。
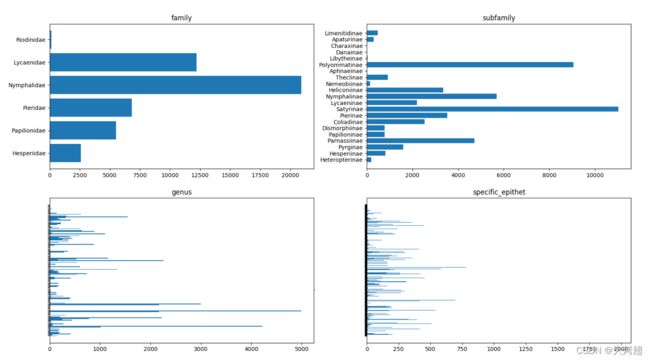 图1.3.该图显示了4个层次中每个标签的图像分布:6个科、21个亚科、135个属和550个种。x轴表示特定标签的图像数量,y轴上的记号表示每个标签。为清楚起见,我们省略了属和种的标签。
图1.3.该图显示了4个层次中每个标签的图像分布:6个科、21个亚科、135个属和550个种。x轴表示特定标签的图像数量,y轴上的记号表示每个标签。为清楚起见,我们省略了属和种的标签。
由于这些特性,数据集可以代表现实世界的场景,与具有平衡类的CIFAR[22]或ImageNet[9]相比,数据集更现实。该数据集为多标签图像分类任务提供了一个具有挑战性的补充。
这些图像来自ETH昆虫学收藏的数字化收藏。我们对它们进行预处理,以去除任何可能将样本标签信息泄露给视觉模型的视觉信号(即条形码、文本标签、标记)。我们还将图像裁剪为位于图像中心,并将其大小调整为448×448。我们还为标签层次结构中的4个级别提供元数据和标签。数据集分为train、val和test三部分,分别为80-10-10。对于少于10张图像的标签,我们在三组图像之间平均分割图像。
 图1.4.来自ETEC数据集的示例图像及其四级标签。该数据集包括47978个蝴蝶标本,其中723个标签分布在4个层次标签上:6科、21亚科、135属和550种
图1.4.来自ETEC数据集的示例图像及其四级标签。该数据集包括47978个蝴蝶标本,其中723个标签分布在4个层次标签上:6科、21亚科、135属和550种
1.3 Contributions
1.3.1 注入标签层次信息以改进CNN分类器
除了层次不可知的baseline,这项工作还提出了4种不同的方法,将关于标签层次的知识传递给分类器,以提高与层次不可知分类器相比的性能。每种方法的不同之处在于它们将这些信息提供给分类器的方式以及注入的信息的种类。因此,在训练期间,除了传统上可用的图像标签对之外,这些方法还提供了额外的标签信息。
所提出的方法不依赖于所使用的特征类型或特征提取器,并且可以很容易地扩展到标签按层次排列的任何分类器。由于这项工作涉及图像分类,我们在实验中使用了著名的CNN[18,23,36]。尽管有一些工作建议直接对CNN架构进行修改[19],但我们避免这样做,因为这些方法是模型不可知的,可以与任何通用分类器一起使用。
1.3.2 通过联合嵌入标签和图像来执行图像分类
在自然语言处理领域,保序嵌入(Order-preserving embeddings)在捕捉概念和标记之间的关系方面表现出了巨大的潜力[16,39,38,25]。这项工作在计算机视觉的背景下探索以解决图像分类的任务。我们将标签(按层次排列)和图像嵌入到联合嵌入空间中。标签和给定图像之间的关系可用于预测标签和对给定图像进行分类。
与在基于CNN的图像特征提取主干上使用经典交叉熵启发的分类损失函数的最新方法不同,我们使用嵌入模型,更明确地表示标签和标签图像的交互。这个想法是为了让CNN从标签层次信息中受益。在我们的实验中,我们发现,使用经典交叉熵启发的损失函数训练的模型比利用标签层次结构的基于嵌入的分类器性能差。根据参数使用的几何结构和嵌入的空间,这些模型可以分为欧几里德模型和非欧几里德模型。
-
欧几里德模型:自然语言领域通常将概念建模为层次结构,并从非结构化文本中学习嵌入。最近的研究[39,16]将它们建模为DAG,并建议嵌入它们以保持它们的不对称蕴涵关系。如果使用对称的距离函数,这些信息通常会丢失。顺序嵌入[39]提出了一种非对称距离函数,它以保留顺序的方式排列嵌入的概念。最近的一种方法是entailment cones[16],它使用了一种更通用的顺序嵌入,这种嵌入更节省空间,性能更好。与上述在自然语言背景下提出的方法不同,我们建议联合嵌入图像及其标签,并使用它们的交互来预测看不见的图像的标签。
-
非欧几里德模型:与欧几里德模型不同,非欧几里德模型利用几何体的非零曲率。与欧几里德几何相比,双曲几何具有负曲率,可以轻松适应树状结构(如DAG)。在双曲空间中,球的体积随半径呈指数增长[32],这与我们在欧几里德空间中已知的多项式增长不同。一组作品[32,16,38]提出利用负曲率空间更好地嵌入概念,并创建最先进的模型来嵌入层次结构。我们使用了一个类似于双曲蕴涵锥[16]的模型,除了标签,我们还嵌入了图像,以联合的方式处理问题。通常,嵌入模型和基于CNN的分类器很难比较,因为它们通常应用于截然不同的用例和领域。我们使用嵌入模型作为图像分类器,能够在不同模型类别之间进行公平的性能比较。除了图像分类和标签与图像的联合嵌入,对于基于嵌入的模型,我们还研究了标签层次本身的嵌入质量。我们报告了ETH昆虫学集合(ETHEC)数据集[11]的性能。
1.3.3 贡献
-
我们展示了如何将通常用于NLP任务的保序嵌入模型扩展到计算机视觉任务,如图像分类。我们比较了基于嵌入的分类器和基于标签层次结构的CNN分类器。嵌入模型的欧几里德变量和非欧几里德变量均已实现,且性能优于层次不可知的baseline。这显示了以联合方式建模和处理位于计算机视觉和自然语言交叉点的下游任务的前景。
-
我们比较了一个多标签层次不可知分类器作为baseline,以及论文中详细介绍的4种将标签层次知识注入分类器的方法。每种方法都考虑了不同抽象层次的层次信息,例如:层次深度、边连接和子树关系。
-
虽然CNN和基于嵌入的模型基于不同的范例,但我们研究了通过合并标签层次信息获得的性能提升。使用本文提供的ETEC数据集,我们的实验表明,无论使用何种类型的模型,利用标签层次结构都能为基于CNN和基于嵌入的分类器带来更好的图像分类性能。
1.4 大纲
本文的其余部分结构如下:
-
Chapter 1概述了这些方法背后的动机以及利用分层组织标签信息的必要性。
-
我们以与本文Chapter 2中提出的方向类似的方式浏览了相关工作。它提供了数学背景的方法,这项工作扩展为联合标签图像嵌入图像分类。它还包含有关数据集和基于CNN的特征提取器(CNN主干)的信息。
-
在Chapter 3中,我们详细讨论了基于CNN的模型中的标签层次注入、标签上的概率分布计算,以及最终如何进行预测。我们首先讨论baseline,它忽略了图像标签交互以外的任何外部信息。对于其余的模型,对于每个模型,有关层次结构的更多信息可供分类器使用。为了清晰起见,我们在Chapter 4中分离并汇编了基于CNN的模型的实证分析。
-
在Chapter 5中,我们概述了基于嵌入的欧几里德和非欧几里德变量模型的细节。本章还讨论了标签嵌入,然后将标签与图像一起嵌入。我们在Chapter 6给出了基于嵌入的模型的实证结果。
-
Chapter 7讨论了结论和未来工作的可能方向。
Chapter 2 Problem Statement & Background
2.1 相关工作
2.1.1 基于嵌入的文本和语言模型
嵌入是一种映射,它将离散对象(如图像、单词或概念)映射到一个相对紧凑的表示形式,即存在于低维嵌入空间中的向量。例如,某种具体语言中的单词可以在 维空间中使用one-hot编码来表示,其中是该语言的词汇量。然而,由于one-hot编码固有的稀疏性,这种表示将包含很少的信息或语义。除了位于低维空间的嵌入之外,理想情况下人们希望这些嵌入以某种方式进行排列,使得嵌入在一起的对象能够表示它们之间的高度语义相似性。
维空间中使用one-hot编码来表示,其中是该语言的词汇量。然而,由于one-hot编码固有的稀疏性,这种表示将包含很少的信息或语义。除了位于低维空间的嵌入之外,理想情况下人们希望这些嵌入以某种方式进行排列,使得嵌入在一起的对象能够表示它们之间的高度语义相似性。
传统方法中,嵌入使用对称距离函数来度量两个对象之间的相似性。当我们试图嵌入存在不对称关系的概念,然后使用这种对称距离函数,这个细节就丢失了。因此,我们需要使用非对称距离函数来捕捉这种关系。
- 有序嵌入(Order-Embeddings):在[39]中,作者将语义层次的嵌入作为偏序处理。他们的工作嵌入了一种本质上是反对称的视觉语义层次结构。作者没有考虑欧几里德距离或曼哈顿距离,而是提出在通过嵌入表示图像和文本的层次结构时,使用非对称距离函数来衡量两个概念之间的相似性。这项工作提出了一个函数,如果子概念位于父概念所拥有的子空间的一部分内,则该函数可以衡量父-子概念关系的存在。距离度量的设计使得它定义了一个子空间,在这个子空间中,子概念是有效的。这个有效空间是正正切平移的空间,其原点位于特定概念嵌入的位置(坐标)。与距离保持性质(通常情况下是这样)相反,顺序嵌入的顺序保持性确保它可以很好地捕获反对称和传递关系,而不必依赖点之间的物理接近性。相反,通过最小化惩罚违反该序的损失来学习嵌入。在[39]中,作者处理了两项任务:超词预测和图像标题检索。超词是一对概念,其中第一个概念比第二个概念更通用或抽象。例如,(水果、芒果)或(情感、幸福)。超名预测任务对概念有一个自然的层次结构,然而,对于图像标题,他们创建了一个两级层次结构,其中标题形成更抽象的上层,而更详细的图像形成下层。
-
欧氏锥(Euclidean cones):略
-
双曲锥(Hyperbolic cones):略、
-
双曲线神经网络:略
-
Disk Embeddings:略
-
其他嵌入方法
2.1.2 基于嵌入的图像模型
[12]中提出的视觉语义嵌入定义了一个相似性度量,而不是一个将给定对分类为正或负的函数。它们计算相似度得分,并返回给定查询的嵌入空间中最接近的概念。它们通过LSTM(长-短时记忆)映射语言特征,通过CNN映射图像,通过线性映射到联合嵌入空间,并使用内积度量该空间中的相似性。他们最小化了基于铰链的三元损失项,并通过计算最近负数的损耗来强调硬负数,而不是对所有负数求和。他们专注于跨模态检索的任务:给定图像的标题检索和给定标题的图像检索。
在一项特定的工作中,嵌入被用于图像分类[21]。这项工作使用顺序嵌入将标签和图像嵌入在一起,以便对层次结构进行分类。这项工作提出首先嵌入标签,然后在明确预测最底层之后,使用嵌入在层次结构中的跨层传递性来隐式地预测上层。我们对此进行了扩展,使用了非欧几里德模型,还提出了基于CNN的模型,在不同程度上利用了层次结构。
2.1.3 基于卷积神经网络的模型
Kumar等人[24]根据服装类型形成的树预测标签。他们根据检测错误的偏置创建层次结构,更具体地说,是通过使用错误矩阵从常常被混淆的类中创建层次结构。他们使用自己的方法,通过创建两级层次结构对服装类型进行分类。为了解释层次结构,他们预测条件概率P(子|父)作为分类器的输出,并将概率相乘,为这两个级别创建预测标签。他们用一个两级的层次结构进行实验,总共有几个标签,我们观察到,当层次结构广泛且数据稀缺时出现的一些问题。他们的方法的一个缺点是,层次结构是在混乱的基础上形成的,而预测仅仅基于视觉线索。这意味着构建的层次结构可能并没有真正的语义相似性作为指导原则,而是视觉相似性。另一方面,我们的方法通过注入有关图像标签和标签交互的信息,将视觉和语义相似性结合到模型中。
在Chen等人[7]所做的工作中,他们提出预测不同层级的标签。他们的工作与我们的工作最接近,因为他们试图预测图像所属层次结构中每一层的标签。他们开发了一个复杂的CNN架构,使用一个公共的特征提取器,然后使用单独的神经网络,每个神经网络专门预测每个级别的标签。他们使用完全独立的网络来预测每个级别的标签,这一事实使得当数据集较小且计算密集时,模型容易过拟合。他们展示了一个具有4级层次结构的数据集,包含200种蝴蝶的图像,类似于ETHEC数据集,并为现有的CUB鸟类数据集构建层次结构[41]。它们将层次结构中最后一级的性能与许多baseline方法进行比较,但这些方法仅预测最细粒度标签类别(=层次结构中的最后一级)的标签,而不预测其他类别的标签。
在与细粒度图像分类相关的任务中,通常只有少数图像具有类别标签。[8]中所做的工作不是微调在所有类别的大型数据集(如ImageNet)上预先训练的模型,而是根据源域和目标域之间的域相似性,选择top-K个标签子集用于预训练。在对视觉上相似的大数据集的子集进行预训练后,转移学习产生的性能优于对整个大数据集进行预训练后进行微调的模型。他们提出了一种更好的方法,在进行预训练时更有效。在类似的方向上,[37]使用层次结构信息来执行迁移学习。
Hu等人[19]致力于对细粒度视觉分类进行分类,由于图像中对象的视觉相似性,类内方差较大,类间方差较小。他们提出了一种CNN架构,试图通过注意力map来学习图像中的辨别区域。然后,通过借助学习到的注意图仔细观察模型,并将注意力吸引到对象的有区别的部分,这将用于细化模型的预测。除此之外,他们还提出在注意力地图的指导下,通过缩放、剪切和删除部分图像,使用无监督的图像数据增强策略,以便更好地概括。建议的模型使用注意图来帮助关注较小的细节,然而,与我们建议的CNN模型不同,它不使用任何关于标签排列层次的信息。人们可以认为它是一种互补的方法,在本文提出的,仅基于视觉线索。
还有一组其他工作[27,27,40,6]使用基于注意的机制来关注图像中的辨别区域。
[28,5]还探讨了利用外部信息的想法,即在学习过程中使用基于部件的属性来帮助模型。
2.2 背景知识
2.2.1 顺序嵌入 Order-Embeddings
通常,对称距离用于确定嵌入空间中概念之间的语义相似性。顺序嵌入[39]提出学习一种映射,它关心的是保持对象之间的顺序而不是距离,并引入了偏序完成问题。从一组已知的有序对P和无序对N中,目标是确定一个任意的、没见过的对是否是有序的。
由于![]() 的理想特性,他们建议在
的理想特性,他们建议在![]() 上使用相反的顺序。这在等式(2.1)中定义:
上使用相反的顺序。这在等式(2.1)中定义:
 相反的顺序意味着较小的坐标表示偏序中的“更高”或更抽象的位置。它们没有硬性约束,而是引入了一个近似的顺序嵌入,以尽可能少地违反它们。
相反的顺序意味着较小的坐标表示偏序中的“更高”或更抽象的位置。它们没有硬性约束,而是引入了一个近似的顺序嵌入,以尽可能少地违反它们。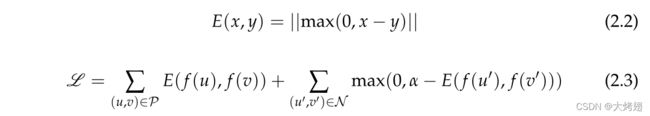 其中,
其中, 和
和 分别代表数据集
分别代表数据集 中的正边和负边。
中的正边和负边。![]() 是边界。
是边界。 是一个将概念映射到其嵌入的函数。
是一个将概念映射到其嵌入的函数。![]() 定义给定对
定义给定对 的顺序违反严重性,由公式(2.2)给出。根据能量
的顺序违反严重性,由公式(2.2)给出。根据能量![]() , 对于“
, 对于“![]() ”这样的正对,我们希望嵌入
”这样的正对,我们希望嵌入![]() 。
。![]() 意味着a是b的子概念,或者相当于b比a更抽象,这是它的推广。
意味着a是b的子概念,或者相当于b比a更抽象,这是它的推广。
2.2.2 欧式锥
2.2.3 双曲锥
2.2.4 双曲空间中的优化
2.3 数据集
2.3.1 层次化的CIFAR-10
我们还使用CIFAR-10数据集进行了实验[22]。有10个类别,每个类别有6000张32x32的图片。该数据集总共有50000张用于训练的图像和10000张用于测试的图像。为了与我们的实验一致,我们使用了80%−10%−10%,即训练、验证和测试。所有微调都在验证集上执行,测试集仅用于报告模型的性能。原始数据集是没有关联的标签层次结构的。相反,每张图片都有一个单一的ground truth标签。添加其他标签以引入三级层次结构。现在,每个图像都与3个标签关联。原始标签是这个层次结构的叶子节点。层次结构的根是实体,层次结构的第一级分为(生命体,非生命体)。生命体分为(哺乳动物、非哺乳动物)。非生命体分为两类(交通工具、船和飞行器)。最初的类别是{飞机、汽车、鸟、猫、鹿、狗、青蛙、马、船、卡车}。哺乳动物是(猫、鹿、狗、马)的父类,非哺乳动物是(鸟、青蛙)的父类。车辆是(汽车、卡车)的父类,而船和飞行器是(飞机、轮船)的父类。
2.3.2 层次化的Fashion MNIST
Fashion MNIST[42]是一个类似于MNIST的数据集,它由10类服装图像组成,而不是手写数字。该数据集有60万个训练样本和10000个测试样本。我们将训练集拆分为50000个用于训练,其余10000个用于验证。每个图像都是一个28x28的灰度图像。与CIFAR-10一样,这里也引入了两级层次结构。层次结构的根节点是时装。第一级包括上装、下装、配饰和鞋类。上衣有t恤、套头衫、连衣裙、外套和衬衫等。底裤和配饰有裤子和包作为子类。鞋类有凉鞋、运动鞋、踝靴等。
2.3.3 ETH昆虫学收藏数据集
ETHEC数据集项目
对于实验,我们使用ETH昆虫学收集中心(简称ETEC)提供的数据。该数据集与ETH图书馆的IMAGO项目相关联,是鳞翅目标本的广泛收集,这些标本经过精心整理,并用精确的元数据进行了数字化。
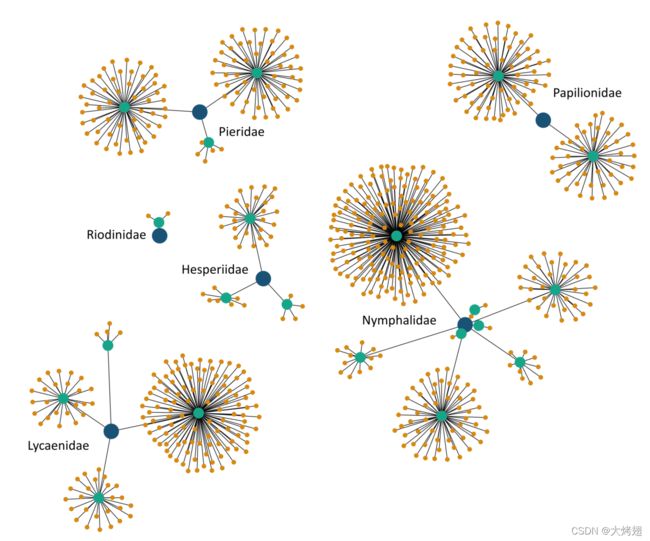
图2.1.来自ETEC(合并)数据集的标签层次结构。它由4个层次的标签组成:科(蓝色)、亚科(绿色)、属(棕色)和种。此可视化描述了前3个级别。科的名称将显示在其子树旁边。
存在来自197052个样本的元数据,所有样本的标签分布在不同的层次结构中。在我们的实验中,我们使用了4个这样的层级:25个科,91个亚科,842个属和2429个特定修饰语标签。各层级的平均分枝因子分别为25、3.64、9.25和2.88。标签层次结构有3537条边和3387个节点。
在层级结构中,最大数量的后代属于夜蛾科19、夜蛾亚科155和真古猿属79。大部分标本属于几何科48635(科)、夜蛾亚科29555(亚科)、魟魟魟属17243(属)和魟魟科2456(特指)。
由于与本文讨论的其他数据集相比,该数据集要大得多,为了更好地理解数据,我们使用JavaScript将数据集可视化为一个交互式图形。可视化具有查看节点之间关系、每个标签的样本数以及特定标签的层次结构级别的基本功能。节点的大小与该标签的样本数量的数量级成比例,并且根据其层次结构级别进行颜色编码。我们在图2.1中展示了ETEC数据集完整层次结构的一个子集。更具体地说,它是用于我们实验的子集。
ETHEC数据集的整理和合并
根据命名法的定义,与标本相关的特定修饰语(物种)名称可能不是唯一的。例如,带有以下标签的两个样本(Pieridae、Coliadinae、Colias、staudingeri)和(Lycaenidae、Polymmatinae、Cupido、staudingeri)具有相同的特定称谓,但在所有其他标签级别上有所不同——科、亚科和属。然而,该属和特定修饰语的结合是独一无二的。为了确保层次结构是树结构,每个节点都有一个唯一的父节点,我们定义了一个新的版本,其中有一个4级层次结构——科(6)、亚科(21)、属(135)和属+特定的修饰语(561),共有723个标签。我们将这个版本的ETEC数据集称为ETEC合并数据集。我们决定保持属的水平,因为根据该领域的专家,有关属的信息有助于区分样本,并产生性能更好的模型。在我们的实验中,我们使用数据集的合并版本来确保层次结构是一棵树。层次结构的前3个层次如图2.1所示。
ETHEC小型数据集
为了允许调试和检查算法,我们还使用了原始ETEC数据集的较小子集,称为ETEC小数据集。表2.1列举了ETEC小型数据集层次结构中4个级别的所有标签。
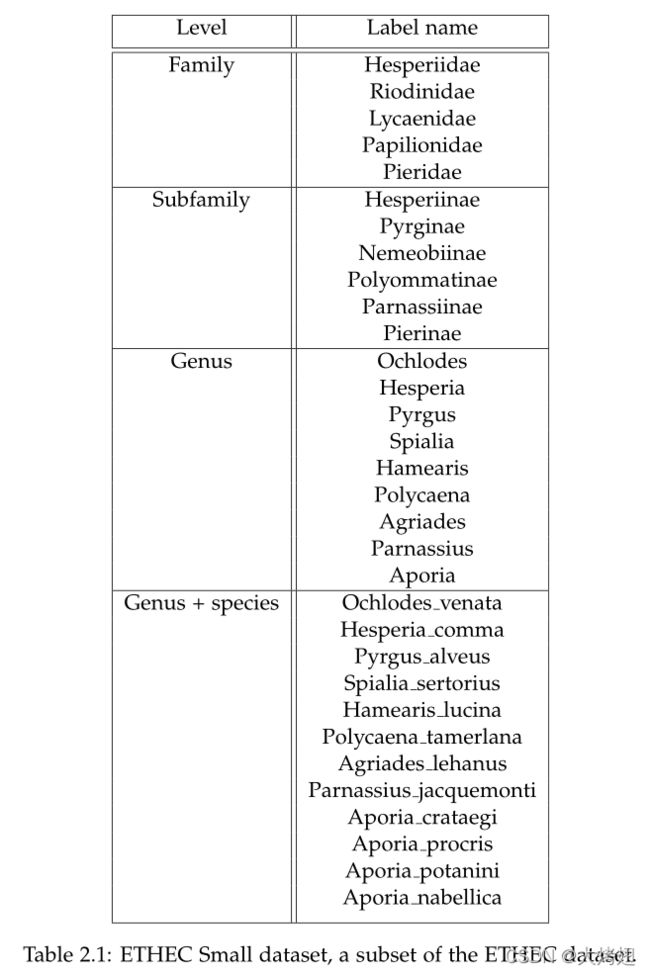
表2.1.ETHEC小型数据集,它是ETHEC数据集的一个子集
2.4 CNN主干网络
我们使用卷积神经网络从图像中提取视觉特征进行分类。基于CNN的模型使用SGD[4]进行优化,100个epoch的学习率为0.01,batch size为64,除非另有规定。
2.4.1 AlexNet
AlexNet[23]在2012年的ImageNet[9]挑战赛中表现出色,一举成名。它总共由8层组成:前5层为卷积层,其余3层为完全连接层。最初的体系结构输出了ImageNet挑战[9]中1000个类别标签的logits信息。
2.4.2 VGG
VGGNet[36]由16个卷积层组成,有1.38亿个参数,比AlexNet[23]大得多。他们提出使用更小的卷积核(3x3),而不是之前CNN中更大的核。这减少了获得相同感受野的有效参数数量,此外还包含了多个非线性。
2.4.3 Resnet
ResNet[18]表明,增加深度可以提高网络性能。它们在卷积层的组之间引入跳过连接,允许模型学习identity函数,从而确保性能与较浅网络的性能一样好。这有助于比普通网络更快的收敛速度。与原始网络(无跳过连接)相比,跳过连接或快捷连接不会增加参数的数量。即使深度显著增加,ResNet-152(152层)的参数也少于VGG-16/19[36]。Resnet(在ImageNet数据集上预先训练)是图像相关任务的常用特征提取器。