详解ResNet残差网络
代码实现:https://blog.csdn.net/dgvv4/article/details/122396424
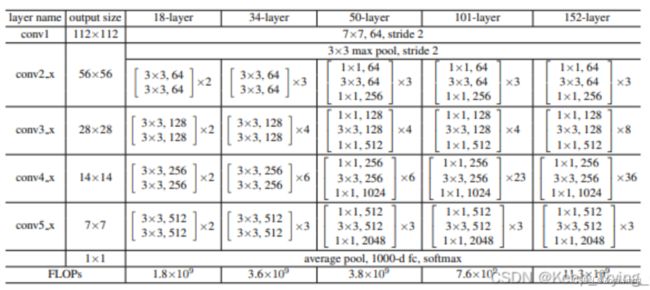
在VGG中,卷积网络达到了19层,在GoogLeNet中,网络史无前例的达到了22层。那么,网络的精度会随着网络的层数增多而增多吗?在深度学习中,网络层数增多一般会伴着下面几个问题
- 计算资源的消耗
- 模型容易过拟合
- 梯度消失/梯度爆炸问题的产生
问题1可以通过GPU集群来解决,对于一个企业资源并不是很大的问题;问题2的过拟合通过采集海量数据,并配合Dropout正则化等方法也可以有效避免[4];问题3通过Batch Normalization也可以避免。貌似我们只要无脑的增加网络的层数,我们就能从此获益,但实验数据给了我们当头一棒。
作者发现,随着网络层数的增加,网络发生了退化(degradation)的现象:随着网络层数的增多,训练集loss逐渐下降,然后趋于饱和,当你再增加网络深度的话,训练集loss反而会增大。注意这并不是过拟合,因为在过拟合中训练loss是一直减小的。
当网络退化时,浅层网络能够达到比深层网络更好的训练效果,这时如果我们把低层的特征传到高层,那么效果应该至少不比浅层的网络效果差,或者说如果一个VGG-100网络在第98层使用的是和VGG-16第14层一模一样的特征,那么VGG-100的效果应该会和VGG-16的效果相同。所以,我们可以在VGG-100的98层和14层之间添加一条直接映射(Identity Mapping)来达到此效果。
从信息论的角度讲,由于DPI(数据处理不等式)的存在,在前向传输的过程中,随着层数的加深,Feature Map包含的图像信息会逐层减少,而ResNet的直接映射的加入,保证了 层的网络一定比 层包含更多的图像信息。
基于这种使用直接映射来连接网络不同层直接的思想,残差网络应运而生。
1. 残差网络
1.1 残差块
残差网络是由一系列残差块组成的(图1)。一个残差块可以用表示为:

残差块分成直接映射部分和残差部分。 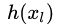 是直接映射,反应在图1中是左边的曲线;
是直接映射,反应在图1中是左边的曲线; 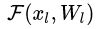 是残差部分,一般由两个或者三个卷积操作构成,即图1中右侧包含卷积的部分。
是残差部分,一般由两个或者三个卷积操作构成,即图1中右侧包含卷积的部分。
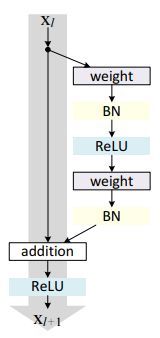
图1:残差块(Weight在卷积网络中是指卷积操作,addition是指单位加操作)
在卷积网络中,  可能和
可能和  的Feature Map的数量不一样,这时候就需要使用
的Feature Map的数量不一样,这时候就需要使用 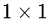 卷积进行升维或者降维(图2)。这时,残差块表示为:
卷积进行升维或者降维(图2)。这时,残差块表示为:
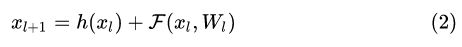
其中 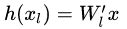 。其中
。其中  是
是 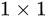 卷积操作,但是实验结果
卷积操作,但是实验结果 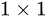 卷积对模型性能提升有限,所以一般是在升维或者降维时才会使用。
卷积对模型性能提升有限,所以一般是在升维或者降维时才会使用。

图2:1*1残差块
1.2 残差网络
残差网络的搭建分为两步:
- 使用VGG公式搭建Plain VGG网络
- 在Plain VGG的卷积网络之间插入Identity Mapping,注意需要升维或者降维的时候加入
 卷积。
卷积。
1.3 为什么叫残差网络
在统计学中,残差和误差是非常容易混淆的两个概念。误差是衡量观测值和真实值之间的差距,残差是指预测值和观测值之间的差距。对于残差网络的命名原因,作者给出的解释是,网络的一层通常可以看做 , 而残差网络的一个残差块可以表示为 ,也就是 ,在单位映射中, 便是观测值,而 是预测值,所以 便对应着残差,因此叫做残差网络。
2. 残差网络的背后原理
残差块一个更通用的表示方式是
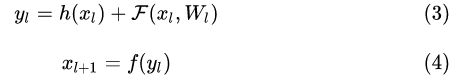
现在我们先不考虑升维或者降维的情况,那么在[1]中, 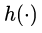 是直接映射,
是直接映射, 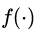 是激活函数,一般使用ReLU。我们首先给出两个假设:
是激活函数,一般使用ReLU。我们首先给出两个假设:
- 假设1:
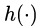 是直接映射;
是直接映射; - 假设2:
 是直接映射。
是直接映射。
那么这时候残差块可以表示为:

对于一个更深的层 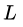 ,其与
,其与 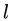 层的关系可以表示为
层的关系可以表示为

这个公式反应了残差网络的两个属性:
 层可以表示为任意一个比它浅的l层和他们之间的残差部分之和;
层可以表示为任意一个比它浅的l层和他们之间的残差部分之和; ,
,  是各个残差块特征的单位累和,而MLP是特征矩阵的累积。
是各个残差块特征的单位累和,而MLP是特征矩阵的累积。
根据BP中使用的导数的链式法则,损失函数  关于
关于  的梯度可以表示为
的梯度可以表示为

上面公式反映了残差网络的两个属性:
- 在整个训练过程中,
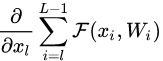 不可能一直为
不可能一直为  ,也就是说在残差网络中不会出现梯度消失的问题。
,也就是说在残差网络中不会出现梯度消失的问题。  表示
表示 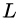 层的梯度可以直接传递到任何一个比它浅的
层的梯度可以直接传递到任何一个比它浅的  层。
层。
通过分析残差网络的正向和反向两个过程,我们发现,当残差块满足上面两个假设时,信息可以非常畅通的在高层和低层之间相互传导,说明这两个假设是让残差网络可以训练深度模型的充分条件。那么这两个假设是必要条件吗?
2.1 直接映射是最好的选择
对于假设1,我们采用反证法,假设  ,那么这时候,残差块(图3.b)表示为
,那么这时候,残差块(图3.b)表示为

对于更深的L层
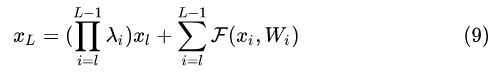
为了简化问题,我们只考虑公式的左半部分  ,损失函数
,损失函数  对
对 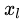 求偏微分得
求偏微分得

上面公式反映了两个属性:
- 当
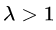 时,很有可能发生梯度爆炸;
时,很有可能发生梯度爆炸; - 当
 时,梯度变成0,会阻碍残差网络信息的反向传递,从而影响残差网络的训练。
时,梯度变成0,会阻碍残差网络信息的反向传递,从而影响残差网络的训练。
所以 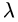 必须等1。同理,其他常见的激活函数都会产生和上面的例子类似的阻碍信息反向传播的问题。
必须等1。同理,其他常见的激活函数都会产生和上面的例子类似的阻碍信息反向传播的问题。
对于其它不影响梯度的 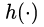 ,例如LSTM中的门机制(图3.c,图3.d)或者Dropout(图3.f)以及[1]中用于降维的
,例如LSTM中的门机制(图3.c,图3.d)或者Dropout(图3.f)以及[1]中用于降维的  卷积(图3.e)也许会有效果,作者采用了实验的方法进行验证,实验结果见图4
卷积(图3.e)也许会有效果,作者采用了实验的方法进行验证,实验结果见图4
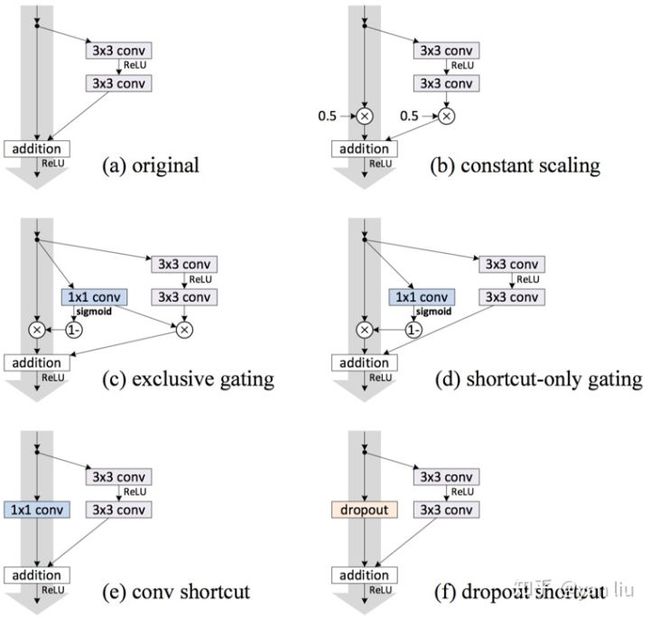
图3:直接映射的变异模型
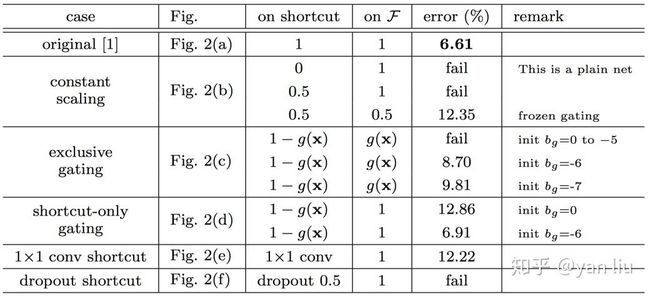
图4:变异模型(均为110层)在Cifar10数据集上的表现
从图4的实验结果中我们可以看出,在所有的变异模型中,依旧是直接映射的效果最好。下面我们对图3中的各种变异模型的分析
- Exclusive Gating:在LSTM的门机制中,绝大多数门的值为0或者1,几乎很难落到0.5附近。当
 时,残差块变成只有直接映射组成,阻碍卷积部分特征的传播;当
时,残差块变成只有直接映射组成,阻碍卷积部分特征的传播;当  时,直接映射失效,退化为普通的卷积网络;
时,直接映射失效,退化为普通的卷积网络; - Short-cut only gating:
 时,此时网络便是[1]提出的直接映射的残差网络; 时,退化为普通卷积网络;
时,此时网络便是[1]提出的直接映射的残差网络; 时,退化为普通卷积网络; - Dropout:类似于将直接映射乘以
 ,所以会影响梯度的反向传播;
,所以会影响梯度的反向传播;  conv:
conv:  卷积比直接映射拥有更强的表示能力,但是实验效果却不如直接映射,说明该问题更可能是优化问题而非模型容量问题。
卷积比直接映射拥有更强的表示能力,但是实验效果却不如直接映射,说明该问题更可能是优化问题而非模型容量问题。
所以我们可以得出结论:假设1成立,即

2.2 激活函数的位置
[1] 提出的残差块可以详细展开如图5.a,即在卷积之后使用了BN做归一化,然后在和直接映射单位加之后使用了ReLU作为激活函数。
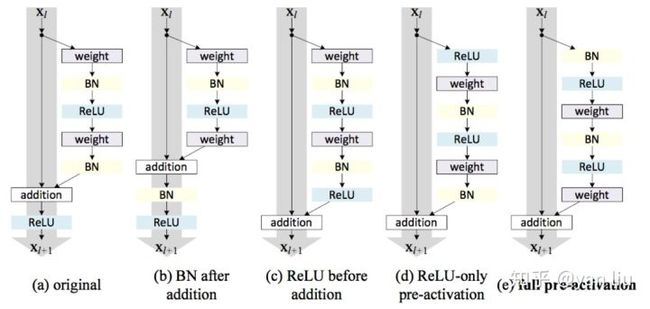
图5:激活函数在残差网络中的使用
在2.1节中,我们得出假设“直接映射是最好的选择”,所以我们希望构造一种结构能够满足直接映射,即定义一个新的残差结构 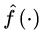 :
:

上面公式反应到网络里即将激活函数移到残差部分使用,即图5.c,这种在卷积之后使用激活函数的方法叫做post-activation。然后,作者通过调整ReLU和BN的使用位置得到了几个变种,即5.d中的ReLU-only pre-activation和5.d中的 full pre-activation。作者通过对照试验对比了这几种变异模型,结果见图6。
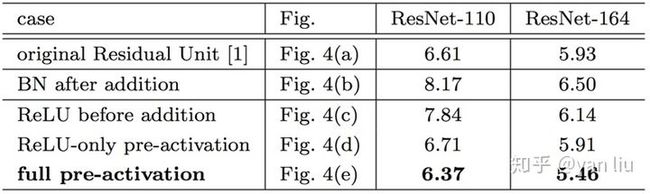
图6:基于激活函数位置的变异模型在Cifar10上的实验结果
而实验结果也表明将激活函数移动到残差部分可以提高模型的精度。
3.残差网络与模型集成
Andreas Veit等人的论文[3]指出残差网络可以从模型集成的角度理解。如图7所示,对于一个3层的残差网络可以展开成一棵含有8个节点的二叉树,而最终的输出便是这8个节点的集成。而他们的实验也验证了这一点,随机删除残差网络的一些节点网络的性能变化较为平滑,而对于VGG等stack到一起的网络来说,随机删除一些节点后,网络的输出将完全随机。
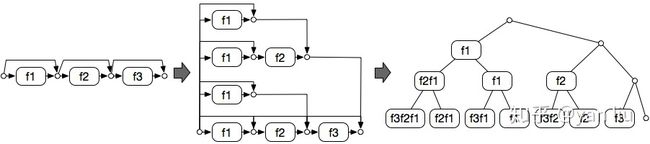
图7:残差网络展开成二叉树
Reference
[1] He K, Zhang X, Ren S, et al. Deep residual learning for image recognition[C]//Proceedings of the IEEE conference on computer vision and pattern recognition. 2016: 770-778.
[2] He K, Zhang X, Ren S, et al. Identity mappings in deep residual networks[C]//European Conference on Computer Vision. Springer, Cham, 2016: 630-645.
[3] Veit A, Wilber M J, Belongie S. Residual networks behave like ensembles of relatively shallow networks[C]//Advances in Neural Information Processing Systems. 2016: 550-558.
[4]. Srivastava N, Hinton G, Krizhevsky A, et al. Dropout: a simple way to prevent neural networks from overfitting. In JMLR, 2014.
————————————————
版权声明:本文为CSDN博主「LifeBackwards」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/daodaipsrensheng/article/details/117249446