【论文解析】Anchor-Free Person Search
相关链接:
https://zhuanlan.zhihu.com/p/359617800
code:https://github.com/daodaofr/AlignPS
下方↓公众号后台回复“AFPS”,即可获得论文电子资源。

文章目录
- Abstract
- 01 Introduction
- 02 Related work
-
- Pedestrian Detection
- Person Re-identification
- Person Search
- 03 Feature-Aligned Person Search Networks
-
- 3.1 Framework Overview
- 3.2 Aligned Feature Aggregation
-
- Scale Alignment
- Region Alignment
- Task Alignment
- 3.3 Triplet-Aided Online Instance Matching Loss
- 04 Experiments
-
- 4.1 Datasets and Settings
- 4.2 Implementation Details
- 4.3 Analytical Results
-
- Baseline
- Scale Alignment
- Region Aligment
- Task Alignment
- TOIM Loss
- Deformable Conv in the backbone
- 4.4 Comparison to the SOTA
- 05 Conclusion
Abstract
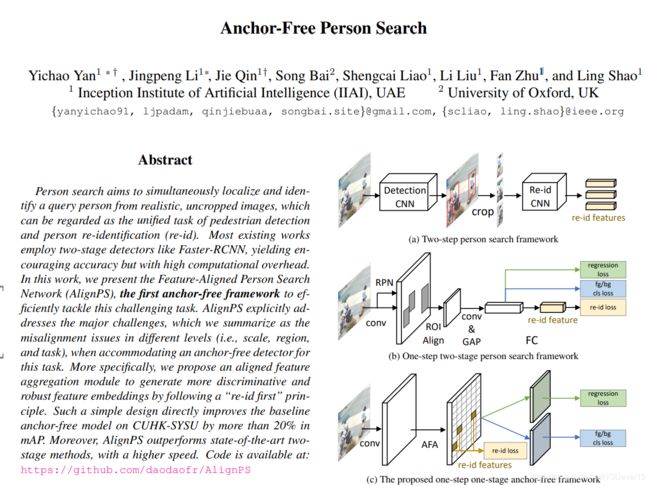
In this work, we present the Feature-Aligned Person Search Network (AlignPS)(特征对齐的行人搜索网络), the first anchor-free framework to ef ficiently tackle this challenging task.
- AlignPS explicitly ad- dresses the major challenges, which we summarize as the misalignment(不重合) issues in different levels (i.e., scale, region, and task), when accommodating an anchor-free detector for this task.
we propose an aligned feature aggregation module(对齐特征聚合模块) to generate more discriminative and robust feature embeddings by following a “re-id first” principle.
01 Introduction
person search[54, 47]: aims to localize and identify a target person from a gallery of realistic, uncropped scene images(在现实未裁剪的场景中定位和识别目标人物)。
两个基本的CV task:
- pedestrian detection [33, 51]
- person re-identification (re- id) [15, 1].
现有方法分类:
- two-step approaches: attempt to deal with detection and re-id separately。 (time- and resource-consuming)

- one-step solution:unifies detection and re-id in an end-to-end manner
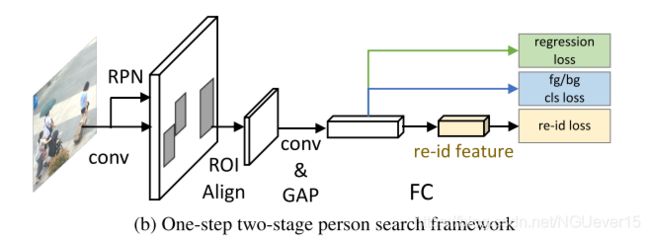
首先应用 ROI-Align layer 来聚合特征,这个特征将会用于检测和re-id。
with an additional re-id loss, the simultaneous optimization of the two tasks becomes feasible.
Since these models adopt two- stage detectors like Faster-RCNN [38], we refer to them as one-step two-stage models.
- However, these methods inevitably inherit the limitations of two-stage detectors, e.g., high computational complexity caused by dense anchors, and high sensitivity to the hyperparameters including the size, aspect ratio and number of anchor boxes, etc. (锚点密集导致计算复杂度高,对锚盒大小、纵横比、数量等超参数具有较高的敏感性)
Anchor-free 的优点:
(e.g., simpler structure and higher speed), and have been actively studied in recent years [36, 23, 29, 14].
develop an anchor-free framework for person search:
three mis- alignment issues:
-
- Many anchor-free models learn multi- scale features using feature pyramid networks (FPNs) [24] to achieve scale invariance for object detection. However, this introduces the misalignment issue for re-id (i.e., scale misalignment), as a query person needs to be compared with all the people of various scales in the gallery set.
-
- anchor-free models cannot align the features for re-id and detection according to a specific region. Therefore, re-id embeddings must be directly learned from feature maps without explicit region alignment.
-
- Person search can be intuitively formulated as a multi-task learning framework with detection and re- id as its sub-tasks. Hence, we need to find a better trade- off/alignment between the two tasks.
**In this work: **
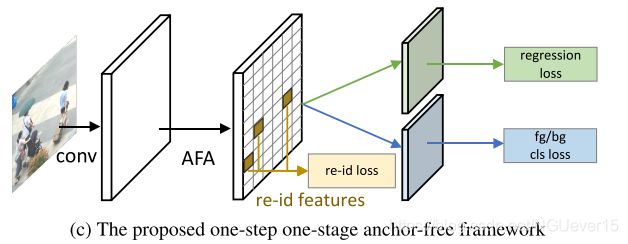
- we present the first anchor-free framework for efficient person search, which we name the Feature- Aligned Person Search Network (AlignPS).
- Our model em- ploys the typical architecture of anchor-free detection models,but with a carefully designed aligned feature aggregation (AFA) module(对齐特征聚合模块)
AFA reshapes some building blocks of FPN by exploiting the deformable convolution and feature fusion to overcome the issues of region and scale misalignment in re-id feature learning.
- We follow a “re-id first” principle to explicitly address the above-mentioned challenges.
Contributions:
- 提出了one-step one-stage framework for efficient person search.
- 设计了AFA模块 simultaneously ad- dresses the issues of scale, region, and task misalign- ment to successfully accommodate an anchor-free de- tector for the task of person search.(同时讨论了尺度、区域和任务错位的问题,以成功地适应无锚探测器的人员搜索任务。)
02 Related work
Pedestrian Detection
- Compared with the above models, one-stage anchor-free detectors [36, 23, 29, 56, 50, 42] have been attracting more and more attention recently due to their simple structures and efficient implementations.
- In this work, we develop our person search framework based on a classic one-stage anchor-free detector, thus making the whole framework simpler and faster.
Person Re-identification
re-id needs to focus more on fine- grained details and unique features of each identity. There- fore, we propose to follow the “re-id first” principle to raise the priority of the re-id task, resulting in more discriminative identity embeddings for more accurate person search.
Person Search
- In general, two-step mod- els may achieve better performance, while one-step models have the advantages of simplicity and efficiency. However, there is still room for improving one-step methods due to the aforementioned shortcomings of the two-stage anchor- based detectors they usually adopt.
- In this work, we in- troduce the first anchor-free model to further improve the simplicity and efficiency of one-step models, without any sacrifice in accuracy。
03 Feature-Aligned Person Search Networks
3.1 Framework Overview
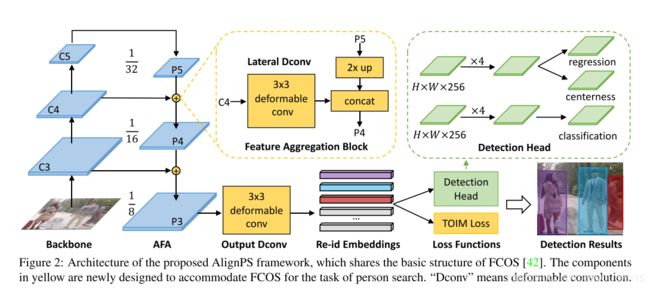
The basic framework of the proposed AlignPS is based on FCOS [42], one of the most popular one-stage anchor- free object detectors.
- our model simultaneously localizes multiple people in the image and learns re-id embed- dings for them.
- an AFA module is developed to aggregate features from multi-level feature maps in the backbone network
- we directly take the flattened features from the output feature maps of AFA as the final embed- dings, without any extra embedding layers.
- we employ the detection head from FCOS which is good enough for the detection subtask.
- Finally, each location on the output feature map of AFA will be associated with a bounding box with classification and centerness scores, as well as a re-id feature embedding.
3.2 Aligned Feature Aggregation
Scale Alignment
Therefore, in our framework, we only make predictions based on a single layer of AFA, which explicitly addresses the feature misalignment caused by scale variations.
- We only learn features from {P3}, which is the largest output feature map, for both the detection and re-id subtasks
- 尽管损失了性能,但是取得了检测和re-id之间的平衡。
Region Alignment
在AFA的输出特征图上,每个位置基于一个大的接受域从整个输入图像中感知信息。
(没有如Faster-RCNN,使用ROI-Align)it is dif- ficult for our anchor-free framework to learn more accu- rate features within the pedestrian bounding boxes, and thus leading to the issue of region misalignment.(因此导致了区域的不重合)
In AlignPS, we address this issue from three perspectives.(在没有bounding boxes的情况下,学习准确的特征表示)
- First, we replace the 1×1 conv layers in the lateral connections with 3×3 deformable conv layers.
- Second, we replace the “sum” operation in the top-down pathway with a “concatenation” operation, which can bet- ter aggregate multi-level features.
- Third, we again replace the 3×3 conv with a 3×3 deformable conv for the output layer of FPN, which further aligns the multi-level features to finally generate a more accurate feature map.
上述方法,很好地解决了区域对齐的问题。
Task Alignment
we opt for a different principle to align these two tasks by treating re-id as our primary task.
Specifically,
- the output features of AFA are directly supervised with a re-id loss (which will be introduced in the following subsection)。
This “re-id first” design is based on two considerations.
- learning discriminative re-id embeddings is our primary concern.
- Second, compared with “detection first” and parallel structures, the proposed “re-id first” struc- ture does not require an extra layer to generate re-id embed- dings, and is thus more efficient.(效率更高)
3.3 Triplet-Aided Online Instance Matching Loss
Specifically, OIM stores the feature centers of all labeled identities in a lookup table (LUT)

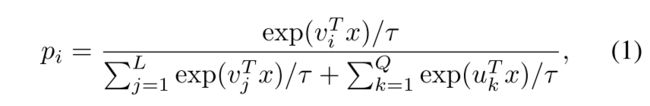
OIM loss:
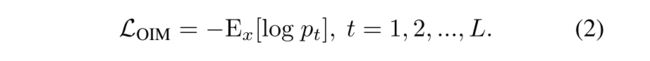
OIM有效地应用了带标注和无标注的样本
我们仍然发现了两个局限性。
- 只计算了输入特征和LUT和循环队列中存储的特征之间的距离。而没有对输入特征之间的距离进行计算。
- the log-likelihood loss term does not give an ex- plicit distance metric between feature pairs.(对数似然损失项没有给出特征对之间的显式距离度量。)
我们提出了triplet loss 来改进OIM损失。
- For each person in the input images, we employ the center sampling strategy as in [21].

- for each person, a set of features located around the person center are considered as positive samples. (对于每个人,位于人中心周围的一组特征被认为是阳性样本。)
- The objective is to pull the feature vectors from the same person close, and push the vectors from different people away.
- the features from the labeled persons should be close to the corresponding features stored in the LUT, and away from the other features in the LUT.
More specifically,

04 Experiments
4.1 Datasets and Settings
CUHK-SYSU [47] is a large-scale person search dataset which contains 18,184 images, with 8,432 different iden- tities and 96,143 annotated bounding boxes.
PRW [54] was captured using six static cameras in a university campus.
Evaluation Metric. We employ the mean average precision (mAP) and top-1 accuracy to evaluate the performance for person search.
4.2 Implementation Details
4.3 Analytical Results
Baseline

Scale Alignment
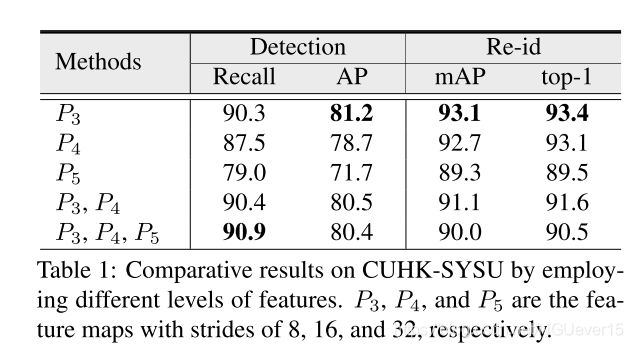
- As can be observed, features from the largest scale P3 yield the best performance,due to the fact that they absorb different levels of features from AFA, pro-viding richer information for detection and re-id.
Region Aligment

To further illustrate how the deformable convolutions work in our framework, we visualize the learned offsets of the deformable filters in Fig. 5.

Task Alignment
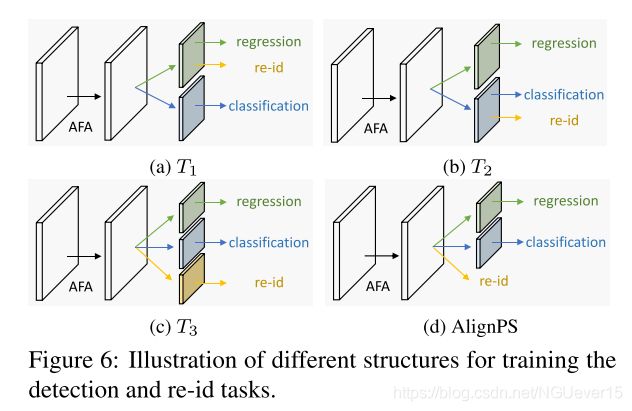
we design several structures to compare different training options (as shown in Fig. 6), the performance of which is summarized in Table 3.

TOIM Loss
We evaluate the performance of our framework when adopting different loss functions and report the results in Table 4.

Deformable Conv in the backbone
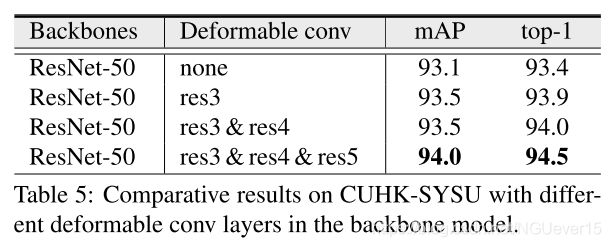
4.4 Comparison to the SOTA
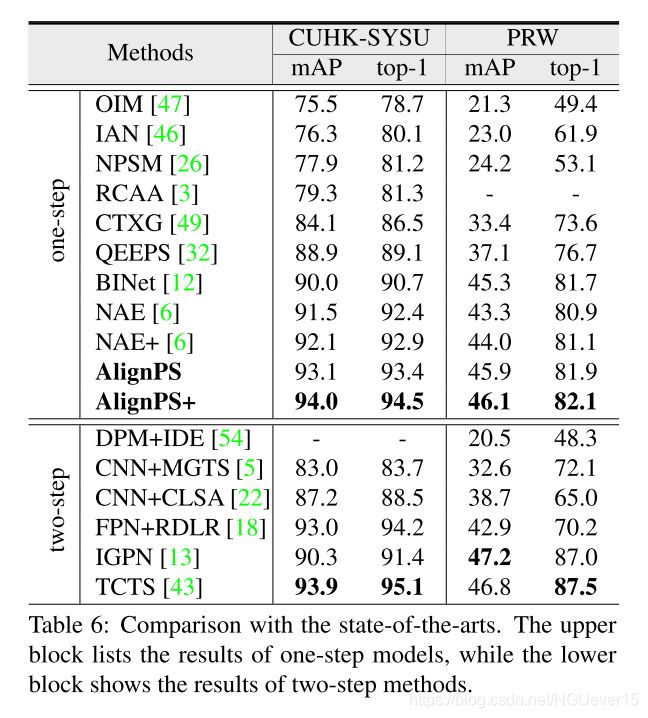
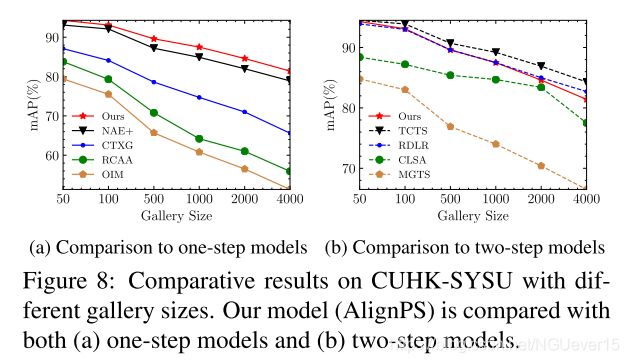


05 Conclusion
In this paper, we propose the first anchor-free model to simplify the framework for person search, where detection and re-id are jointly addressed by a one-step model. We also design the aligned feature aggregation module to ef- fectively address the scale, region, and task misalignment issues when accommodating an anchor-free detector for the person search task. Extensive experiments demonstrate that the proposed framework not only outperforms existing per- son search methods, but also runs at a higher speed.