【联邦学习】联邦学习算法分类总结
【联邦学习】联邦学习算法分类总结
- 横向联邦学习、纵向联邦学习和联邦迁移学习
-
- 横向联邦学习
- 纵向联邦学习
- 联邦迁移学习
- 基于机器学习算法的联邦学习分类
-
- 联邦线性算法
- 联邦树模型
- 联邦支持向量机
- 联邦深度学习
- 基于优化方法进行分类
-
- 从通信成本角度优化的联邦学习算法
-
- 增加客户端训练压力
- 模型压缩
- 从客户端选择入手的联邦学习算法
- 从异步聚合角度优化的联邦学习算法
联邦学习作为目前研究的热点,各种算法层出不穷,不管是纵向横向,还是什么FedAvg、FedProx,总之就是分类很乱,今天来系统总结一下联邦学习的分类方式以及对应的内容介绍。
横向联邦学习、纵向联邦学习和联邦迁移学习
我们都听过联邦学习分类方法中有:纵向横向和迁移,这是杨强大佬的分类方法,是根据样本重合程度来划分的。
横向联邦学习
机器学习中,特征、标签和样本是最基本的概念,下图展示了特征样本标签之间的关系
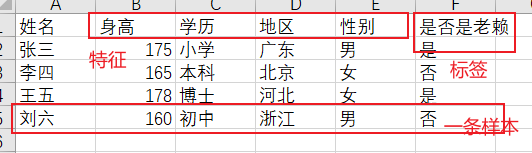
横向联邦学习,就是指两个样本集合中样本的特征重合较高,但是样本来源不一样。就比如图中,两个样本集合分别是两家银行的客户。一般银行管理的数据特征都是相似的,但是客户是不同的,这样我们就可以采用横向联邦学习的方式训练模型。
纵向联邦学习
纵向联邦学习是指两个数据集id重合较高(比如上图的姓名,都是一样的人),但是特征不一样,比如一座城市只有一家银行和一家医院,那么银行和医院的样本大概率人员重合度很高,但是特征不一样,银行数据集属性可能是存款、贷款等信息,医院可能是生理指标等。此时如果使用银行和医院的数据集训练模型,我们称之为纵向联邦学习。
联邦迁移学习
如果id和特征重合程度都很少怎么办?此时只能采用联邦迁移学习的办法。联邦迁移学习重点在“迁移学习”。迁移学习,是指利用数据、任务、或模型之间的相似性,将在源领域学习过的模型,应用于目标领域的一种学习过程。这里对迁移学习不做展开。
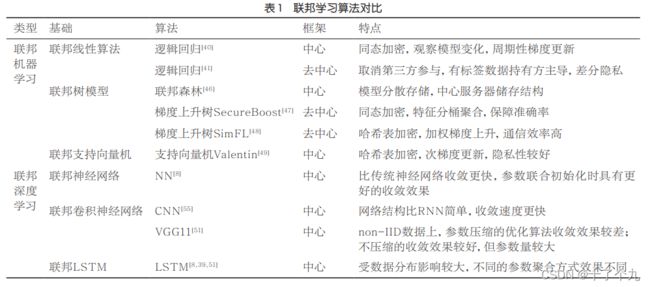
基于机器学习算法的联邦学习分类
常见的机器学习算法诸如回归、随机森林、支持向量机等,这些算法都可以用在联邦学习中。目前在联邦学习中已经研究的传统机器学习算法有以下几种
联邦线性算法
Yang K等人提出了一种中心联邦学习框架下的纵向联邦逻辑回归实现方法,这种方法实现了纵向联邦学习中的逻辑回归,其目标函数是:

论文传送门:https://arxiv.org/abs/1812.11750
联邦树模型
Liu Y等人提出了一种基于中心纵向联邦学习框架的随机森林实现方法——联邦森林。在建模过程中,每棵树都实行联合建模。
论文传送门:https://arxiv.org/abs/1905.10053
联邦支持向量机
Hartmann V等人提出了一种将支持向量机(support vector machine,SVM安全部署在联邦学习中的方法,主要通过特征哈希、更新分块等方式对数据隐私性进行保障。其目标函数如下:

论文传送门:https://arxiv.org/abs/1907.03373v1
联邦深度学习
深度学习诸如CNN、LSTM等也可以用联邦学习的方式来实现
基于优化方法进行分类
我们都知道,联邦学习的主要问题集中在一下三个方面
● 联邦学习的通信是比较慢速且不稳定的;
● 联邦学习的参与方设备异构,不同设备有不同的运算能力;
● 联邦学习更关注隐私和安全,目前大部分的研究假设参与方和服务器方是可信的,然而在现实生活中,其可能是不可信的。
通俗的讲就三点:通信、数据和设备异质以及加密保护。
那么,我们可以根据这三点来提出不同的联邦学习算法,以解决对应的问题,比如某种算法侧重于解决通信瓶颈问题,而另一种方法则侧重于解决加密问题。
最经典的联邦学习算法当属FedAvg(https://arxiv.org/pdf/1602.05629.pdf),该算法在Non-iid数据上的收敛性也得到了数学上的证明(https://arxiv.org/abs/1907.02189v3)。
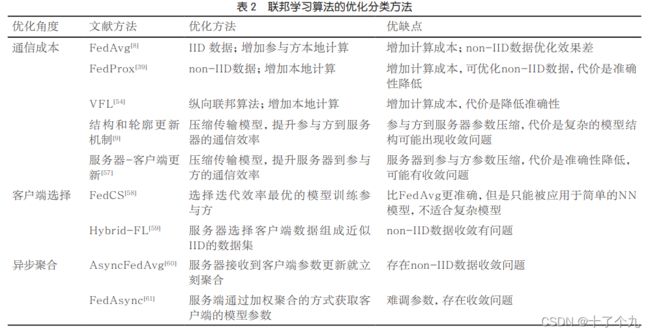
从通信成本角度优化的联邦学习算法
模型通常很大,如果频繁的通信势必会对通信造成压力,因此我们必须想办法减小通信压力,常用的方法有增加客户端训练轮数、模型压缩等。
增加客户端训练压力
在联邦学习体系中,有时终端节点只会在有Wi-Fi时参与联邦学习训练,或者有时网络状况不佳,在这些情况下,更多的计算可以在本地进行,从而减少通信的次数。很多算法是从这个角度来优化通信成本的。比如Konečný J考虑了优化FedAvg算法,增加每一轮迭代在每个客户端的本地更新参数的计算次数。
论文传送门:https://arxiv.org/abs/1707.01155
Sahu A K等人提出了一种更通用的FedProx算法,这种算法在数据为non-IID时优化效果更明显。FedProx算法可以动态地更新不同客户端每一轮需要本地计算的次数,使得算法更适合非独立同分布的联合建模场景。
论文传送门:https://openreview.net/pdf?id=SkgwE5Ss3N
模型压缩
有的优化算法目的是减少每一轮通信的参数量,例如通过模型压缩的技术(比如量化、二次抽样的方式)来减少每一次参数更新要传递的参数总量。Konečný J等人提出了一种结构化的模型更新方式来更新服务器参数,在每一轮的参数通信过程中,减小参与方传递给服务器的模型更新参数的大小,从而减少通信。
论文传送门:https://arxiv.org/abs/1610.05492v2
Caldas S等人考虑的是从服务器到参 与 方的模型参 数传 递优化,通 过有损压缩以及联邦参数筛选(federated dropout)的方式来减少从服务器到客户端需要传递的参数数量,降低通信成本的代价是在一定程度上降低模型的准确率。
论文传送门:https://arxiv.org/abs/1812.07210
从客户端选择入手的联邦学习算法
不同的客户端的网络速度、运算能力等不同,每个客户端拥有的数据分布也是不平衡的,如果让所有的客户端都参与联邦学习的训练过程,将会有迭代落后的参与方出现,某些客户端长时间没有响应可能会导致整个系统无法完成联合训练。因此,需要考虑如何选择参与训练的客户端。
最经典的FedAvg算法中客户端的选择是随机的。随机选择嘛emmmm很显然不是很合理,毕竟设备跟设备之间差异太大。
Nishio T等人提出了一种FedCS算法,设计了一种贪心算法的协议机制,以达到在联合训练的每一次更新中都选择模型迭代效率最高的客户端进行聚合更新的目的,从而优化整个联邦学习算法的收敛效率。
论文传送门:https://arxiv.org/abs/1804.08333
Yoshida N等人[59]提出了一种HybridFL的协议算法,该协议可以处理数据集为non-IID的客户端数据,解决基于non-IID数据在FedAvg算法上性能不好的问题。Hybrid-FL协议使得服务器通过资源请求
的步骤来选择部分客户端,从而在本地建立一种近似独立同分布的数据集用于联邦学习的训练和迭
代。
论文传送门:https://arxiv.org/abs/1905.07210
从异步聚合角度优化的联邦学习算法
我们都知道,在FedAvg的算法中,聚合是与模型的更新保持同步的。每一次更新,服务器都同步聚合模型参数,然后将聚合参数发送给每一个客户端。在同步聚合中,服务器需要在接收到所有参与训练的客户端的参数之后才可以开始聚合,但是有的客户端运算传输快,有的客户端运算传输慢,为了避免出现通信迟滞现象,有研究者考虑用异步的方式进行聚合,从而优化联邦学习算法。
论文传送门:Asynchronous Federated Optimization