手写分类决策树(鸢尾花数据集)
目录
-
- 1.实验简介及数据集
- 2.算法分析
- 3.具体实现
-
- 3.1 数据结构
- 3.2 如何产生分支
-
- 3.2.1 增益
- 3.2.2 寻找某一属性的阈值
- 3.2.3 寻找最优属性及其阈值
- 3.3 建立决策树
- 3.4 预测
- 3.5 整体代码
- 4.实验结果
- 5.实验总结
1.实验简介及数据集
本次实验需要实现一个简单的分类决策树并在鸢尾花数据集上进行预测。鸢尾花数据集中共有150个样本,包含四个属性,值都是连续的,共有三种类别。
2.算法分析
使用分类决策树进行预测可以分为两个部分。
第一部分是建立一棵决策树,在该部分我们需要判断在每个节点使用哪个属性的来划分左右子节点,并将信息储存在当前节点中,这里我们通过使划分后的“增益”最大来选择划分属性。在叶子节点,需要给出到达这个节点的数据的类别,以实现预测的功能。
第二部分就是进行预测了,将数据输入决策树,通过储存在节点中的信息判断当前的数据怎么走,最终到达的叶子节点给出的类别就是该数据的预测值。
3.具体实现
3.1 数据结构
对于决策树的数据结构定义,通过DecisionNode类来实现:
由于鸢尾花数据集的属性值是连续的,所以我们找到一个阈值来将数据划分位两个分支。
class DecisionNode(object):
def __init__(self, f_idx, threshold, value=None, L=None, R=None):
self.f_idx = f_idx # 属性的下标,表示通过下标为f_idx的属性来划分样本
self.threshold = threshold # 下标 `f_idx` 对应属性的阈值
self.value = value # 如果该节点是叶子节点,对应的是被划分到这个节点的数据的类别
self.L = L # 左子树
self.R = R # 右子树
3.2 如何产生分支
在数据通过一个节点时,如何将数据进行划分呢?这是决策树的关键,这里分三小节介绍。
3.2.1 增益
我们希望决策树分支节点所包含的样本尽可能属于同一类别,即节点的纯度越高越好。“增益”就可以表示出划分后纯度的提升程度,增益越高,效果也就越好。这里的“增益”可以选择信息增益、信息增益率或基尼系数。
下面给出三种增益计算的方法:
def calculate_entropy(dataset: np.ndarray): # 熵
scale = dataset.shape[0] # 多少条数据
d = {}
for data in dataset:
key = data[-1]
if key in d:
d[key] += 1
else:
d[key] = 1
entropy = 0.0
for key in d.keys():
p = d[key] / scale
entropy -= p * math.log(p, 2)
return entropy
def calculate_gain(dataset, l, r):
e1 = calculate_entropy(dataset)
e2 = len(l) / len(dataset) * calculate_entropy(l) + len(r) / len(dataset) * calculate_entropy(r)
gain = e1 - e2
return gain
def calculate_gain_ratio(dataset, l, r):
gain = calculate_gain(dataset, l, r)
p1 = len(l) / len(dataset)
p2 = len(r) / len(dataset)
# 会出现 1/0 的情况 全被划分到一边 s=0
# print("len", len(l), len(r), p1, p2)
if p1 == 0:
s = p2 * math.log(p2, 2)
elif p2 == 0:
s = p1 * math.log(p1, 2)
else:
s = - p1 * math.log(p1, 2) - p2 * math.log(p2, 2)
gain_ratio = gain / s
return gain_ratio
def calculate_gini(dataset: np.ndarray):
scale = dataset.shape[0] # 多少条数据
d = {}
for data in dataset:
key = data[-1]
if key in d:
d[key] += 1
else:
d[key] = 1
gini = 1.0
for key in d.keys():
p = d[key] / scale
gini -= p * p
return gini
def calculate_gini_index(dataset, l, r):
gini_index = len(l) / len(dataset) * calculate_gini(l) + len(r) / len(dataset) * calculate_gini(r)
return gini_index
3.2.2 寻找某一属性的阈值
有了计算增益的方法后,我们就可以计算某一属性的阈值了,按照该属性的阈值将样本划分为两个分支,小于阈值的划分到左子树,大于阈值的划分到右子树。
求阈值的具体步骤:
- 将该属性的值进行排序并去重
- 取相邻两个数据的均值作为候选阈值
- 遍历候选阈值,对于每一个值:
将数据划分为小于该候选阈值和大于该候选阈值的
计算划分后的增益 - 选择使增益最大的候选阈值作为该属性的阈值
实现代码如下(给出了三种实现”增益“的方式,用split_choice来表示):
def find_best_threshold(dataset: np.ndarray, f_idx: int, split_choice: str): # dataset:numpy.ndarray (n,m+1) x<-[x,y] f_idx:feature index
best_gain = -math.inf # 先设置 best_gain 为无穷小
best_gini = math.inf
best_threshold = None
dataset_sorted = sorted(list(set(dataset[:, f_idx].reshape(-1)))) # 去重
candidate = [] # 候选值
for i in range(len(dataset_sorted) - 1):
candidate.append(round((dataset_sorted[i] + dataset_sorted[i + 1]) / 2.0, 2))
for threshold in candidate:
L, R = split_dataset(dataset, f_idx, threshold) # 根据阈值分割数据集,小于阈值
gain = None
if split_choice == "gain":
gain = calculate_gain(dataset, L, R) # 根据数据集和分割之后的数
if gain > best_gain: # 如果增益大于最大增益,则更换最大增益和最大阈值
best_gain = gain
best_threshold = threshold
if split_choice == "gain_ratio":
gain = calculate_gain_ratio(dataset, L, R)
if gain > best_gain: # 如果增益大于最大增益,则更换最大增益和最大阈值
best_gain = gain
best_threshold = threshold
if split_choice == "gini":
gini = calculate_gini_index(dataset, L, R)
if gini < best_gini: # gini指数越小越好
best_gini = gini
best_threshold = threshold
return best_threshold, best_gain
其中split_dataset函数(将数据划分为左右两子树)如下:
def split_dataset(X: np.ndarray, f_idx: int, threshold: float):
# L = []
# R = []
# for (idx, d) in enumerate(X[:, f_idx]): # idx:索引, d:值
# if d < threshold:
# L.append(idx)
# else:
# R.append(idx)
# return X[L], X[R]
L = X[:, f_idx] < threshold
R = ~L
return X[L], X[R]
3.2.3 寻找最优属性及其阈值
有了上述基础后,就可以遍历所有的属性,选择使增益最大的属性作为最优属性。这里我们用f_idx_list这个列表存放属性的下标值(0、1、2、3)。注意,用过的属性在接下来不能继续再用了,需要将其从f_idx_list中去除。
best_gain = -math.inf
best_gini = math.inf
best_threshold = None
best_f_idx = None
for i in f_idx_list:
threshold, gain = find_best_threshold(dataset, i, split_choice)
if split_choice == "gini":
if gain < best_gini:
best_gini = gain
best_threshold = threshold
best_f_idx = i
if split_choice == "gain" or split_choice == "gain_ratio" :
if gain > best_gain: # 如果增益大于最大增益,则更换最大增益和最大
best_gain = gain
best_threshold = threshold
best_f_idx = i
son_f_idx_list = f_idx_list.copy()
son_f_idx_list.remove(best_f_idx)
至此,我们就得到了进行划分的最优属性(下标)及其阈值了。
3.3 建立决策树
我们通过递归来建立决策树(对于递归不太了解的朋友可以去了解一下递归的基本思想,再来看建树过程就会清晰很多了)
首先,给出递归结束的条件:
1. 当前所有数据具有相同的类别标签,类别自然就标记为该类别,并返回叶子节点。
2. 进行划分选择的属性都用完了,类别标记为当先数据中最多的类,并返回叶子节点。
不满足上述结束条件时,创建分支
def build_tree(dataset: np.ndarray, f_idx_list: list, split_choice: str): # return DecisionNode 递归
class_list = [data[-1] for data in dataset] # 类别
# 全属于同一类别
if class_list.count(class_list[0]) == len(class_list):
return DecisionNode(None, None, value=class_list[0])
# 若属性都用完, 标记为类别最多的那一类
elif len(f_idx_list) == 0:
value = collections.Counter(class_list).most_common(1)[0][0]
return DecisionNode(None, None, value=value)
else:
# 找到划分 增益最大的属性 4个属性
best_gain = -math.inf
best_gini = math.inf
best_threshold = None
best_f_idx = None
for i in f_idx_list:
threshold, gain = find_best_threshold(dataset, i, split_choice)
if split_choice == "gini":
if gain < best_gini:
best_gini = gain
best_threshold = threshold
best_f_idx = i
if split_choice == "gain" or split_choice == "gain_ratio" :
if gain > best_gain: # 如果增益大于最大增益,则更换最大增益和最大
best_gain = gain
best_threshold = threshold
best_f_idx = i
son_f_idx_list = f_idx_list.copy()
son_f_idx_list.remove(best_f_idx)
# 创建分支
L, R = split_dataset(dataset, best_f_idx, best_threshold)
if len(L) == 0:
L_tree = DecisionNode(None, None, majority_count(dataset)) # 叶子节点
else:
L_tree = build_tree(L, son_f_idx_list, split_choice) # return DecisionNode
if len(R) == 0:
R_tree = DecisionNode(None, None, majority_count(dataset)) # 叶子节点
else:
R_tree = build_tree(R, son_f_idx_list, split_choice) # return DecisionNode
return DecisionNode(best_f_idx, best_threshold, value=None, L=L_tree, R=R_tree)
3.4 预测
这里对一条数据进行预测(传入模型与数据),同样是采用递归的方法:
def predict_one(model: DecisionNode, data):
if model.value is not None:
return model.value
else:
feature_one = data[model.f_idx]
branch = None
if feature_one >= model.threshold:
branch = model.R # 走右边
else:
branch = model.L # 走左边
return predict_one(branch, data)
3.5 整体代码
import math
import numpy
import numpy as np
from typing import Union
import collections
from sklearn.model_selection import train_test_split
from sklearn import tree
from sklearn.tree import DecisionTreeClassifier # 导入决策树DTC包
from sklearn.datasets import load_iris # 导入方法类
class DecisionNode(object):
def __init__(self, f_idx, threshold, value=None, L=None, R=None):
self.f_idx = f_idx # 属性的下标,表示通过下标为f_idx的属性来划分样本
self.threshold = threshold # 下标 `f_idx` 对应属性的阈值
self.value = value # 如果该节点是叶子节点,对应的是被划分到这个节点的数据的类别
self.L = L # 左子树
self.R = R # 右子树
def find_best_threshold(dataset: np.ndarray, f_idx: int, split_choice: str): # dataset:numpy.ndarray (n,m+1) x<-[x,y] f_idx:feature index
best_gain = -math.inf # 先设置 best_gain 为无穷小
best_gini = math.inf
best_threshold = None
dataset_sorted = sorted(list(set(dataset[:, f_idx].reshape(-1)))) # 去重
candidate = [] # 候选值
for i in range(len(dataset_sorted) - 1):
candidate.append(round((dataset_sorted[i] + dataset_sorted[i + 1]) / 2.0, 2))
for threshold in candidate:
L, R = split_dataset(dataset, f_idx, threshold) # 根据阈值分割数据集,小于阈值
gain = None
if split_choice == "gain":
gain = calculate_gain(dataset, L, R) # 根据数据集和分割之后的数
if gain > best_gain: # 如果增益大于最大增益,则更换最大增益和最大阈值
best_gain = gain
best_threshold = threshold
if split_choice == "gain_ratio":
gain = calculate_gain_ratio(dataset, L, R)
if gain > best_gain: # 如果增益大于最大增益,则更换最大增益和最大阈值
best_gain = gain
best_threshold = threshold
if split_choice == "gini":
gini = calculate_gini_index(dataset, L, R)
if gini < best_gini: # gini指数越小越好
best_gini = gini
best_threshold = threshold
return best_threshold, best_gain
def calculate_entropy(dataset: np.ndarray): # 熵
scale = dataset.shape[0] # 多少条数据
d = {}
for data in dataset:
key = data[-1]
if key in d:
d[key] += 1
else:
d[key] = 1
entropy = 0.0
for key in d.keys():
p = d[key] / scale
entropy -= p * math.log(p, 2)
return entropy
def calculate_gain(dataset, l, r):
e1 = calculate_entropy(dataset)
e2 = len(l) / len(dataset) * calculate_entropy(l) + len(r) / len(dataset) * calculate_entropy(r)
gain = e1 - e2
return gain
def calculate_gain_ratio(dataset, l, r):
gain = calculate_gain(dataset, l, r)
p1 = len(l) / len(dataset)
p2 = len(r) / len(dataset)
# 会出现 1/0 的情况 全被划分到一边 s=0
# print("len", len(l), len(r), p1, p2)
if p1 == 0:
s = p2 * math.log(p2, 2)
elif p2 == 0:
s = p1 * math.log(p1, 2)
else:
s = - p1 * math.log(p1, 2) - p2 * math.log(p2, 2)
# print(s)
# if s == 0:
# gain_ratio = math.inf
# else:
# gain_ratio = gain / s
gain_ratio = gain / s
return gain_ratio
def calculate_gini(dataset: np.ndarray):
scale = dataset.shape[0] # 多少条数据
d = {}
for data in dataset:
key = data[-1]
if key in d:
d[key] += 1
else:
d[key] = 1
gini = 1.0
for key in d.keys():
p = d[key] / scale
gini -= p * p
return gini
def calculate_gini_index(dataset, l, r):
gini_index = len(l) / len(dataset) * calculate_gini(l) + len(r) / len(dataset) * calculate_gini(r)
return gini_index
def split_dataset(X: np.ndarray, f_idx: int, threshold: float):
# L = []
# R = []
# for (idx, d) in enumerate(X[:, f_idx]): # idx:索引, d:值
# if d < threshold:
# L.append(idx)
# else:
# R.append(idx)
# return X[L], X[R]
L = X[:, f_idx] < threshold
R = ~L
return X[L], X[R]
def majority_count(dataset):
class_list = [data[-1] for data in dataset]
return collections.Counter(class_list).most_common(1)[0][0]
def build_tree(dataset: np.ndarray, f_idx_list: list, split_choice: str): # return DecisionNode 递归
class_list = [data[-1] for data in dataset] # 类别
# 全属于同一类别
if class_list.count(class_list[0]) == len(class_list):
return DecisionNode(None, None, value=class_list[0])
# 若属性都用完, 标记为类别最多的那一类
elif len(f_idx_list) == 0:
value = collections.Counter(class_list).most_common(1)[0][0]
return DecisionNode(None, None, value=value)
else:
# 找到划分 增益最大的属性 4个属性
best_gain = -math.inf
best_gini = math.inf
best_threshold = None
best_f_idx = None
for i in f_idx_list:
threshold, gain = find_best_threshold(dataset, i, split_choice)
if split_choice == "gini":
if gain < best_gini:
best_gini = gain
best_threshold = threshold
best_f_idx = i
if split_choice == "gain" or split_choice == "gain_ratio" :
if gain > best_gain: # 如果增益大于最大增益,则更换最大增益和最大
best_gain = gain
best_threshold = threshold
best_f_idx = i
son_f_idx_list = f_idx_list.copy()
son_f_idx_list.remove(best_f_idx)
# 创建分支
L, R = split_dataset(dataset, best_f_idx, best_threshold)
if len(L) == 0:
L_tree = DecisionNode(None, None, majority_count(dataset)) # 叶子节点
else:
L_tree = build_tree(L, son_f_idx_list, split_choice) # return DecisionNode
if len(R) == 0:
R_tree = DecisionNode(None, None, majority_count(dataset)) # 叶子节点
else:
R_tree = build_tree(R, son_f_idx_list, split_choice) # return DecisionNode
return DecisionNode(best_f_idx, best_threshold, value=None, L=L_tree, R=R_tree)
def predict_one(model: DecisionNode, data):
if model.value is not None:
return model.value
else:
feature_one = data[model.f_idx]
branch = None
if feature_one >= model.threshold:
branch = model.R # 走右边
else:
branch = model.L # 走左边
return predict_one(branch, data)
def predict_accuracy(y_predict, y_test):
y_predict = y_predict.tolist()
y_test = y_test.tolist()
count = 0
# count = np.sum(y_predict == y_test)
for i in range(len(y_predict)):
if int(y_predict[i]) == y_test[i]:
count = count + 1
accuracy = count / len(y_predict)
return accuracy
class SimpleDecisionTree(object):
def __init__(self, split_choice, min_samples: int = 1, min_gain: float = 0, max_depth: Union[int, None] = None,
max_leaves: Union[int, None] = None):
self.split_choice = split_choice
def fit(self, X: np.ndarray, y: np.ndarray) -> None:
dataset_in = np.c_[X, y]
f_idx_list = [i for i in range(X.shape[1])]
self.my_tree = build_tree(dataset_in, f_idx_list, self.split_choice)
def predict(self, X: np.ndarray) -> np.ndarray: # 递归 how?
predict_list = []
for data in X:
predict_list.append(predict_one(self.my_tree, data))
return np.array(predict_list)
if __name__ == "__main__":
predict_accuracy_all = []
for i in range(10):
iris = load_iris() # 导入数据集iris
x = iris.data # 特征数据 numpy.ndarray
y = iris.target # 分类数据
X_train, X_test, y_train, y_test = train_test_split(x, y, test_size=0.2)
predict_accuracy_list = [] # 储存4种结果
split_choice_list = ["gain", "gain_ratio", "gini"]
for split_choice in split_choice_list:
m = SimpleDecisionTree(split_choice)
m.fit(X_train, y_train)
y_predict = m.predict(X_test)
# print(y_predict)
# print(y_test.reshape(-1))
y_predict_accuracy = predict_accuracy(y_predict, y_test.reshape(-1))
predict_accuracy_list.append(y_predict_accuracy)
# print("split_choice:", split_choice, " | predict_accuracy: ", predict_accuracy(y_predict, y_test.reshape(-1)))
# print("-----------------------------------------------------------------------------")
# print(predict_accuracy_list)
# print("-----------------------------------------------------------------------------")
clf = DecisionTreeClassifier() # 所以参数均置为默认状态
clf.fit(X_train, y_train) # 使用训练集训练模型
predicted = clf.predict(X_test)
predict_accuracy_list.append(clf.score(X_test, y_test))
# print("sklearn精度是:{:.3f}".format(clf.score(X_test, y_test)))
predict_accuracy_all.append(predict_accuracy_list)
p = numpy.array(predict_accuracy_all)
p = np.round(p, decimals=3)
for i in p:
print(i)
# print(predict_accuracy_all)
print(p.mean(axis=0))
4.实验结果
使用信息增益、信息增益率、基尼系数三种不同评价增益的方法进行实验,预测的准确率如下图,另附上使用sklearn方法的准确率。
| 信息增益 | 信息增益率 | 基尼系数 | sklearn | |
|---|---|---|---|---|
| 1 | 0.967 | 0.967 | 0.933 | 0.967 |
| 2 | 0.967 | 0.967 | 0.933 | 0.933 |
| 3 | 0.967 | 0.967 | 0.833 | 0.833 |
| 4 | 0.9 | 0.9 | 0.9 | 0.967 |
| 5 | 0.967 | 0.967 | 0.967 | 0.967 |
| 6 | 0.933 | 0.933 | 0.967 | 0.933 |
| 7 | 1. | 1. | 0.867 | 1. |
| 8 | 0.867 | 0.867 | 0.833 | 0.9 |
| 9 | 0.933 | 0.933 | 0.9 | 0.933 |
| 10 | 0.967 | 0.967 | 0.933 | 0.933 |
| 平均值 | 0.9468 | 0.9468 | 0.9066 | 0.9366 |
可以发现,使用基尼系数来评价增益,准确率相比其他的方法低一些。总体来看,准确率都还是不错的。但也能看出,准确率的波动比较大,比如使用信息增益时,准确率最高为1,最低为0.867。原因可能是每次所划分的训练集、测试集不同。
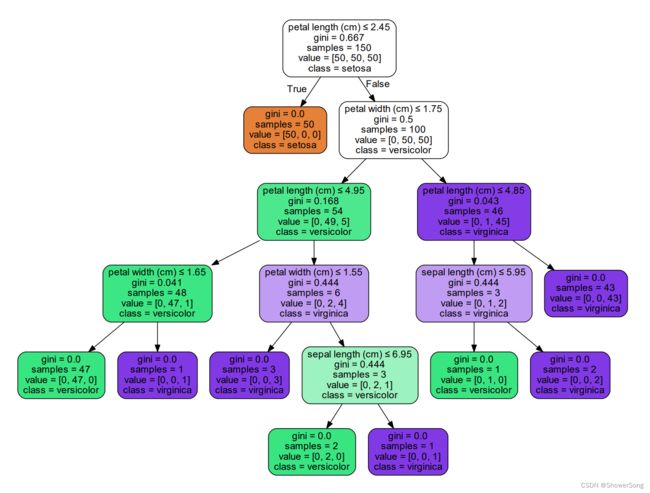
使用sklearn方法的决策图如下:
5.实验总结
本次实验难度有点大,首先是对决策树的原理了解不深刻,其次对决策树的数据结构认识不足,不知道怎么样去建树,对于递归的实现也有些困难,导致本次实验花费时间较多。另外,对于numpy的操作不熟悉,导致许多代码显得比较臃肿,可以用更简便的方法实现,后期还得多看看numpy。