AAAI 2023 | 从谱的角度来看待(图)对比学习

©作者 | 张逸飞
单位 | 香港中文大学
研究方向 | 图数据挖掘
前言
我们主要来介绍一下我们在 AAAI 23(NeurIPS Fast Track)的中稿,SFA: Spectrum Feature Augmentation in Graph Contrastive Leanring and Beyond。可惜的是在 NeurIPS 的的分数是 7762,和其中一个审稿人针锋相对几回合后,最终还没能赢得 AC 的青睐被接收。不过后来想想确实从审稿人的意见中获得了建设性的反馈(后面会讲),最终修修补补,在 AAAI 以 7766 的到接收并没有 NeurIPS 那样的波折。
作为我的第一篇 AAAI,我单方面宣布 AAAI 就是顶会,妥妥的 ML Top4(笑)。
又来到了起名字环节,本来想和 COSTA 一样起一个炫酷(容易记住的名字),本来定的 SPA: Spectrum Feature Augmentation。拿给老板看后,老板不怀好意的看了我说你确定想让你的方法叫 SPA??我想着叫温泉怎么了?

题外话说完了,开始进入正题,还是要先理解我们所要面临的问题

动机(Motivation)
现在自监督学习(Self-Supervised Learning, SSL)有一个普遍的观点 [1],就是认为一个好的自监督学习模型真正起作用的原因来源于两个方面。
1. 模型学习到了由数据增强(Data Augmentation, DA)带来的显式不变性(invariance)。
2. 模型避免学习到的嵌入(Embedding)存在维度/特征坍塌(Dimension/Feature Collapse)。
那么对比学习是这么做到这些的呢?我们来直观的解释下
如下图1所示。通过对原始的数据进行随机的数据增强。得到的图片并不影响人识别出来(e.g., 我们总是能认出这是只猫或狗)。这就意味着存在所谓的不变性知识(invariant knowlege)或者说是人察觉到本质特征。对比学习其实就是通过强迫模型认为来自同一样本的不同数据增强是一样的,进而保留所谓的本质特征。这一过程通常用利用优化不同增强数据间的距离来实现的。也就是我们常说的对齐度(Alignment)。

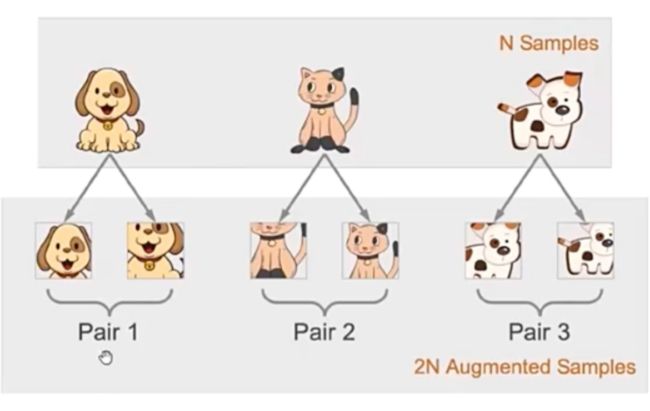
▲ 图1
但是需要注意的是, 仅仅只有 Alignement 是不够的,模型很容易偷懒学习到平凡解。
1. 什么是平凡解呢,一个最简单的例子就是,不管模型的输入是什么,或者说对于所有的输入,模型的输出都是一个常数向量(i.e.,),这样的话 alignment 就一直是最优,一样的常数的距离是 0(完美对齐)。这就是我们说的完全的特征塌陷(Complete Collapse),所有的特征嵌入都成为一个常数(图二(a))。
2. 除了完全的特征塌陷,另一个问题是特征塌陷(Dimension Collapse, DC),如图二(c)所示,学到的嵌入都只存在于某个子空间(Subspace)。比如我让模型给我学一个 3 维的嵌入,模型偷懒给我学了一个表面上是 3 维的嵌入实际上只有 2 维有用,剩下一维被浪费了。
虽然没有完全的坍塌,但是这也使得区别不同嵌入变的困难,因为多一个维度会让空间变的更加的稀疏,向量之间并不拥挤,更容易让下游任务的分类器来区分不同的嵌入从而获得更好的泛化性(当然前提是 Alignment 要做的好才行)。用个更通俗易懂的例子就是,假如我想造楼房,给你拨款了 1000 万预算去建房子,你小子贪污偷懒,就花了 1w 块,这建出来的不是豆腐渣工程么?
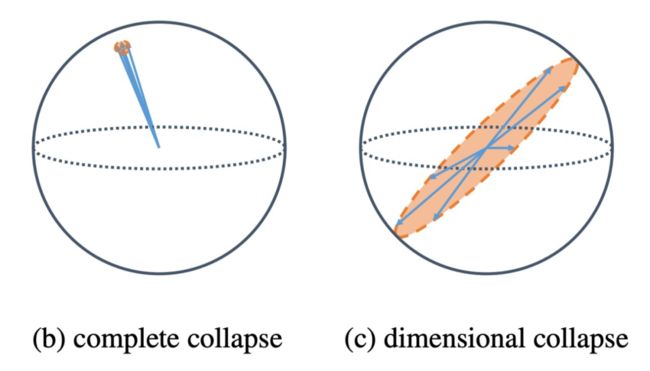
▲ 图2
为了避免这种情况,不同的方法有不同解决方案:
1. 比如常见模型,SimCLR GRACE,通过引入负样本来解决,不仅希望正样本也就是 Alignment 好,同样希望不同样本(负样本)离的远来解决特征塌陷。
2. 像 BalowTwin,Graph Balow Twin,CCA-SSG 通过显式的解耦合来解决特征塌陷。
3. 像一些 Siamese network Based 网络用不对称的结构来隐式的解决特征塌陷(证明可以看这篇文章)。

▲ 图3
理解完目前自监督学习为什么有效,那么其实如何推进对比学习的方向也就有了,其实就是我们
能不能达到更好的样本对齐(Better Alignment)?
能不能实现更好的缓解特征坍缩的(Avoid collapse)?
在我们这项研究中我们尝试从谱(Spectrum)的角度尝试去回答这样的问题,简单来说我们利用一个高效的方法来取得了
(Spectrum Noise)直接在谱上加入了均匀的噪声。
(Partial Rebalancing Spectrum)平衡了部分谱上各个分量的贡献程度。
我们称我们的方法为特征谱增强,Spectrum Feature Augmentation,值得注意的是我们分析的不是图拉普拉斯矩阵的谱,又称之为 Graph Spectrum。我们分析的是数据嵌入的谱,又称之为 Feature Spectrm。
接下来我会反复强调,为什么上述的两个操作可以有效的增加样本对齐,并且缓解特征坍缩。

问题(The Problem)
我们这里说的谱实际上就是矩阵(Feature Matrix)的奇异值(Singluar Value),一般谱由奇异值分解(Singular Value Decomposation, SVD)来得到,例如
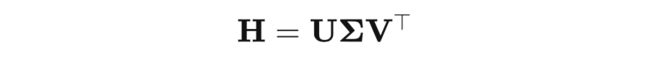
这里的 是分别是矩阵 的正交基(Orthogonal Basis, OB),是奇异值的分布,也就我们这里提到的谱(Spectrum),并且一般 。
那么谱在 j 计算对齐度的时候,到底是个什么作用呢?
为了方便我们后续的解释我们先定义几个符号,我们用 来表示编码器(Encoder),分别用 来表示两个不同视图(View)的嵌入,
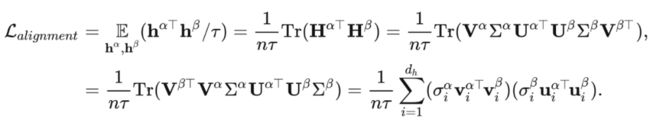
很容易看出来,这些奇异值实际上充当了在对齐不同正交基时的权重(Weight of aligning different basis)。而一般的谱分布通常是服从所谓的幂律分布如下面这个图的蓝线所示
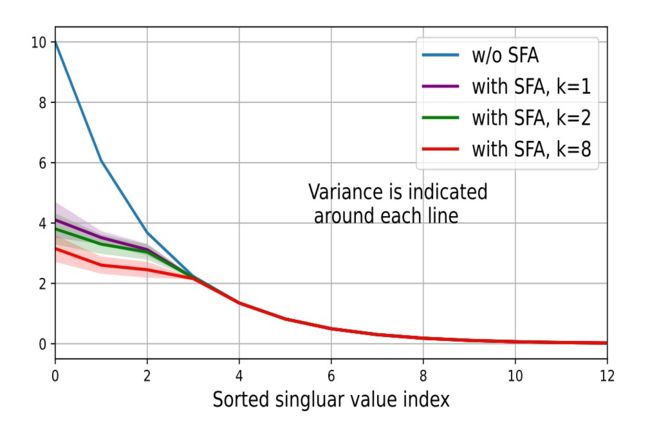
▲ 图4
那么带来的问题就是,当我们优化 Alignment 的时候,模型会不由自主的被奇异值大的 Basis 所主导,从而忽视其他奇异值小的 basis 带来的影响从而造成较差的对齐效果。通俗的点的例子就是,让你判断看两个人相似不相似,你光定盯着体积比较大的身体使劲看,而忽略了体积较小的颜值的影响,这么看来我和吴彦祖也差不多 (笑).
另外这种极不均衡的谱分布更会加剧特征坍缩,会使得学习到特征信息只存在于头部几个特征值特别大的 Basis 所张开的子空间上。
所以我们要平衡谱上各个分量的贡献程度(rebalance the spectrum),说到这里有朋友就又该跳出来了说这题我会,这不就是白化么(whiting)我把谱搞成均匀分布,这样每个分量的贡献度都一样!Easy Game!
不得不说确实有人在 CV 上这么做,但是我们知道在一个特征矩阵(Feature Map)中不仅仅有信号(Signal)的成分在,同样存在噪声(Noise)。那么白化(whiting)的时候就会同样放大噪声的贡献,还是判断人相似不相似这个例子,你可能就会纠结于一些无用的信息(比如衣服图案这种随机的特征)。
所以部分平衡谱上的贡献才是相对靠谱的策略。
理解到这里,又会有朋友问在谱上加均匀的噪声是干嘛的?有什么好处呢?
首先,我们都知道,我们要保留所谓的本质特征,那就要求数据增强的时候尽可能不损害语义信息,但又希望增强数据尽可能保持多样性。因此我们只在谱上添加了噪声,而没有改变正交基,使得特征空间没有发生改变,从而更大程度上保留了增强样本的语义信息,大概率不会产生坏样本。
其次,我们还是来看下面这个公式
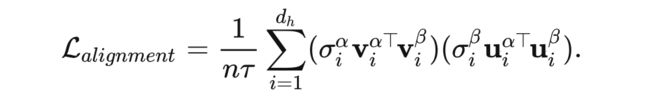
我们在优化上面式子的时候,奇异值也是一个可学习变量,因为它是由学习到的特征矩阵分解得到。我们通过在奇异值上叠加一个均匀的噪声(扰动)来帮助优化的过程专注于对齐正交基而不是对齐奇异值。
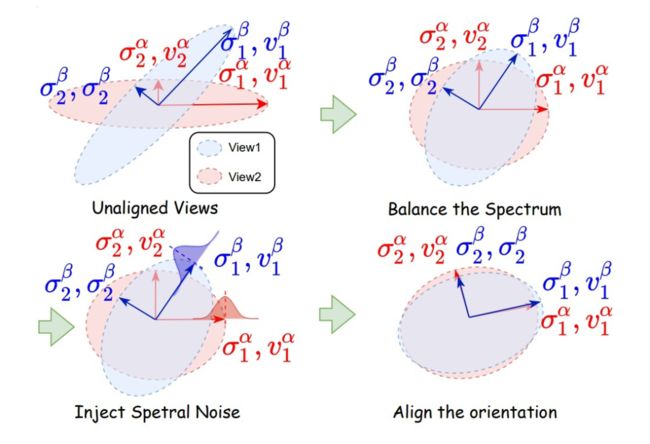
▲ 图5

方法(Method)
找了前进的方向,那么下一个问题是我们怎实现呢?常规的方法通常不是很适用,因为得到一个矩阵的谱是一个非常时间耗时的操作,通常需要使用 SVD。其次是 SVD 的反向传播非常不稳定,经常会出现数值不稳定(Numerical Error)。
为了方便大家去理解,我先直觉上给大家一个我们解决方法的描述,具体的证明过程可以看论文本身。我们的目的是隐式的去重新平衡谱,简单来说,我们用这样的形式去实现。

直觉上来说一个矩阵的低秩近似 (Low Rank Approximation)应该和原始的矩阵的正交基是一样的。假设 ,那么增强后的矩阵就可以写成
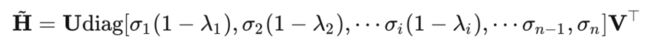
在这里 。那么要想实现部分平衡谱,我只需要 ,且 递增(如果 ,那么 ),这样我们就能保证 是一个递减数列。
因此,满足上述条件,我们的操作相当于给谱上奇异值大的项乘以了一个较小的值,而给奇异值较小的项乘以了一个较大的值,不难看出这是一个平衡的操作,当然由于是低秩近似我们忽略了奇异值特别小噪声项,所以形成了部分平衡的效果。
那么什么样的低秩近似可以保证上面的条件,又可以只在谱上添加随机噪声呢?这就用到了我们在 KDD'22 COSTA 的方法,我们可以用一个随机映射来获得这个低秩近似。其实 COSTA 可以看做是一个 Spectrum Augmentation 的方法,他在做低秩近似的同时,给谱上添加了噪声(我们会在 COSTA 的期刊版本上进行详细的证明)。
在 SFA 中,具体的算法如下图所示,1)我们首先生成一个随机向量;2)用这个随机向量与协方差矩阵进行迭代(Power Normalization);3)利用 Power Normalization 的得到向量来构建低秩矩;4)计算增强后的矩阵。

▲ 图6
我当然严格证明了这里的 并且递增的,当然效果就如图 4 同所示。
其实到这里都只是一个定性的分析,我们的方法可以很模糊的平衡谱,但是到底平衡程度的还是说不清楚,就如同 NeurlPS 的一个 reviewer 的灵魂发问:I still don't know how much the spectrum are balanced。
其实就是说上面这个给大的特征值分小权重,给小的特征值分大权重的描述太模糊了,到底分了多少?理解不了。虽然我们解释了很久,这取决于这个低秩矩阵的选择,但也确实没给出一个定量的分析。
所以我们更进一步的进行理论分析,我们定义一个函数 这个函数描谱在增强前后是怎么进行变化的。
由于这个函数并是一个随机函数(输出的值也取决于一个随机向量)。我们经过了理论的推导给出了这个函数均值与方差的解析表达式(i.e., 和 )。由于这俩式子推出来非常不美观也不容易看懂,我们这里用画图来表示。

▲ 图7
左边是我们利用我们计算出来的解析式所画出来的图,右边是我们利用算法得到的仿真结果,可以看出仿真与理论是吻合的。
那么这个图告诉我们什么了呢?
1. 只有红线的时候(k=1)的时候,算法可以有一个比较好的平衡效果,任意特征值大于 1 的值,都会被放缩到 0.8 附近(谱平衡)。
2. 横轴 <1 的地方斜率基本为 1,也就是说对于特征值小的值,基本不会有任何的放缩作用(部分谱平衡)。
除此之外论文还有关于一些关于我们方法的误差上上节和泛化性能的相关理论证明。感兴趣的朋友可以移步论文,这里只是一个科普文。

实验
实验部分比较无聊,因为我是做图,所以我主要做了图上的实验,CV 的实验我做了一些也放在论文里(主要是因为实在是太穷,CV 实验动不动好几张卡)。我贴一个主表,性能还是比较不错的。此外我们还对比了一些经典的谱增强的方法(e.g., whiting, Matrix Square Root 等)。
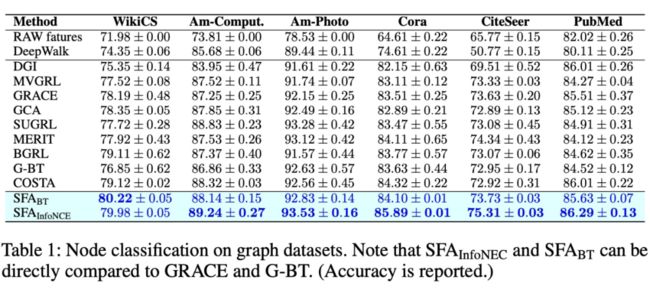
▲ 图8

总结
大家也观察到了,关于理解对比学习的文章越来越多,越来越的人注意到,特征坍缩的本质和谱的分布有很大的联系,越来越多的文章在 ICML 和 ICLR 上发现了谱平衡可以有效的提高对比学的性能。我们这里提供了一个可行的方法,当然后续还有很多可以改进的空间。
更多阅读




#投 稿 通 道#
让你的文字被更多人看到
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学术热点剖析、科研心得或竞赛经验讲解等。我们的目的只有一个,让知识真正流动起来。
稿件基本要求:
• 文章确系个人原创作品,未曾在公开渠道发表,如为其他平台已发表或待发表的文章,请明确标注
• 稿件建议以 markdown 格式撰写,文中配图以附件形式发送,要求图片清晰,无版权问题
• PaperWeekly 尊重原作者署名权,并将为每篇被采纳的原创首发稿件,提供业内具有竞争力稿酬,具体依据文章阅读量和文章质量阶梯制结算
投稿通道:
• 投稿邮箱:[email protected]
• 来稿请备注即时联系方式(微信),以便我们在稿件选用的第一时间联系作者
• 您也可以直接添加小编微信(pwbot02)快速投稿,备注:姓名-投稿

△长按添加PaperWeekly小编
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
·
·
