DeR-ViT(CVPR2022)
论文:
1:Salman, Hadi, et al. "Certified patch robustness via smoothed vision transformers." Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2022.
DeR-ViT-salman论文链接
2::Chen, Zhaoyu, et al. "Towards Practical Certifiable Patch Defense with Vision Transformer." Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2022.
DeR-ViT-chen论文链接
1.DeR-ViT-salman(MIT):Certified patch robustness via smoothed vision transformers.
1.1.abstract
经过认证的补丁防御可以保证图像分类器对有界连续区域内的任意变化的鲁棒性。但是,目前,这种稳健性是以降低标准精度和较慢的推理时间为代价的。作者展示了使用视觉转换器如何显着提高经认证的补丁鲁棒性,同时提高计算效率,并且不会导致标准精度大幅下降。这些改进源于ViT优雅地处理大量蒙版图像的固有能力。
本文主要是结合去随机平滑和ViT模型的可认证对抗防御。
1.2去随机平滑。
首先了解什么是去随机平滑

图像消融。图像消融是图像的变体,其中除了一小部分图像之外的所有图像都被掩盖了。例如,列消融会掩盖整个图像,除了固定宽度的列。
去随机平滑是一种流行的认证补丁防御方法,它构建了一个平滑分类器,包括两个主要组件:(1)一个基本分类器,和(2)一组用于平滑基本分类器的图像消融。然后,得到的平滑分类器返回基分类器对消融集 Sb(x) 的最频繁预测。去随机平滑是指图片部分连续,其余部分平滑,也即通过去随机消融的方式生成原图的消融副本,然后基分类器对每个副本给出分类结果,最终分类结果就是数量最多的那个结果。
去随机平滑的可证明效果:如果最频繁类别的消融数量超过第二频繁类别足够大的余量,则平滑分类器对于输入图像是可证明的鲁棒性。直观地说,一个大的边距使得对抗性补丁不可能改变平滑分类器的预测,因为一个补丁只能影响有限数量的消融。

具体来说,让 Δ 是消融集 Sb(x) 中对抗性补丁可以同时相交的最大消融数(例如,对于大小为 b 的列消融,一个 m × m 补丁最多可以与 Δ = m + b− 1 次消融)。然后,如果对于预测的类 c,平滑分类器在输入 x 上是可证明的鲁棒性就是公式2。
如果满足此阈值,则即使对抗性补丁损害了它相交的每个消融,也可以保证最频繁的类别不会改变。我们将平滑分类器的预测部分表示为正确且可证明的鲁棒性(根据等式 2)作为认证准确度。
1.3.Vision transformers.
方法的一个关键组成部分是视觉转换器(ViT)架构。与卷积架构相比,ViT 使用自注意力层而不是卷积层作为其主要构建块,并受到自然语言处理中自注意力的成功启发 。 ViT 在三个主要阶段处理图像:
标记化(Tokenization):ViT 将图像分成 p × p 块。然后将每个补丁嵌入到位置编码的令牌中。
自注意力(Self-Attention):然后通过一系列多头自注意力层传递令牌集
分类头(Classification head):将得到的表示输入全连接层以进行分类预测。
ViT的两个核心特性使 ViT 对于处理在去随机化平滑中出现的图像消融特别有吸引力。首先,与 CNN 不同,ViT 将图像作为标记集进行处理。因此,ViT 具有简单地从输入中删除不必要的标记并“忽略”图像的大区域的自然能力,这可以大大加快图像消融的处理速度。
此外,与局部操作的卷积不同,ViTs 中的自注意力机制在每一层全局共享信息 。因此,人们期望 ViT 更适合对图像消融进行分类,因为它们可以动态地关注小的、未屏蔽的区域。相比之下,CNN 必须逐渐在多个层上建立其感受野并处理被屏蔽的像素。
1.4.框架:
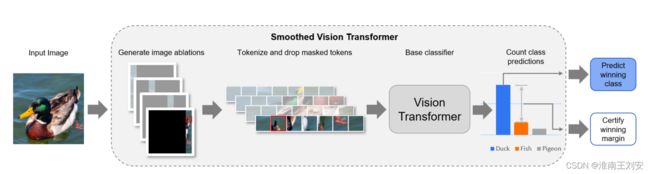
对于给定的图像,他们首先生成一组消融。然后将每个消融编码为标记,并丢弃完全屏蔽的标记。然后将每个消融的剩余标记输入视觉转换器,该转换器预测每个消融的类别标签。我们预测所有消融中预测最多的类别,并使用第二名类别的余量进行稳健性认证。
他们的操作主要就是列消融+完全抛弃有消融区域的补丁(减少冗余信息的计算)+跨步消融(减少消融副本数量)
文章的三步走步骤:
1.在位置上将整个烧蚀图像编码为一组标记。
2.删除与输入的完全屏蔽区域相对应的任何标记。
3.将剩余的令牌通过自注意力层。
1.5.实验
实验结果可以直接看文章,主要核心就是相比相同大小的Res-Net基分类器,显著提高了分类鲁棒性的同时,推理成本基本相同。
2.DeR-ViT-chen(复旦和腾讯优图合作的论文):Towards Practical Certifiable Patch Defense with Vision Transformer.
2.1 abstract
补丁攻击是对抗性示例中最具威胁性的物理攻击形式之一,它可以通过在连续区域中任意修改像素来导致网络导致错误分类。可认证的补丁防御可以保证分类器不受补丁攻击影响的鲁棒性。现有的可认证补丁防御牺牲了分类器的干净准确性,并且仅在玩具数据集上获得了较低的认证准确性。此外,这些方法的干净且经过认证的准确度仍然明显低于正常分类网络的准确度,这限制了它们在实践中的应用。为了实现实用的可认证补丁防御,作者将 Vision Transformer (ViT) 引入了去随机化平滑 (DS) 的框架中。具体来说,提出了一种渐进式平滑图像建模任务来训练 Vision Transformer,它可以在保留全局语义信息的同时捕获图像更易辨别的局部上下文。 F 或在现实世界中进行高效推理和部署,创新地将原始 ViT 的全局自注意力结构重构为孤立带单元自注意力。在 ImageNet 上,在 2% 面积补丁攻击下,的方法达到了 41.70% 的认证准确率,比之前的最佳方法 (26.00%) 提高了近 1 倍。同时,的方法达到了 78.58% 的清洁精度,非常接近正常的 ResNet-101 精度。大量实验表明,的方法通过在 CIF AR10 和 ImageNet 上进行有效推断,获得了最先进的干净且经过认证的准确度。
2.2 去随机平滑和ViT
不赘述
2.3 主要工作:
提出了一种有效的可认证补丁防御与 ViT,以提高准确性和推理效率。首先,引入了渐进式平滑图像建模任务来训练 ViT。具体来说,训练目标是基于平滑的图像波段逐步恢复原始图像标记。通过逐步重建,基分类器可以在保留全局语义信息的同时显式捕获图像的局部上下文。因此,可以通过非常有限的图像信息(经过平滑处理的薄图像带)获得更具判别性的局部表示,从而提高基分类器的性能。然后,将原始 ViT 的全局自注意力结构更新为孤立的带单元自注意力。将输入图像划分为bands,分别计算每个bandlike单元中的self-attention,为多个bands的并行计算提供了可行性。最后,方法在 ImageNet 上实现了 78.58% 的干净准确率,在 2% 区域补丁攻击下的有效推理中实现了 41.70% 的认证准确率。清洁精度非常接近正常的 ResNet-101 精度。大量实验表明,方法通过在 CIFAR10 和 ImageNet 上进行有效推断,获得了最先进的干净且经过认证的准确性。
1.将 ViT 引入可认证的补丁防御,并提出了一种渐进式平滑图像建模任务,该任务让模型在保留全局语义信息的同时捕获图像的更可辨别的局部上下文。
2.将 ViT 的全局自我注意结构更新为孤立的带单元自我注意,这大大加快了推理速度。
3.实验表明,方法通过在 CIFAR-10 和 ImageNet 上进行有效推断,获得了最先进的干净且经过认证的准确性。此外,方法在 ImageNet 上实现了 78.58% 的干净准确率,在 2% 区域补丁攻击下的有效推理中实现了 41.70% 的认证准确率。清洁精度非常接近正常的 ResNet-101 精度。
2.4 模型
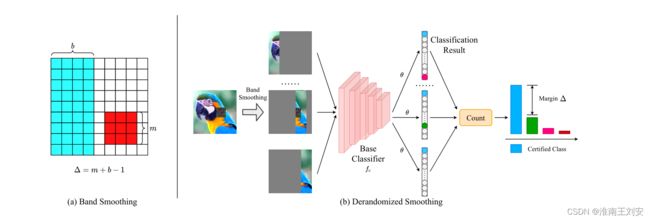
红色补丁代表对抗补丁,蓝色带代表(a)中带平滑后的保留图像。 (b) 描述了 DS 的管道。首先,DS 对带状平滑中的图像进行平滑处理,从不同位置获得平滑后的图像。然后将平滑后的图像输入基分类器 fc,我们通过阈值 θ 获得分类结果。最后,DS 统计结果也是上面公式 2 来判断图像是否经过认证。
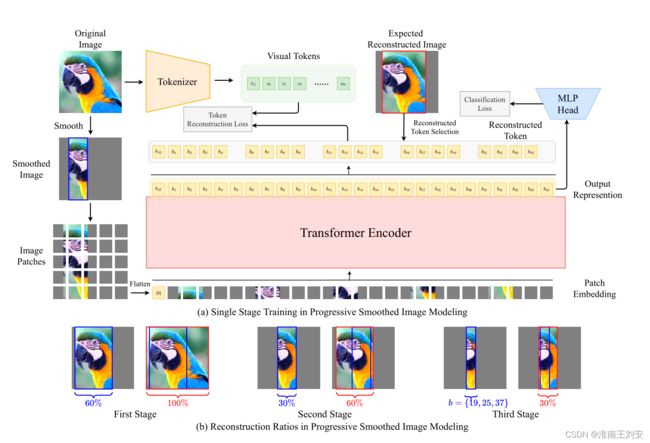
渐进平滑图像建模的介绍。 (a) 描述了渐进平滑图像建模中的单阶段平滑训练。我们期望平滑图像被重建为预期的重建图像。 (b) 描述了多阶段训练中的重建比率。蓝色框表示平滑后的波段,红色框表示预期的重建波段。
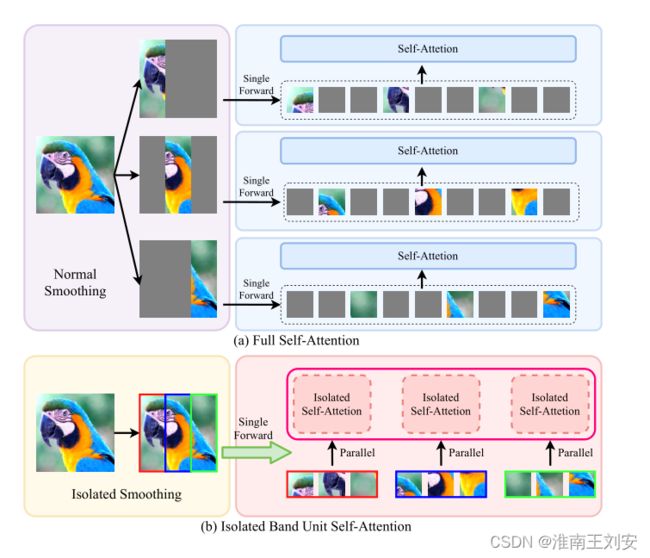
隔离带单元自注意力的介绍。 (a) 描述了平滑部分是多余且不需要计算的正常训练。 (b) 引入了孤立带单元自注意力,平滑部分被丢弃,自注意力仅在并行窗口内计算。
隔离带单元自注意力和MIT那篇其实异曲同工。
主要不同点和创新点还是多阶段渐进重构训练。
多阶段训练我的理解是综合不同band宽度的参数的训练效果的。
重构可能是既要生成更多平滑token,又担心未平滑区域过小保留的上下文信息等图像信息过少?
2.5 实验
也是又快又准:)(可参考论文)