股票查询小程序_以龙虎榜数据为例
功能需求
1.程序启动后,给用户提供查询接口,允许用户重复查股票行情信息(用到循环)
2.允许用户通过模糊查询股票名,比如输入“生物”,就把所有股票名称中包含“生物”的所有股票的信息打印出来
3.允许按'收盘价','涨跌幅','龙虎榜净买额','龙虎榜买入额','龙虎榜卖出额','龙虎榜成交额','市场总成交额','净买额占总成交比','成交额占总成交比','换手率','流通市值'等条件来筛选信息,比如输入“收盘价>20”,则把收盘价大于50的所有股票的信息都打印出来。
目录
功能需求
1.获取股票数据集
2.构建查询小程序
2.1 根据股票名称进行精确或模糊查询
2.2 根据变量数值进行简单条件查询
2.2.1 代码步骤分解
2.2.2 条件查询的代码整合
2.2.3 代码试错演示
1.获取股票数据集
通过akshare数据库搜集龙虎榜详情数据并将结果另存为csv文件保存
import akshare as ak
stock_lhb_detail_em_df=ak.stock_lhb_detail_em()# 东方财富网-数据中心-龙虎榜单-龙虎榜详情stock_lhb_detail_em_df.head()
stock_lhb_detail_em_df.to_csv('Statistics/stock_lhb_detail_em_df.csv')构建查询数据集
import pandas as pd
lhb_df=pd.read_csv('Statistics/stock_lhb_detail_em_df.csv',encoding="utf-8")
lhb_df.head()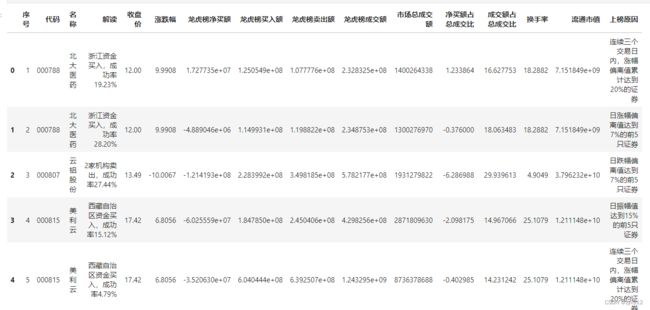

将数据转换为字典,定义索引并转置
stock_dict=stock_lhb_detail_em_df.set_index("名称").T.to_dict("list")2.构建查询小程序
2.1 根据股票名称进行精确或模糊查询
while True:
cmd=input("请输入要查询的股票名称,输入“退出”结束")
for stock_name,stock_data in stock_dict.items():
if cmd in stock_name:
print(stock_name,stock_data)
if cmd=="退出":
break 2.2 根据变量数值进行简单条件查询
2.2 根据变量数值进行简单条件查询
2.2.1 代码步骤分解
查看所有变量列名
headers=list(stock_lhb_detail_em_df.columns)
headers
输入查询条件
cmd=input("请输入要查询的股票列名及条件") 第1步,检查格式是否合法
import re
if '>' not in cmd and '<' not in cmd:
print("您的输入中未包含<或>,请重新输入!")
else:
cmd_parser=re.split("[<>]",cmd)
#re.split()以列表形式返回分割的字符串。分割符是<或>,获得分隔后的list
cmd_parser
if len(cmd_parser) !=2:
print("格式不合法,请检查后重新输入!")
else:
print("格式合法,可继续")
filter_column,filter_val=cmd_parser第2步,格式合法后检查列名是否合法
if filter_column in ['收盘价','涨跌幅','龙虎榜净买额','龙虎榜买入额','龙虎榜卖出额','龙虎榜成交额','市场总成交额','净买额占总成交比','成交额占总成交比','换手率','流通市值']:
print("列名合法,可继续")
else:
print('------------------------')
print("出错了!!!\n您输入的列名不合法,请核对后重新输入!")
print('------------------------')第3步,格式、列名都合法后再检查数值是否合法
try:
filter_val=float(filter_val)
print('数值合法,可继续')#打印顺利运行提示信息
print('索引名为:%s'%(filter_column))
print('条件为:%s'%(cmd[len(cmd_parser[0])]))
print('条件数值为:%s'%(filter_val))
except:
print('数值不合法,请重新输入') # 处理异常方式:打印错误提示信息 第4步,格式、列名、数值都合法后再进行股票数据查找
column_index=headers.index(filter_column)
print(column_index)#打印索引的数字,输出结果应为4,因为“收盘价”是所有索引中的第5个
for s_id,s_data in stock_dict.items():#返回之前定义的字典,分别定义索引和数值
if str(cmd[len(cmd_parser[0])])=='>':
if float(s_data[column_index])>float(filter_val):
print(s_id,s_data)
else:
if float(s_data[column_index])2.2.2 条件查询的代码整合
import re
while True:
cmd=input("请输入要查询的股票列名及条件,输入“退出”结束查询")
#定义退出查询条件
if cmd=="退出":
print("已退出查询!")
break
#第1步,检查格式是否合法
if '>' not in cmd and '<' not in cmd:
print('------------------------')
print('出错了!!!\n您的输入中未包含<或>,请重新输入!')
print('------------------------')
else:
if len(cmd_parser) !=2:
print('------------------------')
print("出错了!!!\n格式不合法,请检查后重新输入!")
print('------------------------')
else:
cmd_parser=re.split("[<>]",cmd)#re.split()以列表形式返回分割的字符串。分割符是<或>,获得分隔后的list
filter_column,filter_val=cmd_parser
#第2步,格式合法后再检查列名是否合法
if filter_column in ['收盘价','涨跌幅','龙虎榜净买额','龙虎榜买入额','龙虎榜卖出额','龙虎榜成交额','市场总成交额','净买额占总成交比','成交额占总成交比','换手率','流通市值']:
#第3步,格式、列名都合法后再检查数值是否合法
try:
filter_val=float(filter_val)
print('索引名为:%s'%(filter_column))
print('索引条件为:%s'%(cmd[len(cmd_parser[0])]))
print('条件数值为:%s'%(filter_val))
print('------------------------')
print('检索结果如下:')
print('------------------------')
#第4步,格式、列名、数值都合法后再进行股票数据查找
column_index=headers.index(filter_column)
for s_id,s_data in stock_dict.items():#返回之前定义的字典,分别定义索引和数值
if str(cmd[len(cmd_parser[0])])=='>':
if float(s_data[column_index])>float(filter_val):
print(s_id,s_data)
else:
if float(s_data[column_index])
2.2.3 代码试错演示:
