为什么深度神经网络这么难训练
目录
1、深度网络训练困难的原因:
2、消失的梯度问题
3、不稳定的梯度问题
参考文章:为什么很难训练深度神经网络? - 腾讯云开发者社区-腾讯云
1、深度网络训练困难的原因:
训练速度慢
在深度网络中,不同的层学习的速度差异很大。仔细研究会发现:
- 在网络中后面的层学习的情况很好的时候,先前的层次常常会在训练时停滞不变,基本上学不到东西。
- 当我们更加深入地理解这个问题时,发现相反的情形同样会出现:先前的层可能学习的比较好,但是后面的层却停滞不变。
这种停滞并不是因为运气不好。而是,有着更加根本的原因是学习的速度下降了!这些原因和基于梯度的学习技术相关!
实际上,我们发现在深度神经网络中使用基于梯度下降的学习方法本身存在着内在不稳定性。这种不稳定性使得先前或者后面的层的学习过程阻滞。
2、消失的梯度问题
import mnist_loader
import network2
training_data, validation_data, test_data = mnist_loader.load_data_wrapper()
# 输入层 784
# 隐藏层 30
# 输出层 10
sizes = [784, 30, 10]
net = network2.Network(sizes=sizes)
# 随机梯度下降开始训练
net.SGD(
training_data,
30,
10,
0.1,
lmbda=5.0,
evaluation_data=validation_data,
monitor_evaluation_accuracy=True,
)
"""
Epoch 0 training complete
Accuracy on evaluation data: 9280 / 10000
Epoch 1 training complete
Accuracy on evaluation data: 9391 / 10000
......
Epoch 28 training complete
Accuracy on evaluation data: 9626 / 10000
Epoch 29 training complete
Accuracy on evaluation data: 9647 / 1000
"""以MNIST数字分类问题做过示例,最终我们得到了分类的准确率为 96.47%,如果加深网络的层数会不会提升准确率呢?我们分别尝试一下几种情况:
# 准确率 96.8%
net = network2.Network([784, 30, 30, 10])
# 准确率 96.42%
net = network2.Network([784, 30, 30, 30, 10])
# 准确率 96.28%
net = network2.Network([784, 30, 30, 30, 30, 10])这说明一种情况,尽管我们加深神经网络的层数以让其学到更复杂的分类函数,但是并没有带来更好的分类表现(但也没有变得更差)。那么为什么会造成这种情况,这是我们接下来需要思考的问题。可以考虑先假设额外的隐藏层的确能够在原理上起到作⽤,问题是我们的学习算法没有发现正确的权值和偏置。
下图(基于[784, 30, 30, 10]网络)表⽰了每个神经元权重和偏置在神经⽹络学习时的变化速率,图中的每个神经元有⼀个条形统计图,表⽰这个神经元在⽹络进⾏学习时改变的速度。更⼤的条意味着更快的速度,而小的条则表⽰变化缓慢。
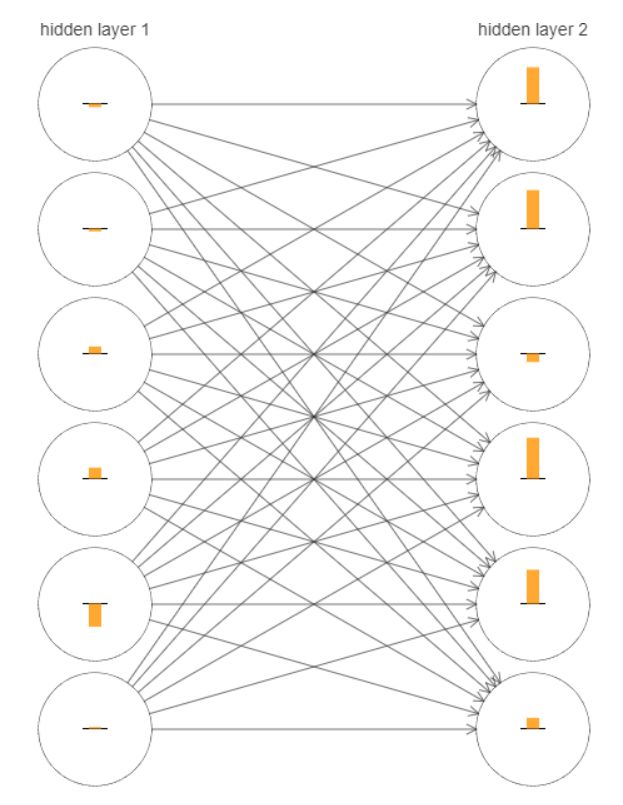
可以发现,第⼆个隐藏层上的条基本上都要比第⼀个隐藏层上的条要大;所以,在第⼆个隐藏层的神经元将学习得更加快速。这并不是巧合,前⾯的层学习速度确实低于后⾯的层。
我们可以继续观察学习速度的变化,下方分别是2~4个隐藏层的学习速度变化图:
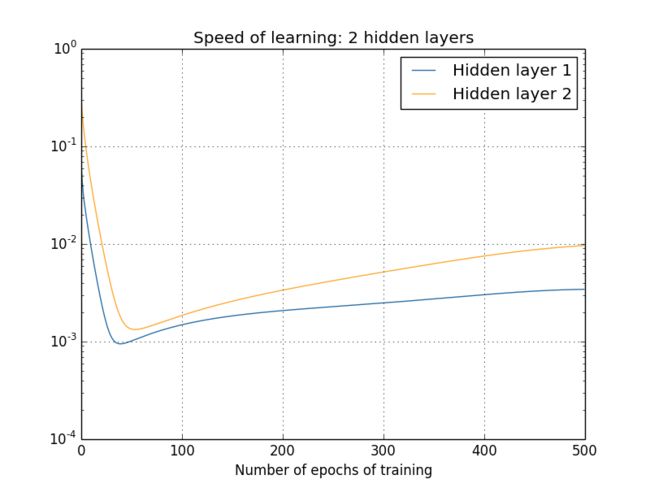
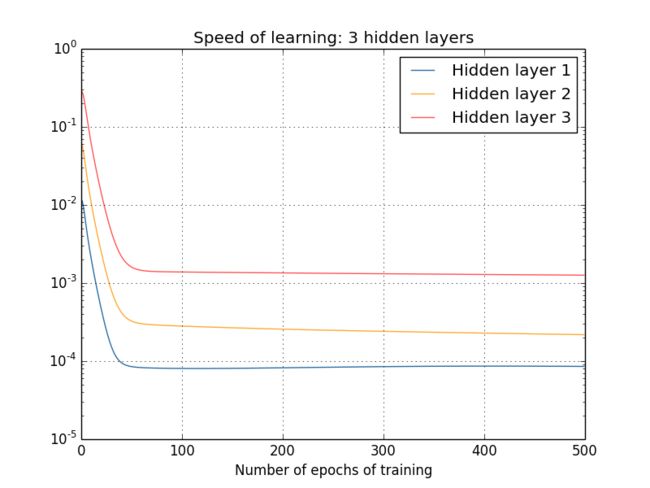
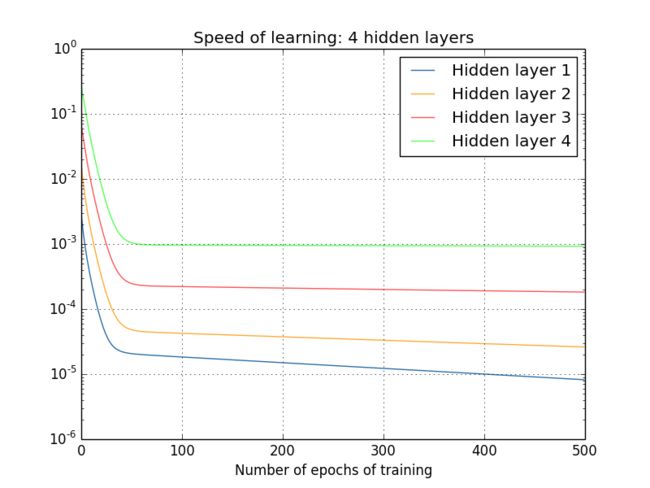
同样的情况出现了,前⾯的隐藏层的学习速度要低于后⾯的隐藏层。这⾥,第⼀层的学习速度和最后⼀层要差了两个数量级,也就是⽐第四层慢了 100 倍。
我们可以得出一个结果,在某些深度神经⽹络中,在我们隐藏层反向传播的时候梯度倾向于变小;这意味着在前⾯的隐藏层中的神经元学习速度要慢于后⾯的隐藏层,这个现象也被称作是梯度消失问题。
3、不稳定的梯度问题
核心原因在于深度神经网络中的梯度不稳定性,会造成前面层中梯度消失或者梯度爆炸
根本的问题其实并非是消失的梯度问题或者爆炸的梯度问题,而是在前面的层上的梯度是来自后面的层上项的乘积。当存在过多的层次时,就出现了内在本质上的不稳定场景。唯一让所有层都接近相同的学习速度的方式是所有这些项的乘积都能得到一种平衡。如果没有某种机制或者更加本质的保证来达成平衡,那网络就很容易不稳定了。简而言之,真实的问题就是神经网络受限于不稳定梯度的问题。所以,如果我们使用标准的基于梯度的学习算法,在网络中的不同层会出现按照不同学习速度学习的情况
消失的梯度问题普遍存在:我们已经看到了在神经网络的前面的层中梯度可能会消失也可能会爆炸。