[Code] [NeRF] VQRF代码与实验 (2)
VQRF Code
- run_final.py
-
- train()
-
- 1. init
- 2. coarse geometry searching
- 3. fine detail reconstruction
- 4. vq finetune
- scene_rep_reconstruction()
-
- 1. init & find whether there is existing checkpoint path
- 2. init batch rays sampler
- 3. view-count-based learning rate
- 4. train
- vq_finetune()
-
- 1. init & scene_rep_reconstruction (vq fintune): reload from {load_ckpt_path}
- 2. init batch rays sampler
- 3. view-count-based learning rate
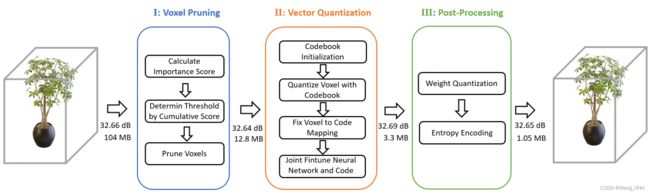
- 4. Initialize importance score
- 5. Codebook initialization
- 6. Apply voxel pruning and vector quantization
- 7. Joint finetune VQ-DVGO
- compute_bbox
-
- compute_bbox_by_cam_frustrm()
- compute_bbox_by_coarse_geo()
- main()
-
- 关键流程
- render_viewpoints
- seed
- load data_dict
- config_parser
Paper Link: Compressing Volumetric Radiance Fields to 1 MB
Code Link: VQRF
相关内容:VQRF代码与实验 (1)
run_final.py
![[Code] [NeRF] VQRF代码与实验 (2)_第1张图片](http://img.e-com-net.com/image/info8/1b72618a4eaa41c099d49933f379ebed.jpg)
![[Code] [NeRF] VQRF代码与实验 (2)_第2张图片](http://img.e-com-net.com/image/info8/65106b1bb089448bb9d0af4035b0116a.jpg)
train()
1. init
def train(args, cfg, data_dict):
# init
print('train: start')
eps_time = time.time()
os.makedirs(os.path.join(cfg.basedir, cfg.expname), exist_ok=True)
with open(os.path.join(cfg.basedir, cfg.expname, 'args.txt'), 'w') as file:
for arg in sorted(vars(args)):
attr = getattr(args, arg)
file.write('{} = {}\n'.format(arg, attr))
cfg.dump(os.path.join(cfg.basedir, cfg.expname, 'config.py'))
2. coarse geometry searching
# coarse geometry searching (only works for inward bounded scenes)
eps_coarse = time.time()
xyz_min_coarse, xyz_max_coarse = compute_bbox_by_cam_frustrm(args=args, cfg=cfg, **data_dict)
if not os.path.exists(os.path.join(cfg.basedir, cfg.expname, f'corse_last.tar')):
if cfg.coarse_train.N_iters > 0:
scene_rep_reconstruction(
args=args, cfg=cfg,
cfg_model=cfg.coarse_model_and_render, cfg_train=cfg.coarse_train,
xyz_min=xyz_min_coarse, xyz_max=xyz_max_coarse,
data_dict=data_dict, stage='coarse')
eps_coarse = time.time() - eps_coarse
eps_time_str = f'{eps_coarse//3600:02.0f}:{eps_coarse//60%60:02.0f}:{eps_coarse%60:02.0f}'
print('train: coarse geometry searching in', eps_time_str)
coarse_ckpt_path = os.path.join(cfg.basedir, cfg.expname, f'coarse_last.tar')
else:
print('train: skip coarse geometry searching')
coarse_ckpt_path = None
3. fine detail reconstruction
# fine detail reconstruction
eps_fine = time.time()
if cfg.coarse_train.N_iters == 0:
xyz_min_fine, xyz_max_fine = xyz_min_coarse.clone(), xyz_max_coarse.clone()
else:
xyz_min_fine, xyz_max_fine = compute_bbox_by_coarse_geo(
model_class=dvgo.DirectVoxGO, model_path=coarse_ckpt_path,
thres=cfg.fine_model_and_render.bbox_thres)
if not os.path.exists(os.path.join(cfg.basedir, cfg.expname, f'fine_last.tar')):
scene_rep_reconstruction(
args=args, cfg=cfg,
cfg_model=cfg.fine_model_and_render, cfg_train=cfg.fine_train,
xyz_min=xyz_min_fine, xyz_max=xyz_max_fine,
data_dict=data_dict, stage='fine',
coarse_ckpt_path=coarse_ckpt_path)
eps_fine = time.time() - eps_fine
eps_time_str = f'{eps_fine//3600:02.0f}:{eps_fine//60%60:02.0f}:{eps_fine%60:02.0f}'
print('train: fine detail reconstruction in', eps_time_str)
4. vq finetune
vq_finetune(
args=args, cfg=cfg,
cfg_model=cfg.vq_model_and_render, cfg_train=cfg.vq_train,
xyz_min=xyz_min_fine, xyz_max=xyz_max_fine,
data_dict=data_dict, stage='vq',
load_ckpt_path=os.path.join(cfg.basedir, cfg.expname, f'fine_last.tar'))
eps_fine = time.time() - eps_fine
eps_time_str = f'{eps_fine//3600:02.0f}:{eps_fine//60%60:02.0f}:{eps_fine%60:02.0f}'
print('train: fine VQ finetune reconstruction in', eps_time_str)
eps_time = time.time() - eps_time
eps_time_str = f'{eps_time//3600:02.0f}:{eps_time//60%60:02.0f}:{eps_time%60:02.0f}'
print('train: finish (eps time', eps_time_str, ')')
scene_rep_reconstruction()
Coarse:
scene_rep_reconstruction(
args=args, cfg=cfg,
cfg_model=cfg.coarse_model_and_render, cfg_train=cfg.coarse_train,
xyz_min=xyz_min_coarse, xyz_max=xyz_max_coarse,
data_dict=data_dict, stage=‘coarse’)
Fine:
scene_rep_reconstruction(
args=args, cfg=cfg,
cfg_model=cfg.fine_model_and_render, cfg_train=cfg.fine_train,
xyz_min=xyz_min_fine, xyz_max=xyz_max_fine,
data_dict=data_dict, stage=‘fine’,
coarse_ckpt_path=coarse_ckpt_path)
1. init & find whether there is existing checkpoint path
# init
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
if abs(cfg_model.world_bound_scale - 1) > 1e-9:
xyz_shift = (xyz_max - xyz_min) * (cfg_model.world_bound_scale - 1) / 2
xyz_min -= xyz_shift
xyz_max += xyz_shift
HW, Ks, near, far, i_train, i_val, i_test, poses, render_poses, images = [
data_dict[k] for k in [
'HW', 'Ks', 'near', 'far', 'i_train', 'i_val', 'i_test', 'poses', 'render_poses', 'images'
]
]
# find whether there is existing checkpoint path
last_ckpt_path = os.path.join(cfg.basedir, cfg.expname, f'{stage}_last.tar')
if args.no_reload:
reload_ckpt_path = None
elif args.ft_path:
reload_ckpt_path = args.ft_path
elif os.path.isfile(last_ckpt_path):
reload_ckpt_path = last_ckpt_path
else:
reload_ckpt_path = None
# init model and optimizer
if reload_ckpt_path is None:
print(f'scene_rep_reconstruction ({stage}): train from scratch')
model, optimizer = create_new_model(cfg, cfg_model, cfg_train, xyz_min, xyz_max, stage, coarse_ckpt_path)
start = 0
if cfg_model.maskout_near_cam_vox:
model.maskout_near_cam_vox(poses[i_train,:3,3], near)
else:
print(f'scene_rep_reconstruction ({stage}): reload from {reload_ckpt_path}')
model, optimizer, start = load_existed_model(args, cfg, cfg_train, reload_ckpt_path)
# init rendering setup
render_kwargs = {
'near': data_dict['near'],
'far': data_dict['far'],
'bg': 1 if cfg.data.white_bkgd else 0,
'rand_bkgd': cfg.data.rand_bkgd,
'stepsize': cfg_model.stepsize,
'inverse_y': cfg.data.inverse_y,
'flip_x': cfg.data.flip_x,
'flip_y': cfg.data.flip_y,
}
model, optimizer = create_new_model(cfg, cfg_model, cfg_train, xyz_min, xyz_max, stage, coarse_ckpt_path)
def create_new_model(cfg, cfg_model, cfg_train, xyz_min, xyz_max, stage, coarse_ckpt_path):
model_kwargs = copy.deepcopy(cfg_model)
num_voxels = model_kwargs.pop('num_voxels')
if len(cfg_train.pg_scale):
num_voxels = int(num_voxels / (2**len(cfg_train.pg_scale)))
if cfg.data.ndc:
print(f'scene_rep_reconstruction ({stage}): \033[96muse multiplane images\033[0m')
model = dmpigo.DirectMPIGO(
xyz_min=xyz_min, xyz_max=xyz_max,
num_voxels=num_voxels,
**model_kwargs)
elif cfg.data.unbounded_inward:
print(f'scene_rep_reconstruction ({stage}): \033[96muse contraced voxel grid (covering unbounded)\033[0m')
model = dcvgo.DirectContractedVoxGO(
xyz_min=xyz_min, xyz_max=xyz_max,
num_voxels=num_voxels,
**model_kwargs)
else:
print(f'scene_rep_reconstruction ({stage}): \033[96muse dense voxel grid\033[0m')
model = dvgo.DirectVoxGO(
xyz_min=xyz_min, xyz_max=xyz_max,
num_voxels=num_voxels,
mask_cache_path=coarse_ckpt_path,
**model_kwargs)
model = model.to(device)
optimizer = utils.create_optimizer_or_freeze_model(model, cfg_train, global_step=0)
return model, optimizer
model, optimizer, start = load_existed_model(args, cfg, cfg_train, reload_ckpt_path)
def load_existed_model(args, cfg, cfg_train, reload_ckpt_path):
if cfg.data.ndc:
model_class = dmpigo.DirectMPIGO
elif cfg.data.unbounded_inward:
model_class = dcvgo.DirectContractedVoxGO
else:
model_class = dvgo.DirectVoxGO
model = utils.load_model(model_class, reload_ckpt_path).to(device)
optimizer = utils.create_optimizer_or_freeze_model(model, cfg_train, global_step=0)
model, optimizer, start = utils.load_checkpoint(
model, optimizer, reload_ckpt_path, args.no_reload_optimizer)
return model, optimizer, start
2. init batch rays sampler
rgb_tr, rays_o_tr, rays_d_tr, viewdirs_tr, imsz, batch_index_sampler = gather_training_rays()
# init batch rays sampler
def gather_training_rays():
if data_dict['irregular_shape']:
rgb_tr_ori = [images[i].to('cpu' if cfg.data.load2gpu_on_the_fly else device) for i in i_train]
else:
rgb_tr_ori = images[i_train].to('cpu' if cfg.data.load2gpu_on_the_fly else device)
if cfg_train.ray_sampler == 'in_maskcache':
rgb_tr, rays_o_tr, rays_d_tr, viewdirs_tr, imsz = dvgo.get_training_rays_in_maskcache_sampling(
rgb_tr_ori=rgb_tr_ori,
train_poses=poses[i_train],
HW=HW[i_train], Ks=Ks[i_train],
ndc=cfg.data.ndc, inverse_y=cfg.data.inverse_y,
flip_x=cfg.data.flip_x, flip_y=cfg.data.flip_y,
model=model, render_kwargs=render_kwargs)
elif cfg_train.ray_sampler == 'flatten':
rgb_tr, rays_o_tr, rays_d_tr, viewdirs_tr, imsz = dvgo.get_training_rays_flatten(
rgb_tr_ori=rgb_tr_ori,
train_poses=poses[i_train],
HW=HW[i_train], Ks=Ks[i_train], ndc=cfg.data.ndc, inverse_y=cfg.data.inverse_y,
flip_x=cfg.data.flip_x, flip_y=cfg.data.flip_y)
else:
rgb_tr, rays_o_tr, rays_d_tr, viewdirs_tr, imsz = dvgo.get_training_rays(
rgb_tr=rgb_tr_ori,
train_poses=poses[i_train],
HW=HW[i_train], Ks=Ks[i_train], ndc=cfg.data.ndc, inverse_y=cfg.data.inverse_y,
flip_x=cfg.data.flip_x, flip_y=cfg.data.flip_y)
index_generator = dvgo.batch_indices_generator(len(rgb_tr), cfg_train.N_rand)
batch_index_sampler = lambda: next(index_generator)
return rgb_tr, rays_o_tr, rays_d_tr, viewdirs_tr, imsz, batch_index_sampler
3. view-count-based learning rate
per_voxel_init()
# view-count-based learning rate
if cfg_train.pervoxel_lr:
def per_voxel_init():
cnt = model.voxel_count_views(
rays_o_tr=rays_o_tr, rays_d_tr=rays_d_tr, imsz=imsz, near=near, far=far,
stepsize=cfg_model.stepsize, downrate=cfg_train.pervoxel_lr_downrate,
irregular_shape=data_dict['irregular_shape'])
optimizer.set_pervoxel_lr(cnt)
model.mask_cache.mask[cnt.squeeze() <= 2] = False
per_voxel_init()
if cfg_train.maskout_lt_nviews > 0:
model.update_occupancy_cache_lt_nviews(
rays_o_tr, rays_d_tr, imsz, render_kwargs, cfg_train.maskout_lt_nviews)
4. train
training & save
torch.cuda.empty_cache()
psnr_lst = []
time0 = time.time()
global_step = -1
for global_step in trange(1+start, 1+cfg_train.N_iters):
# training code
if global_step != -1:
torch.save({
'global_step': global_step,
'model_kwargs': model.get_kwargs(),
'model_state_dict': model.state_dict(),
'optimizer_state_dict': optimizer.state_dict(),
}, last_ckpt_path)
print(f'scene_rep_reconstruction ({stage}): saved checkpoints at', last_ckpt_path)
for循环下具体training内容:
- renew occupancy grid
if model.mask_cache is not None and (global_step + 500) % 1000 == 0:
model.update_occupancy_cache()
- progress scaling checkpoint
# progress scaling checkpoint
if global_step in cfg_train.pg_scale:
n_rest_scales = len(cfg_train.pg_scale)-cfg_train.pg_scale.index(global_step)-1
cur_voxels = int(cfg_model.num_voxels / (2**n_rest_scales))
if isinstance(model, (dvgo.DirectVoxGO, dcvgo.DirectContractedVoxGO)):
model.scale_volume_grid(cur_voxels)
elif isinstance(model, dmpigo.DirectMPIGO):
model.scale_volume_grid(cur_voxels, model.mpi_depth)
else:
raise NotImplementedError
optimizer = utils.create_optimizer_or_freeze_model(model, cfg_train, global_step=0)
model.act_shift -= cfg_train.decay_after_scale
torch.cuda.empty_cache()
- random sample rays
# random sample rays
if cfg_train.ray_sampler in ['flatten', 'in_maskcache']:
sel_i = batch_index_sampler()
target = rgb_tr[sel_i]
rays_o = rays_o_tr[sel_i]
rays_d = rays_d_tr[sel_i]
viewdirs = viewdirs_tr[sel_i]
elif cfg_train.ray_sampler == 'random':
sel_b = torch.randint(rgb_tr.shape[0], [cfg_train.N_rand])
sel_r = torch.randint(rgb_tr.shape[1], [cfg_train.N_rand])
sel_c = torch.randint(rgb_tr.shape[2], [cfg_train.N_rand])
target = rgb_tr[sel_b, sel_r, sel_c]
rays_o = rays_o_tr[sel_b, sel_r, sel_c]
rays_d = rays_d_tr[sel_b, sel_r, sel_c]
viewdirs = viewdirs_tr[sel_b, sel_r, sel_c]
else:
raise NotImplementedError
- load to gpu
if cfg.data.load2gpu_on_the_fly:
target = target.to(device)
rays_o = rays_o.to(device)
rays_d = rays_d.to(device)
viewdirs = viewdirs.to(device)
- volume rendering
# volume rendering
render_result = model(
rays_o, rays_d, viewdirs,
global_step=global_step, target=target, is_train=True,
**render_kwargs)
- gradient descent step
optimizer.zero_grad(set_to_none=True)
loss = cfg_train.weight_main * F.mse_loss(render_result['rgb_marched'], target)
psnr = utils.mse2psnr(loss.detach())
if cfg_train.weight_entropy_last > 0:
pout = render_result['alphainv_last'].clamp(1e-6, 1-1e-6)
entropy_last_loss = -(pout*torch.log(pout) + (1-pout)*torch.log(1-pout)).mean()
loss += cfg_train.weight_entropy_last * entropy_last_loss
if cfg_train.weight_nearclip > 0:
near_thres = data_dict['near_clip'] / model.scene_radius[0].item()
near_mask = (render_result['t'] < near_thres)
density = render_result['raw_density'][near_mask]
if len(density):
nearclip_loss = (density - density.detach()).sum()
loss += cfg_train.weight_nearclip * nearclip_loss
if cfg_train.weight_distortion > 0:
n_max = render_result['n_max']
s = render_result['s']
w = render_result['weights']
ray_id = render_result['ray_id']
loss_distortion = flatten_eff_distloss(w, s, 1/n_max, ray_id)
loss += cfg_train.weight_distortion * loss_distortion
if cfg_train.weight_rgbper > 0:
rgbper = (render_result['raw_rgb'] - target[render_result['ray_id']]).pow(2).sum(-1)
rgbper_loss = (rgbper * render_result['weights'].detach()).sum() / len(rays_o)
loss += cfg_train.weight_rgbper * rgbper_loss
loss.backward()
if global_step<cfg_train.tv_before and global_step>cfg_train.tv_after and global_step%cfg_train.tv_every==0:
if cfg_train.weight_tv_density>0:
model.density_total_variation_add_grad(
cfg_train.weight_tv_density/len(rays_o), global_step<cfg_train.tv_dense_before)
if cfg_train.weight_tv_k0>0:
model.k0_total_variation_add_grad(
cfg_train.weight_tv_k0/len(rays_o), global_step<cfg_train.tv_dense_before)
optimizer.step()
psnr_lst.append(psnr.item())
- update lr
# update lr
decay_steps = cfg_train.lrate_decay * 1000
decay_factor = 0.1 ** (1/decay_steps)
for i_opt_g, param_group in enumerate(optimizer.param_groups):
param_group['lr'] = param_group['lr'] * decay_factor
- check log & save
# check log & save
if global_step%args.i_print==0:
eps_time = time.time() - time0
eps_time_str = f'{eps_time//3600:02.0f}:{eps_time//60%60:02.0f}:{eps_time%60:02.0f}'
tqdm.write(f'scene_rep_reconstruction ({stage}): iter {global_step:6d} / '
f'Loss: {loss.item():.9f} / PSNR: {np.mean(psnr_lst):5.2f} / '
f'Eps: {eps_time_str}')
psnr_lst = []
if global_step%args.i_weights==0:
path = os.path.join(cfg.basedir, cfg.expname, f'{stage}_{global_step:06d}.tar')
torch.save({
'global_step': global_step,
'model_kwargs': model.get_kwargs(),
'model_state_dict': model.state_dict(),
'optimizer_state_dict': optimizer.state_dict(),
}, path)
print(f'scene_rep_reconstruction ({stage}): saved checkpoints at', path)
vq_finetune()
vq_finetune(
args=args, cfg=cfg,
cfg_model=cfg.vq_model_and_render, cfg_train=cfg.vq_train,
xyz_min=xyz_min_fine, xyz_max=xyz_max_fine,
data_dict=data_dict, stage=‘vq’,
load_ckpt_path=os.path.join(cfg.basedir, cfg.expname, f’fine_last.tar’))
1. init & scene_rep_reconstruction (vq fintune): reload from {load_ckpt_path}
# init
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
if abs(cfg_model.world_bound_scale - 1) > 1e-9:
xyz_shift = (xyz_max - xyz_min) * (cfg_model.world_bound_scale - 1) / 2
xyz_min -= xyz_shift
xyz_max += xyz_shift
HW, Ks, near, far, i_train, i_val, i_test, poses, render_poses, images = [
data_dict[k] for k in [
'HW', 'Ks', 'near', 'far', 'i_train', 'i_val', 'i_test', 'poses', 'render_poses', 'images'
]
]
print(f'scene_rep_reconstruction (vq fintune): reload from {load_ckpt_path}')
last_ckpt_path = os.path.join(cfg.basedir, cfg.expname, f'vq_last.tar')
model, optimizer = create_new_model_for_vq(cfg, cfg_model, cfg_train, xyz_min, xyz_max, stage, load_ckpt_path, strict=False)
# init rendering setup
render_kwargs = {
'near': data_dict['near'],
'far': data_dict['far'],
'bg': 1 if cfg.data.white_bkgd else 0,
'rand_bkgd': cfg.data.rand_bkgd,
'stepsize': cfg_model.stepsize,
'inverse_y': cfg.data.inverse_y,
'flip_x': cfg.data.flip_x,
'flip_y': cfg.data.flip_y,
}
model, optimizer = create_new_model_for_vq(cfg, cfg_model, cfg_train, xyz_min, xyz_max, stage, load_ckpt_path, strict=False)
def create_new_model_for_vq(cfg, cfg_model, cfg_train, xyz_min, xyz_max, stage, coarse_ckpt_path, strict=False):
model_class = dvgo.DirectVoxGO
ckpt = torch.load(coarse_ckpt_path)
model_kwargs = ckpt['model_kwargs']
model_kwargs.update(cfg_model)
model = model_class(**model_kwargs)
model.load_state_dict(ckpt['model_state_dict'],strict=False)
model = model.to(device)
optimizer = utils.create_optimizer_or_freeze_model(model, cfg_train, global_step=0)
optimizer.load_state_dict(ckpt['optimizer_state_dict'])
return model, optimizer
2. init batch rays sampler
rgb_tr, rays_o_tr, rays_d_tr, viewdirs_tr, imsz, batch_index_sampler = gather_training_rays()
def gather_training_rays():
if data_dict['irregular_shape']:
rgb_tr_ori = [images[i].to('cpu' if cfg.data.load2gpu_on_the_fly else device) for i in i_train]
else:
rgb_tr_ori = images[i_train].to('cpu' if cfg.data.load2gpu_on_the_fly else device)
if cfg_train.ray_sampler == 'in_maskcache':
rgb_tr, rays_o_tr, rays_d_tr, viewdirs_tr, imsz = dvgo.get_training_rays_in_maskcache_sampling(
rgb_tr_ori=rgb_tr_ori,
train_poses=poses[i_train],
HW=HW[i_train], Ks=Ks[i_train],
ndc=cfg.data.ndc, inverse_y=cfg.data.inverse_y,
flip_x=cfg.data.flip_x, flip_y=cfg.data.flip_y,
model=model, render_kwargs=render_kwargs)
elif cfg_train.ray_sampler == 'flatten':
rgb_tr, rays_o_tr, rays_d_tr, viewdirs_tr, imsz = dvgo.get_training_rays_flatten(
rgb_tr_ori=rgb_tr_ori,
train_poses=poses[i_train],
HW=HW[i_train], Ks=Ks[i_train], ndc=cfg.data.ndc, inverse_y=cfg.data.inverse_y,
flip_x=cfg.data.flip_x, flip_y=cfg.data.flip_y)
else:
rgb_tr, rays_o_tr, rays_d_tr, viewdirs_tr, imsz = dvgo.get_training_rays(
rgb_tr=rgb_tr_ori,
train_poses=poses[i_train],
HW=HW[i_train], Ks=Ks[i_train], ndc=cfg.data.ndc, inverse_y=cfg.data.inverse_y,
flip_x=cfg.data.flip_x, flip_y=cfg.data.flip_y)
index_generator = dvgo.batch_indices_generator(len(rgb_tr), cfg_train.N_rand)
batch_index_sampler = lambda: next(index_generator)
return rgb_tr, rays_o_tr, rays_d_tr, viewdirs_tr, imsz, batch_index_sampler
3. view-count-based learning rate
per_voxel_init()
if cfg_train.pervoxel_lr:
def per_voxel_init():
cnt = model.voxel_count_views(
rays_o_tr=rays_o_tr, rays_d_tr=rays_d_tr, imsz=imsz, near=near, far=far,
stepsize=cfg_model.stepsize, downrate=cfg_train.pervoxel_lr_downrate,
irregular_shape=data_dict['irregular_shape'])
optimizer.set_pervoxel_lr(cnt)
model.mask_cache.mask[cnt.squeeze() <= 2] = False
per_voxel_init()
if cfg_train.maskout_lt_nviews > 0:
model.update_occupancy_cache_lt_nviews(
rays_o_tr, rays_d_tr, imsz, render_kwargs, cfg_train.maskout_lt_nviews)
4. Initialize importance score
init_importance(
render_poses=data_dict[‘poses’][data_dict[‘i_train’]],
HW=data_dict[‘HW’][data_dict[‘i_train’]],
Ks=data_dict[‘Ks’][data_dict[‘i_train’]],
savedir=importance_savedir,
**render_viewpoints_kwargs)
def init_importance(model, render_poses, HW, Ks, ndc, render_kwargs, savedir=None, render_factor=0, ):
'''Render images for the given viewpoints; run evaluation if gt given.
'''
imp_path = os.path.join(savedir, 'importance.pth')
if os.path.exists(imp_path):
print('load exsited importance calculation')
model.importance = torch.load(imp_path)
return
assert len(render_poses) == len(HW) and len(HW) == len(Ks)
print('start importance calculation')
if render_factor!=0:
HW = np.copy(HW)
Ks = np.copy(Ks)
HW = (HW/render_factor).astype(int)
Ks[:, :2, :3] /= render_factor
pseudo_grid = torch.ones_like(model.density.grid)
pseudo_grid.requires_grad = True
for i, c2w in enumerate(tqdm(render_poses)):
H, W = HW[i]
K = Ks[i]
c2w = torch.Tensor(c2w)
rays_o, rays_d, viewdirs = dvgo.get_rays_of_a_view(
H, W, K, c2w, ndc, inverse_y=render_kwargs['inverse_y'],
flip_x=cfg.data.flip_x, flip_y=cfg.data.flip_y)
rays_o = rays_o.flatten(0,-2)
rays_d = rays_d.flatten(0,-2)
viewdirs = viewdirs.flatten(0,-2)
i = 0
for ro, rd, vd in zip(rays_o.split(8192, 0), rays_d.split(8192, 0), viewdirs.split(8192, 0)):
ret = model.forward_imp(ro, rd, vd, pseudo_grid, **render_kwargs)
if (ret['weights'].size(0) !=0) and (ret['sampled_pseudo_grid'].size(0) !=0):
(ret['weights'].detach()*ret['sampled_pseudo_grid']).sum().backward()
i += 1
model.importance = pseudo_grid.grad.clone()
model.density.grid.grad = None
torch.save(model.importance, imp_path)
return
5. Codebook initialization
high = None
model.eval()
model.vq.train()
VQ_CHUNK = 80000
with torch.no_grad():
model.init_cdf_mask(args.importance_prune, args.importance_include) # voxel prune
vq_mask = torch.logical_xor(model.non_prune_mask, model.keep_mask)
if vq_mask.any():
k0_needs_vq = model.k0.grid.clone().reshape(model.k0_dim, -1).T[vq_mask]
imp = model.importance.flatten()[vq_mask]
k = args.k_expire
if k > model.vq.codebook_size:
k = 0
for _ in trange(1000):
indexes = torch.randint(low=0,high=k0_needs_vq.shape[0],size=[VQ_CHUNK])
vq_weight = imp[indexes]
vq_feature = k0_needs_vq[indexes,:]
model.vq(vq_feature.unsqueeze(0), weight=vq_weight.reshape(1,-1,1))
replace_val, replace_index = torch.topk(model.vq._codebook.cluster_size, k=k, largest=False)
_, most_important_index = torch.topk(vq_weight, k=k, largest=True)
model.vq._codebook.embed[:,replace_index,:] = vq_feature[most_important_index,:]
6. Apply voxel pruning and vector quantization
all_indices = model.fully_vq_reformat(args.importance_prune, args.importance_include)
7. Joint finetune VQ-DVGO
model.train()
model.vq.eval()
ckpt = torch.load(load_ckpt_path)
optimizer = utils.create_optimizer_or_freeze_model(model, cfg_train, global_step=0)
optimizer.load_state_dict(ckpt['optimizer_state_dict'])
reset initial learning rate
for i_opt_g, param_group in enumerate(optimizer.param_groups):
param_group['lr'] = param_group['lr'] * 5
training & save
torch.cuda.empty_cache()
psnr_lst = []
time0 = time.time()
global_step = -1
for global_step in trange(1, 10000):
# training code
if global_step != -1:
torch.save({
'global_step': global_step,
'model_kwargs': model.get_kwargs(),
'model_state_dict': model.state_dict(),
'optimizer_state_dict': optimizer.state_dict(),
}, last_ckpt_path)
print(f'scene_rep_reconstruction ({stage}): saved checkpoints at', last_ckpt_path)
for循环下具体training内容:
- random sample rays
if cfg_train.ray_sampler in ['flatten', 'in_maskcache']:
sel_i = batch_index_sampler()
target = rgb_tr[sel_i]
rays_o = rays_o_tr[sel_i]
rays_d = rays_d_tr[sel_i]
viewdirs = viewdirs_tr[sel_i]
elif cfg_train.ray_sampler == 'random':
sel_b = torch.randint(rgb_tr.shape[0], [cfg_train.N_rand])
sel_r = torch.randint(rgb_tr.shape[1], [cfg_train.N_rand])
sel_c = torch.randint(rgb_tr.shape[2], [cfg_train.N_rand])
target = rgb_tr[sel_b, sel_r, sel_c]
rays_o = rays_o_tr[sel_b, sel_r, sel_c]
rays_d = rays_d_tr[sel_b, sel_r, sel_c]
viewdirs = viewdirs_tr[sel_b, sel_r, sel_c]
else:
raise NotImplementedError
- load to gpu
if cfg.data.load2gpu_on_the_fly:
target = target.to(device)
rays_o = rays_o.to(device)
rays_d = rays_d.to(device)
viewdirs = viewdirs.to(device)
- volume rendering
assert model.importance is not None
render_result = model(
rays_o, rays_d, viewdirs,
global_step=global_step, target=target, is_train=True, use_vq_flag=False, include_thres=high,
**render_kwargs)
- gradient descent step
# gradient descent step
optimizer.zero_grad(set_to_none=True)
loss = cfg_train.weight_main * F.mse_loss(render_result['rgb_marched'], target)
psnr = utils.mse2psnr(loss.detach())
if cfg_train.weight_entropy_last > 0:
pout = render_result['alphainv_last'].clamp(1e-6, 1-1e-6)
entropy_last_loss = -(pout*torch.log(pout) + (1-pout)*torch.log(1-pout)).mean()
loss += cfg_train.weight_entropy_last * entropy_last_loss
if cfg_train.weight_nearclip > 0:
near_thres = data_dict['near_clip'] / model.scene_radius[0].item()
near_mask = (render_result['t'] < near_thres)
density = render_result['raw_density'][near_mask]
if len(density):
nearclip_loss = (density - density.detach()).sum()
loss += cfg_train.weight_nearclip * nearclip_loss
if cfg_train.weight_distortion > 0:
n_max = render_result['n_max']
s = render_result['s']
w = render_result['weights']
ray_id = render_result['ray_id']
loss_distortion = flatten_eff_distloss(w, s, 1/n_max, ray_id)
loss += cfg_train.weight_distortion * loss_distortion
if cfg_train.weight_rgbper > 0:
rgbper = (render_result['raw_rgb'] - target[render_result['ray_id']]).pow(2).sum(-1)
rgbper_loss = (rgbper * render_result['weights'].detach()).sum() / len(rays_o)
loss += cfg_train.weight_rgbper * rgbper_loss
loss.backward()
if global_step<cfg_train.tv_before and global_step>cfg_train.tv_after and global_step%cfg_train.tv_every==0:
if cfg_train.weight_tv_density>0:
model.density_total_variation_add_grad(
cfg_train.weight_tv_density/len(rays_o), global_step<cfg_train.tv_dense_before)
if cfg_train.weight_tv_k0>0:
model.k0_total_variation_add_grad(
cfg_train.weight_tv_k0/len(rays_o), global_step<cfg_train.tv_dense_before)
optimizer.step()
psnr_lst.append(psnr.item())
- synchornize codebook for every 10 iterations
# synchornize codebook for every 10 iterations
if global_step%10 == 0:
with torch.no_grad():
gather_grid = torch.zeros(all_indices.max(), model.k0_dim).to(device)
k0_grid=model.k0.grid.reshape(model.k0_dim,-1).T
out = torch_scatter.scatter(k0_grid, index=all_indices, dim=0, reduce='mean')
max_element = min(out.shape[0],model.used_kwargs["codebook_size"])
model.vq._codebook.embed[:max_element,:].copy_(out[:max_element,:])
new_k0_grid = torch.zeros(all_indices.shape[0], model.k0_dim).to(device)
new_k0_grid = out[all_indices].T.reshape(*model.k0.grid.shape)
model.k0.grid.copy_(new_k0_grid)
- update lr
# update lr
decay_steps = cfg_train.lrate_decay * 1000
decay_factor = 0.1 ** (1/decay_steps)
for i_opt_g, param_group in enumerate(optimizer.param_groups):
param_group['lr'] = param_group['lr'] * decay_factor
- check log & save
# check log & save
if global_step%args.i_print==0:
eps_time = time.time() - time0
eps_time_str = f'{eps_time//3600:02.0f}:{eps_time//60%60:02.0f}:{eps_time%60:02.0f}'
tqdm.write(f'scene_rep_reconstruction ({stage}): iter {global_step:6d} / '
f'Loss: {loss.item():.9f} / PSNR: {np.mean(psnr_lst):5.2f} / '
f'Eps: {eps_time_str}')
psnr_lst = []
compute_bbox
compute_bbox_by_cam_frustrm()
def compute_bbox_by_cam_frustrm(args, cfg, HW, Ks, poses, i_train, near, far, **kwargs):
print('compute_bbox_by_cam_frustrm: start')
if cfg.data.unbounded_inward:
xyz_min, xyz_max = _compute_bbox_by_cam_frustrm_unbounded(
cfg, HW, Ks, poses, i_train, kwargs.get('near_clip', None))
else:
xyz_min, xyz_max = _compute_bbox_by_cam_frustrm_bounded(
cfg, HW, Ks, poses, i_train, near, far)
print('compute_bbox_by_cam_frustrm: xyz_min', xyz_min)
print('compute_bbox_by_cam_frustrm: xyz_max', xyz_max)
print('compute_bbox_by_cam_frustrm: finish')
return xyz_min, xyz_max
def _compute_bbox_by_cam_frustrm_bounded(cfg, HW, Ks, poses, i_train, near, far):
xyz_min = torch.Tensor([np.inf, np.inf, np.inf])
xyz_max = -xyz_min
for (H, W), K, c2w in zip(HW[i_train], Ks[i_train], poses[i_train]):
rays_o, rays_d, viewdirs = dvgo.get_rays_of_a_view(
H=H, W=W, K=K, c2w=c2w,
ndc=cfg.data.ndc, inverse_y=cfg.data.inverse_y,
flip_x=cfg.data.flip_x, flip_y=cfg.data.flip_y)
if cfg.data.ndc:
pts_nf = torch.stack([rays_o+rays_d*near, rays_o+rays_d*far])
else:
pts_nf = torch.stack([rays_o+viewdirs*near, rays_o+viewdirs*far])
xyz_min = torch.minimum(xyz_min, pts_nf.amin((0,1,2)))
xyz_max = torch.maximum(xyz_max, pts_nf.amax((0,1,2)))
return xyz_min, xyz_max
def _compute_bbox_by_cam_frustrm_unbounded(cfg, HW, Ks, poses, i_train, near_clip):
# Find a tightest cube that cover all camera centers
xyz_min = torch.Tensor([np.inf, np.inf, np.inf])
xyz_max = -xyz_min
for (H, W), K, c2w in zip(HW[i_train], Ks[i_train], poses[i_train]):
rays_o, rays_d, viewdirs = dvgo.get_rays_of_a_view(
H=H, W=W, K=K, c2w=c2w,
ndc=cfg.data.ndc, inverse_y=cfg.data.inverse_y,
flip_x=cfg.data.flip_x, flip_y=cfg.data.flip_y)
pts = rays_o + rays_d * near_clip
xyz_min = torch.minimum(xyz_min, pts.amin((0,1)))
xyz_max = torch.maximum(xyz_max, pts.amax((0,1)))
center = (xyz_min + xyz_max) * 0.5
radius = (center - xyz_min).max() * cfg.data.unbounded_inner_r
xyz_min = center - radius
xyz_max = center + radius
return xyz_min, xyz_max
compute_bbox_by_coarse_geo()
@torch.no_grad()
def compute_bbox_by_coarse_geo(model_class, model_path, thres):
print('compute_bbox_by_coarse_geo: start')
eps_time = time.time()
model = utils.load_model(model_class, model_path)
interp = torch.stack(torch.meshgrid(
torch.linspace(0, 1, model.world_size[0]),
torch.linspace(0, 1, model.world_size[1]),
torch.linspace(0, 1, model.world_size[2]),
), -1)
dense_xyz = model.xyz_min * (1-interp) + model.xyz_max * interp
density = model.density(dense_xyz)
alpha = model.activate_density(density)
mask = (alpha > thres)
active_xyz = dense_xyz[mask]
xyz_min = active_xyz.amin(0)
xyz_max = active_xyz.amax(0)
print('compute_bbox_by_coarse_geo: xyz_min', xyz_min)
print('compute_bbox_by_coarse_geo: xyz_max', xyz_max)
eps_time = time.time() - eps_time
print('compute_bbox_by_coarse_geo: finish (eps time:', eps_time, 'secs)')
return xyz_min, xyz_max
main()
关键流程
VQRF代码与实验 (1)
Init – Load – Train – Render
render_viewpoints
def render_viewpoints(model, render_poses, HW, Ks, ndc, render_kwargs,
gt_imgs=None, savedir=None, dump_images=False,
render_factor=0, render_video_flipy=False, render_video_rot90=0,
eval_ssim=False, eval_lpips_alex=False, eval_lpips_vgg=False):
'''Render images for the given viewpoints; run evaluation if gt given.
'''
assert len(render_poses) == len(HW) and len(HW) == len(Ks)
if render_factor!=0:
HW = np.copy(HW)
Ks = np.copy(Ks)
HW = (HW/render_factor).astype(int)
Ks[:, :2, :3] /= render_factor
rgbs = []
depths = []
bgmaps = []
psnrs = []
ssims = []
lpips_alex = []
lpips_vgg = []
for i, c2w in enumerate(tqdm(render_poses)):
H, W = HW[i]
K = Ks[i]
c2w = torch.Tensor(c2w)
rays_o, rays_d, viewdirs = dvgo.get_rays_of_a_view(
H, W, K, c2w, ndc, inverse_y=render_kwargs['inverse_y'],
flip_x=cfg.data.flip_x, flip_y=cfg.data.flip_y)
keys = ['rgb_marched', 'depth', 'alphainv_last']
rays_o = rays_o.flatten(0,-2)
rays_d = rays_d.flatten(0,-2)
viewdirs = viewdirs.flatten(0,-2)
render_result_chunks = [
{k: v for k, v in model(ro, rd, vd, **render_kwargs).items() if k in keys}
for ro, rd, vd in zip(rays_o.split(8192, 0), rays_d.split(8192, 0), viewdirs.split(8192, 0))
]
render_result = {
k: torch.cat([ret[k] for ret in render_result_chunks]).reshape(H,W,-1)
for k in render_result_chunks[0].keys()
}
rgb = render_result['rgb_marched'].cpu().numpy()
depth = render_result['depth'].cpu().numpy()
bgmap = render_result['alphainv_last'].cpu().numpy()
rgbs.append(rgb)
depths.append(depth)
bgmaps.append(bgmap)
if i==0:
print('Testing', rgb.shape)
if gt_imgs is not None and render_factor==0:
p = -10. * np.log10(np.mean(np.square(rgb - gt_imgs[i])))
psnrs.append(p)
if eval_ssim:
ssims.append(utils.rgb_ssim(rgb, gt_imgs[i], max_val=1))
if eval_lpips_alex:
lpips_alex.append(utils.rgb_lpips(rgb, gt_imgs[i], net_name='alex', device=c2w.device))
if eval_lpips_vgg:
lpips_vgg.append(utils.rgb_lpips(rgb, gt_imgs[i], net_name='vgg', device=c2w.device))
# break
if len(psnrs):
print('Testing psnr', np.mean(psnrs), '(avg)')
if eval_ssim: print('Testing ssim', np.mean(ssims), '(avg)')
if eval_lpips_vgg: print('Testing lpips (vgg)', np.mean(lpips_vgg), '(avg)')
if eval_lpips_alex: print('Testing lpips (alex)', np.mean(lpips_alex), '(avg)')
if eval_ssim and eval_lpips_vgg and eval_lpips_alex:
np.savetxt(f'{savedir}/mean.txt', np.asarray([np.mean(psnrs), np.mean(ssims), np.mean(lpips_vgg), np.mean(lpips_alex)]))
else:
np.savetxt(f'{savedir}/mean.txt', np.asarray([np.mean(psnrs)]))
if render_video_flipy:
for i in range(len(rgbs)):
rgbs[i] = np.flip(rgbs[i], axis=0)
depths[i] = np.flip(depths[i], axis=0)
bgmaps[i] = np.flip(bgmaps[i], axis=0)
if render_video_rot90 != 0:
for i in range(len(rgbs)):
rgbs[i] = np.rot90(rgbs[i], k=render_video_rot90, axes=(0,1))
depths[i] = np.rot90(depths[i], k=render_video_rot90, axes=(0,1))
bgmaps[i] = np.rot90(bgmaps[i], k=render_video_rot90, axes=(0,1))
if savedir is not None and dump_images:
for i in trange(len(rgbs)):
rgb8 = utils.to8b(rgbs[i])
filename = os.path.join(savedir, '{:03d}.png'.format(i))
imageio.imwrite(filename, rgb8)
rgbs = np.array(rgbs)
depths = np.array(depths)
bgmaps = np.array(bgmaps)
return rgbs, depths, bgmaps
seed
def seed_everything():
'''Seed everything for better reproducibility.
(some pytorch operation is non-deterministic like the backprop of grid_samples)
'''
torch.manual_seed(args.seed)
np.random.seed(args.seed)
random.seed(args.seed)
load data_dict
def load_everything(args, cfg):
'''Load images / poses / camera settings / data split.
'''
data_dict = load_data(cfg.data)
# remove useless field
kept_keys = {
'hwf', 'HW', 'Ks', 'near', 'far', 'near_clip',
'i_train', 'i_val', 'i_test', 'irregular_shape',
'poses', 'render_poses', 'images'}
for k in list(data_dict.keys()):
if k not in kept_keys:
data_dict.pop(k)
# construct data tensor
if data_dict['irregular_shape']:
data_dict['images'] = [torch.FloatTensor(im, device='cpu') for im in data_dict['images']]
else:
data_dict['images'] = torch.FloatTensor(data_dict['images'], device='cpu')
data_dict['poses'] = torch.Tensor(data_dict['poses'])
return data_dict
config_parser
def config_parser():
'''Define command line arguments
'''
parser = argparse.ArgumentParser(formatter_class=argparse.ArgumentDefaultsHelpFormatter)
parser.add_argument('--config', required=True,
help='config file path')
parser.add_argument("--seed", type=int, default=777,
help='Random seed')
parser.add_argument("--no_reload", action='store_true',
help='do not reload weights from saved ckpt')
parser.add_argument("--no_reload_optimizer", action='store_true',
help='do not reload optimizer state from saved ckpt')
parser.add_argument("--ft_path", type=str, default='',
help='specific weights npy file to reload for coarse network')
parser.add_argument("--export_bbox_and_cams_only", type=str, default='',
help='export scene bbox and camera poses for debugging and 3d visualization')
parser.add_argument("--export_coarse_only", type=str, default='')
# testing options
parser.add_argument("--render_only", action='store_true',
help='do not optimize, reload weights and render out render_poses path')
parser.add_argument("--render_test", action='store_true')
parser.add_argument("--render_train", action='store_true')
parser.add_argument("--render_video", action='store_true')
parser.add_argument("--render_video_flipy", action='store_true')
parser.add_argument("--render_video_rot90", default=0, type=int)
parser.add_argument("--render_video_factor", type=float, default=0,
help='downsampling factor to speed up rendering, set 4 or 8 for fast preview')
parser.add_argument("--dump_images", action='store_true')
parser.add_argument("--eval_ssim", action='store_true')
parser.add_argument("--eval_lpips_alex", action='store_true')
parser.add_argument("--eval_lpips_vgg", action='store_true')
# parser.add_argument("--apply_quant", default=True, type=bool)
# logging/saving options
parser.add_argument("--i_print", type=int, default=500,
help='frequency of console printout and metric loggin')
parser.add_argument("--i_weights", type=int, default=100000,
help='frequency of weight ckpt saving')
# vqrf options
parser.add_argument("--fully_vq", action="store_true",
help='fully vector quantize the full model')
parser.add_argument("--init_importance", action="store_true",
help='initialize importance score')
parser.add_argument("--importance_include", type=float, default=0.00,
help='quantile threshold for non-vq-voxels')
parser.add_argument("--importance_prune", type=float, default=1.0,
help='quantile threshold for prune=voxels')
parser.add_argument("--k_expire", type=int, default=10,
help='expireed k code per iteration')
parser.add_argument("--render_fine", action="store_true",
help='rendering and testing the non compressed model')
return parser