论文1:EMNLP2019-Aspect-based Sentiment Classification with Aspect-specific Graph
EMNLP2019-Aspect-based Sentiment Classification with Aspect-specific Graph
一. 研究过程
1.神经网络(2014-2015)
2.RNNs+attention(2016-2018)
3.虽然基于atteniton的模型很有前途,但它们不足以捕捉上下文单词和句子中的方面之间的句法依赖关系,之后有人对注意权重施加一些句法限制(2018),但是句法结构的效果没有被充分利用。
4.除了注意力模型,CNNs被用来发现用于一个方面的描述性多词短语,一个方面的情感通常由关键短语而不是单个词来确定(2018),但是不足以确定彼此不相邻的多个单词描述的情感。
5.本文通过在句法依存关系树上建立GCN(ASGCN)来解决上述两种问题(2019)(通过参考句法依存关系树,GCN潜在地能够将句法相关的词绘制到目标方面,并且利用具有GCN层的长期多词关系和句法信息。)
注:这种建模方式为什莫可以解决上述两种问题?
- 由于图卷积过程只编码近邻的信息,图中的一个节点只能受到L层GCN中L步内的邻近节点的影响。通过这种方式,句子的依存关系树上的图形卷积为句子内的方面提供了句法约束,以基于句法距离来识别描述性单词。
- 此外,GCN能够处理一个方面的极性由非连续词描述的情况,因为依赖树上的GCN将把非连续词聚集到一个较小的范围内,并用图形卷积适当地聚集它们的特征。因此,我们受到启发,采用GCN来利用句法信息和长期单词依赖性进行基于方面的情感分类。
二.模型结构
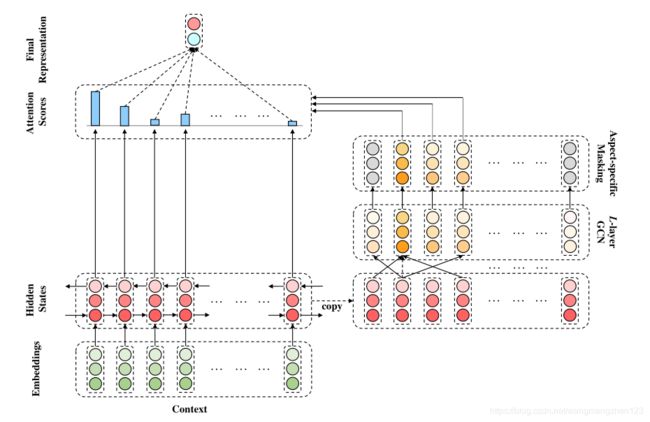
1.ASGCN始于一个双向长短期记忆网络(LSTM)层,用于捕获关于词序的上下文信息。
2.为了获得特定于方面的特征,在LSTM输出之上实现了多层GCN结构。
3.随后是Mask机制,该机制过滤掉非特定于方面的字并仅保留高级别特定于方面的特征。
4.特定于方面的特征被反馈到LSTM输出,用于检索关于方面的信息特征,然后用于预测基于方面的情感。
三.具体流程
1.词嵌入和双向LSTM层
(1)具有n个词的一句话:![]()
![]() ,从г+1开始到г+m共有m个方面词语。将词映射为词向量(通过GloVe),得到嵌入矩阵:
,从г+1开始到г+m共有m个方面词语。将词映射为词向量(通过GloVe),得到嵌入矩阵:![]() ,其中|V|表示一句话中单词的个数,de表示词嵌入的维数。
,其中|V|表示一句话中单词的个数,de表示词嵌入的维数。
(2)将句子经过词嵌入后的表示输入到双向LSTM,得到隐藏层状态向量的表示![]()
![]() ,其中
,其中![]() 表示来自双向LSTM的时间步长t处的隐藏状态向量,dh表示单向LSTM输出的隐藏状态向量的维数。
表示来自双向LSTM的时间步长t处的隐藏状态向量,dh表示单向LSTM输出的隐藏状态向量的维数。
2.获取面向方面的特征
与一般的情感分类不同,基于方面的情感分类旨在从方面的角度判断情感,因此需要一种面向方面的特征提取策略。在本研究中,我们通过在句子的句法依存关系树上应用多层图形卷积,并在其顶部施加特定于方面的掩蔽层,来获得面向方面的特征。
3.依赖树上的图卷积
(1)根据句子构建依赖树(本文没说如何构建)
(2)针对依赖树得到一个邻接矩阵![]() (需要注意的是,依赖树是有向图。虽然GCNs一般不考虑方向,但它们可以适应方向感知的情况。因此,我们提出了ASGCN的两个变种,即ASGCN-DG关于无向依赖图,ASGCN-DT关于有向依赖图,两者的区别在于邻接矩阵的不同。ASGCN-DT的邻接矩阵比ASGCN-DG稀疏得多。这种设置符合父母节点广泛受其子女节点影响的现象。)再者,遵循Kipf和Welling (2017)中的自循环思想,每个单词都被手动设置为与其自身相邻,即A的对角线值都是1。
(需要注意的是,依赖树是有向图。虽然GCNs一般不考虑方向,但它们可以适应方向感知的情况。因此,我们提出了ASGCN的两个变种,即ASGCN-DG关于无向依赖图,ASGCN-DT关于有向依赖图,两者的区别在于邻接矩阵的不同。ASGCN-DT的邻接矩阵比ASGCN-DG稀疏得多。这种设置符合父母节点广泛受其子女节点影响的现象。)再者,遵循Kipf和Welling (2017)中的自循环思想,每个单词都被手动设置为与其自身相邻,即A的对角线值都是1。
(3)ASGCN的输入为LSTM隐藏层状态向量,即![]() (使节点意识到上下文(Zhang et al., 2018)),然后每个节点的表示用具有归一化因子的图卷积运算更新如下(GCN的计算公式):
(使节点意识到上下文(Zhang et al., 2018)),然后每个节点的表示用具有归一化因子的图卷积运算更新如下(GCN的计算公式):
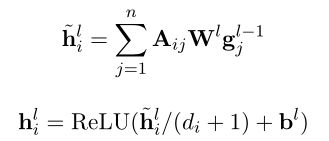
其中![]() ,W和b是可训练的参数。
,W和b是可训练的参数。
(4)在将![]() 喂入到连续的GCN之前先对其进行position-aware transformation:
喂入到连续的GCN之前先对其进行position-aware transformation:![]() ,其中
,其中![]() 是一个分配位置权重的函数((Li et al., 2018; Tang et al., 2016b; Chen et al., 2017))用于增加靠近方面词的上下文词的重要程度。通过这样做,我们旨在减少依赖解析过程中可能自然产生的噪声和偏差。该函数具体表示如下:
是一个分配位置权重的函数((Li et al., 2018; Tang et al., 2016b; Chen et al., 2017))用于增加靠近方面词的上下文词的重要程度。通过这样做,我们旨在减少依赖解析过程中可能自然产生的噪声和偏差。该函数具体表示如下:
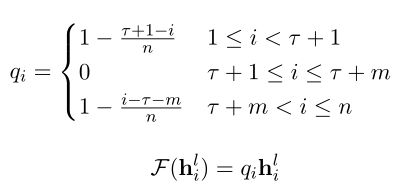
其中![]() 为第i层的位置权重。
为第i层的位置权重。
(5)GCN第L层的输出为:![]()
4.特定方面的Masking
在这一层中,我们屏蔽掉非方面词的隐藏状态向量,并保持方面词状态不变:![]() 这个第零层掩蔽层的输出是面向方面的特征:
这个第零层掩蔽层的输出是面向方面的特征:![]() 通过图卷积, 这些
通过图卷积, 这些![]() 特性以一种既考虑句法依存性又考虑长期多词关系的方式来感知方面周围的上下文
特性以一种既考虑句法依存性又考虑长期多词关系的方式来感知方面周围的上下文
5.方面感知的注意机制
对LSTM隐藏层的状态向量![]() 加入attention机制,其思想是从隐藏状态向量中检索与方面词语义相关的重要特征,并相应地为每个上下文词设置基于检索的关注权重。在我们的实现中,注意力权重的计算如下:
加入attention机制,其思想是从隐藏状态向量中检索与方面词语义相关的重要特征,并相应地为每个上下文词设置基于检索的关注权重。在我们的实现中,注意力权重的计算如下:
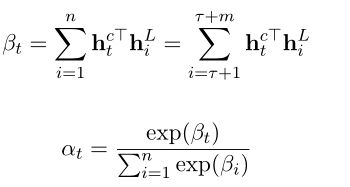
这里,点积用于测量方面成分单词和句子中的单词之间的语义相关性,使得方面特定的掩蔽,即零掩蔽,可以如第一个等式所示生效。因此,预测的最终表示公式如下: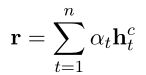
6.分类
在获得表示r之后,它被馈送到全连接层,随后是softmax归一化层,以产生概率分布p ∈ Rdpover极性决策空间:![]()
其中,dp与情感标签的维数相同,W和b是可训练参数。
7.训练
该模型由标准梯度下降算法训练,具有交叉熵损失和L2正则化: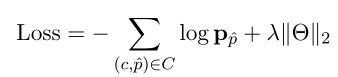
四.实验设置
1.数据集
(1)我们的实验在五个数据集上进行:一个(twitter)最初由董等人(2014)构建,包含TWITTER帖子
(2)而另外四个(LAP14,REST14,REST15,REST16)分别来自SemEval 2014任务4 (Pontiki等人,2014)、SemEval 2015任务12 (Pontiki等人,2015)和SemEval 2016任务5 (Pontiki等人,2016),由来自两个类别的数据组成,即笔记本电脑和餐馆。在前人工作的基础上(唐等,2016b),我们去除了REST15和REST16句子中带有冲突4极性或没有明确方面的样本。
2.参数设置
(1)权重采用均匀分布进行初始化
(2)隐藏状态向量的维数设置为300
(3)Adam优化器
(4)学习率0.001,L2正则化系数为105,批量为32。
(5)GCN层数设置为2
(6)实验结果是通过随机初始化平均3次运行获得的,其中准确率和平均精度F1被用作评估指标。
3.比较模型
(1)ASGCN-DG
(2)ASGCN-DT
(3)SVM
(4)LSTM
(5)MemNet
(6)AOA
(7)IAN
(8)TNet-LF
(9)ASGCN:为了检验GCN在多大程度上会超越CNN,我们还在实验中涉及了一个名为ASCNN的模型,它在ASGCN中用两层CNN代替了两层GCN。
五.实验结论
1.ASGCN-DG在TWITTER、LAP14、Rest15和REST16数据集上的表现比ASGCN-DT好得多。而且ASGCN-DT的成绩在LAP14上比TNet-LF低。一个可能的原因是,来自父节点的信息和来自子节点的信息一样重要,因此将依赖树视为有向图会导致信息丢失。
2.如果语法对数据不重要,位置权重的集成对减少用户生成内容的噪声没有帮助。
3.特定方面屏蔽对模型表现来说很重要
4.GCN在对语法信息不敏感的数据集上的表现不如预期。
5.GCN层数为2时模型表现较好
6.当句子中的方面的数量大于3时,准确性变得波动,这表明在捕捉多方面的相关性方面的鲁棒性较低,并且表明在未来的工作中需要对多方面进行建模
六.未来展望
本研究可能在以下几个方面进一步完善:
1.首先,句法依赖树边的信息,即每个边的标签,在这项工作中没有被利用。我们计划设计一个特定的图形神经网络,考虑到边缘标签。
2.第二,可以融入领域知识。
3.最后但同样重要的是,ASGCN模型可以通过捕捉方面词之间的依赖关系来扩展以同时判断多个方面的情感。