【论文笔记】Ensemble Augmented-Shot Y-shaped Learning
【论文笔记】EASY – Ensemble Augmented-Shot Y-shaped Learning: State-Of-The-Art Few-Shot Classification with Simple Ingredients
-
- Introduction
- RELATED WORK
- METHODOLOGY
-
- STEPS
- 参考资料
文章链接 :EASY – Ensemble Augmented-Shot Y-shaped Learning: State-Of-The-Art Few-Shot Classification with Simple Ingredients
Introduction
经典小样本setting包括以下两个部分:
1.generic dataset:包含很多类的很多例子。
在一般情况下,经常将数据集划分为两个不相交的子集,称为base dataset和validation dataset。base用于训练,validation用于衡量对unseen数据的泛化性能因此可以用来修复超参数。
小样本情况下,base和validation包含的类不相同,以至于泛化性能的评估需要在novel class上进行。
2.novel dataset:包含class与generic dataset的class不同,每个类只给出几个带标签的例子。带标签部分的样本称为支持集,不带标签的称为查询集,在进行基准测试时,通常使用大规模的novel dataset,从这些数据集中均匀随机地抽取人工小样本任务,我们称之为a run。在这种情况下,测试基准给出了类的个数n(named ways)、每个类的样本个数k和每个类的查询样本个数q。报告的性能通常是经过大量运行后的平均性能。
为了利用以前在通用数据集上通过模型学习到的知识,一种常见的方法是删除模型的最终分类层。得到的模型被称为特征提取器,通常被称为骨干网络,可以用来将支持和查询数据集转换为特征向量。这是迁移学习的一种形式。本文不考虑使用额外的数据,如其他数据集,也不用额外的语义信息和分割信息。在分类任务之前,还可以对样本 和/或 相关的特征向量进行额外的预处理步骤。另一种主要的方法使用第二节提到的元学习。
归纳、直推情况。
在归纳inductive小样本学习情况下,小样本分类器只能使用支持集,并且对查询集的每个样本独
立地进行预测;
在直推transductive小样本学习中,小样本分类器在执行预测时可以访问支持集和完整的查询
数据集。
使用哪种方式与现实情况有关。一般来说,归纳小样本对应的是数据获取昂贵的情况,而直推式小样本对应的是数据标记昂贵的情况。
这篇论文的兴趣点在于提出一种非常简单的方法,将文献中常见的成分组合在一起,同时获得具有竞争力的表现。因此,这一贡献并没有提出任何全新的东西,但我们相信它将有助于更清晰地了解如何在现实应用中有效地实现小样本学习。我们的主要动机是定义一个适当的基线来比较和开始,在这个基线上获得性能的提高将比从一个训练不佳的骨干网络开始更具挑战性。我们的目标是证明一个简单的方法比最近小样本文献中提出的越来越复杂的方法具有更高的性能。
贡献:
- 介绍了一个非常简单的方法,如图1所示,用于归纳或直推小样本学习,几乎没有超参数,除了用于训练骨干的;
- 展示所提出的方法在该领域多个标准基准上达到甚至超过最先进性能的能力。
RELATED WORK
按照经典流程介绍一些小样本学习方法,其中包含后续本模型用到的各种ingredients。
1.数据增强(Data augmentation)
首先,通常在通用数据集上使用数据增强或增强抽样来人为产生额外的样本,例如使用rotate[12]、crop[13]、jitter 、GANs[14]、[15]或其他方法[16]。然而,研究支持和查询集上的数据增强并不多,探究这一方向的方法有[9](作者提出通过使用一种相对复杂的机制识别合适的crops来选择图像的前景目标),以及[17](作者提出模拟相邻基类分布来创建增广潜在空间向量)
此外,mixup[11]和manifold-mixup[7]也被用来解决具有挑战性的数据缺乏问题。两者都可以看作是通过对样本和标签进行线性插值的正则化方法。mixup在样本层面创建线性插值,而manifold mixup则专注于特征向量层面。
2.骨干网络训练(Backbone training)
Mixup通常连同自监督(self-supervisionS2)一同使用,来增强骨干网络的鲁棒性。S2一般在实现过程中作为一种辅助loss使用来判断哪种transformation更适合对图像使用。
一个有用的训练方法就是episodic training,主要思想就是运用相同的训练和测试条件,通常基于随机梯度下降的骨干网络训练策略并不是随机选择batch,通常运用小样本训练情境下设计的batch [1], [18], [10], [19]。
元学习,或学会学习,是该领域的一个主要研究方向。这个方法通常学习良好的初始化intialization或良好的优化器optimizer,这样可以在几个梯度步骤中学习新类([1]、[2]、[3]、[4]、[5]、[6]),在这方面,经常使用episodic training,最近的工作利用这一概念在骨干网络的训练中产生增强任务[20]。
对比学习旨在训练一个模型,使其学习最大化相同图像的变换实例之间的相似度,最小化不同图像的变换实例之间的一致性[21],[22],[23],[24],[9]。有监督对比学习(Supervised contrast learning[25])是最近被用于小样本学习的一种改进方法,它通过最大化类样本间的相似度来代替相同的图像[25]、[8]。
3.多个骨干网络集成(Exploiting multiple backbones)
Distillition蒸馏 最近在小样本文献中运用。该思想是通过迫使student匹配teacher的类概率分布来将知识从teacher模型转移到student模型[26],[27],[8]。
Ensembling集成 包括将不同骨干网络提取的特征拼接在一起。该模型用于提高小样本学习的性能[20]。它可以被看作是蒸馏的一种更直接的替代品。为了限制多骨干训练的计算开销,一些作者建议使用snapshots[28]。
4.小样本分类(Few-shot classification)
过去几年归纳的分类方法大多依赖于简单的方法,如nearest class mean [29], cosine classifiers [30] 和 logistic regression [17]。更多样化的方法可以在transductive setting中实施。 Clustering algorithms [9], embedding propagation [31]和 optimal transport [32] 在很大程度上成功地超越了inductive setting的性能。
METHODOLOGY
所提出的方法包括5个步骤,随后进行了描述,如图1所示。在实验中,我们也报告了当忽略可选步骤时的消融实验结果。
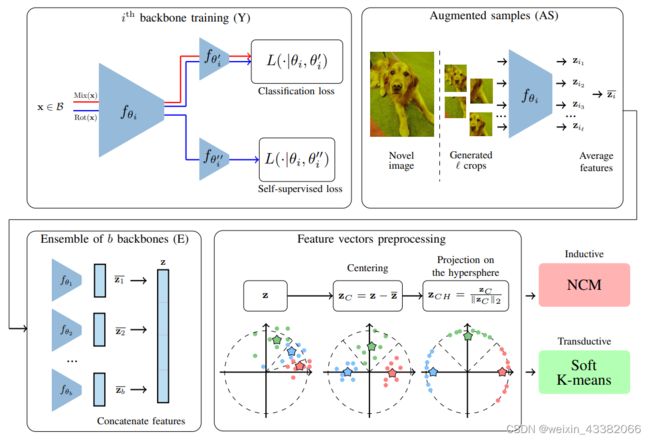
如图1所示。我们提出的方法的示例。
Y:首先使用generic dataset训练一个骨干网络集合。我们并行使用两个交叉熵损失,一个用于base class的分类,另一个用于自监督目标(旋转)。我们还使用了manifold mixup[7]。所有的骨干网络都是使用完全相同的例程训练的。它们初始化参数都是随机的,数据批次里现的顺序也可能不同。
AS(Augmention Samples):然后,对于新数据集中的每一幅图像,我们生成多个crop。然后计算它们的特征向量。并进行平均;
E:将每幅图像表示为各骨干网络的AS输出的拼接;预处理,增加了几个经典的预处理步骤,包括归纳情况下去除base数据集的特征向量均值或rotate情况下的新特征向量居中,以及在hyper sphere上投影。
最后,在transductive setting下使用简单的最近邻类均值分类器nearest class man classifier, NCM,在inductive setting下使用软K-means算法。
此外,mixup[11]和manifold-mixup[7]也被用来解决具有挑战性的数据缺乏问题。两者都可以看作是通过对样本和标签进行线性插值的正则化方法。混合在样本层面创建线性插值,而流形混合则专注于特征向量。
基于平滑假设的方法:会在原始输入上进行crop和旋转等各种操作,例如AutoAugmentation, CutOut 和Mixup等.
基于流形假设的方法:在模型的隐藏层进行一定的修改来得到新的样本,例如AT,VAT和Manifold Mixup等。
STEPS
A.骨干网络训练
使用随机resized crops、随机 color jitters和随机 horizontal flips的数据增强。
学习器:使用 cosine-annealing scheduler[33](每一步都更新学习率,在一个余弦周期中,学习率在η0 和 0 之间变化)。在周期结束时,我们重新开始学习过程,并以减小后的η0 重新开始。
开始η0 = 0.1,每个周期以10%的速率降低
设置训练五个cycle每个cycle内100个epoch。
训练骨干网络:S2M2[12]。基本原理是采用标准的分类体系结构(如Res Net12[34]),并在倒数第二层建立一个新的逻辑回归分类器分支。上面的分类器用来识别输入样本的类别产生classification loss,下面的这个新的分类器旨在检索四种可能的旋转(四分之一 360°旋转)中的哪一种已经应用到输入样本中,产生self-supervised。从而形成一个y形模型(如下图所示)。
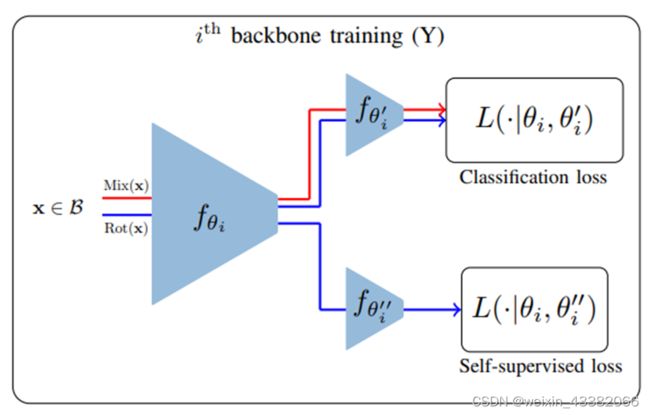
two-step的训练流程:第一个batch输入仅提供给第一个分类器,并结合了manifold-mixup。然后对第二个batch的输入进行任意旋转,并提供给两个分类器。训练结束后,冻结骨干网络。
使用[34]中描述的标准 ResNet12进行实验,其中特征向量为640维。这些特征向量是通过对最后一层卷积的输出进行全局平均池化得到的。这样的骨干网络包含约1200万个参数。实验减小ResNet12的大小,记为 R e s N e t 12 ( 1 / 2 ) ResNet12(1/ \sqrt{2}) ResNet12(1/2) ,把每个feature map的数量除以根号二取整,得到特征向量为450维。
B.数据增强
对每个图像进行 30次 crop,然后把crop后的图像送入特征提取网络得到feature vector,将它们average一下。
C.集成网络
用不同的随机种子初始化网络参数,然后将特征进行concat。
集成模型减少参数量是通过减少hidden channel的数量实现。
D.特征预处理
运用文章《Simpleshot: Revisiting nearest-neighbor classification for few-shot learning》里面的两种变换,先centering然后L2归一化投影到hyper sphere。公式懒得放了。
E.分类
inductive情况下,使用nearest class mean(NCM)进行处理,Si为支持集特征向量集合: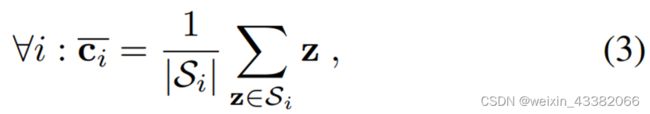
为每个query关联最近的类重心:
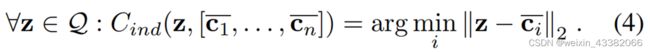
Transductive情况下,使用软kmeans算法,soft kmeans算法里面样本可以属于多个类,但属于不同的类概率不同:
w给出query与每个类关联的概率。

w公式如下, β为温度系数,
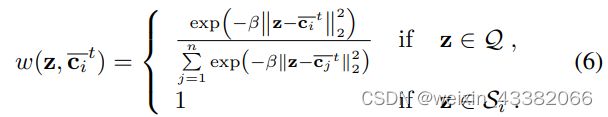
参考资料
AS部分:(主要关于S2M2R)
- https://blog.csdn.net/liuzhengjun3036/article/details/120084158
- https://blog.csdn.net/dorisx/article/details/120444243
- https://www.scholat.com/teamwork/showPostMessage.html?id=10288
- https://www.jianshu.com/p/d102e6ebc522
特征预处理部分:
- https://blog.csdn.net/qq_30146937/article/details/105496966
分类部分:
- https://blog.csdn.net/haimengao/article/details/27958193