从小白开始学python-网络爬虫二 (HTML、 CSS、Beautiful Soup介绍)
python-网络爬虫二
- HTML AND CSS
-
- HTML
- CSS
- beautiful soup的安装
- beautiful soup的使用
- 正则表达式(re库)
- 实战代码
- 点个赞呗
HTML AND CSS
HTML
HTML又称超文本标记语言,是现在创建网页的标准标记语言,它指定了文档的结构和格式
它通过一系列标签来问文档提供结构和格式,标签通常成对出现 ...
比如
我们不需要担心这部分内容的学习是不是又要花费大量的时间,实际上我们的浏览器已经提供了我们查看HTML的工具,比如chrome
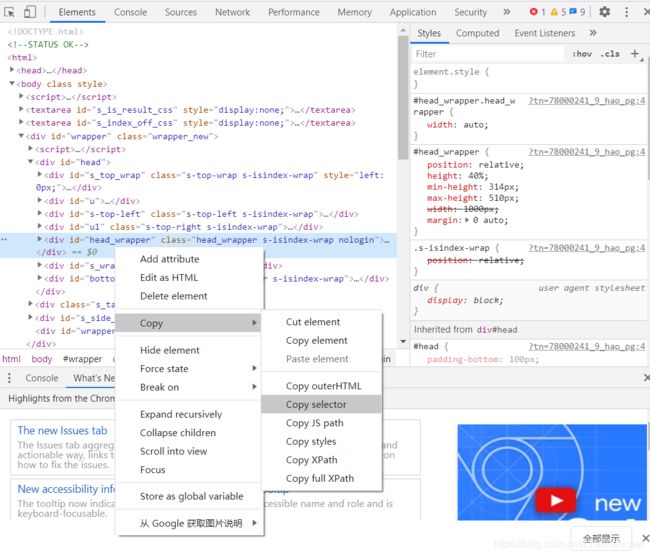
我们只需要右击鼠标,选择检查,我们就能看到这些HTML

跟我们爬取下来的内容是一致的,当然里面有些脚本是使用JavaScript的编程语言编写的,我们后面也会提到,当我们想要提取某个HTML元素的时候,我们可以在其上面右击,选择“copy selector”或者“copy xpath”
这对不会正则表达式的我们提供了极大的帮助!
CSS
层叠样式表
我们通过冒号分隔的基于键值的语句列表来表示样式信息
比如
color:'red';
font-size:14pt;
background-color:#ccc;
当然这样的声明是可以嵌入HTML中的,我们打开任何一个网页都能找到这样的用法
如果想要学习更多关于HTML和CSS的知识,可以访问下面这个网站哟
超级棒的学习网站(菜鸟教程)
下面我们进入正题:beautiful soup的学习
beautiful soup的安装
我们为了处理获得的网页信息引入的美丽汤
使用这个库我们能够抓取我们感兴趣的内容
使用pip安装
pip install -U beautifulsoup4
接下来就是BS发挥它神奇作用的时候了
beautiful soup的使用
首先我们需要创建一个beautiful soup的对象
from bs4 import BeautifulSoup
import requests
import re
target = 'https://www.baidu.com/'
get_url = requests.get(url=target)
print(get_url.status_code)
get_url.encoding = 'utf-8'
test = get_url.text
bs = BeautifulSoup(test)//有的时候这种用法会出错
最后一句创建了一个BS对象,这句出错的原因在于BS库本身依赖HTML解析器来执行大部分批量解析的工作,而python中存在不止一个这样的解析器:
- html.parser : python内置的解析器
- lxml : 处理速度很快,需要额外安装
- html5lib : 旨在与浏览器完全相同的方式解析网页,但速度稍慢
所以当我们拥有不止一个这样的解析器时,我们应该加上我们使用的解析器
bs = BeautifulSoup(test, "html.parser")//加上解析器
BS的主要任务时解析HTML内容并将其转换为基于树的表现形式
所以我们有两种获取数据的方法:
- find
- find_all
他们都可以用于查找HTML树中的元素
我们来看看他们的函数原型
find(name, attrs, recursive, string, **keywords)
find_all(name, attrs, recursive, string, limit, **keywords)
- name: 参数定义你希望找到的标签名字,可以传递字符串或者列表
- attrs: 属性的python字典
- recursive: 控制搜索的深度,默认为Ture,可以查找子标签
- string:根据元素的文本内容执行匹配
- limit: 限制检索的元素数量
注意find返回的是检索的元素,find_all返回的项目列表
两个方法返回的都是tag对象
正则表达式(re库)
这是高级的匹配模式(我也还没完全搞懂hhh)
正则表达式是定义一系列搜索模式的模式
经常用于字符串搜索和匹配代码以查找或替换字符串片段
(对于批量爬取下载有奇效!!!)
基本符号:
^ 表示匹配字符串的开始位置 (例外 用在中括号中[ ] 时,可以理解为取反,表示不匹配括号中字符串)
$ 表示匹配字符串的结束位置
* 表示匹配 零次到多次
+ 表示匹配 一次到多次 (至少有一次)
? 表示匹配零次或一次
. 表示匹配单个字符
| 表示为或者,两项中取一项
( ) 小括号表示匹配括号中全部字符
[ ] 中括号表示匹配括号中一个字符 范围描述 如[0-9 a-z A-Z]
{ } 大括号用于限定匹配次数 如 {n}表示匹配n个字符 {n,}表示至少匹配n个字符 {n,m}表示至少n,最多m
\ 转义字符 如上基本符号匹配都需要转义字符 如 \* 表示匹配*号
\w 表示英文字母和数字 \W 非字母和数字
\d 表示数字 \D 非数字
更多细致的用法参考这位博主的博客:
正则表达式语法和常用表达式
比如这行代码:
bs.find_all(re.compile('^h'))
//用于匹配所有以字母h开头的标签
实战代码
from bs4 import BeautifulSoup
import requests
import re
target = 'https://www.baidu.com/'
get_url = requests.get(url=target)
test = get_url.text
bs = BeautifulSoup(test, "html.parser")
print(bs.title) # 获取title标签的名称
print(bs.title.string) # 获取title标签的文本内容
你会发现你的输出好像并不和你想象的一样
输出结果:
<title>ç™¾åº¦ä¸€ä¸‹ï¼Œä½ å°±çŸ¥é“</title>
ç™¾åº¦ä¸€ä¸‹ï¼Œä½ å°±çŸ¥é“
为啥是乱码啊!!!
别慌,其实只是编码出现了错误而已只需要加上一行代码,告诉编译器编码格式即可
get_url.encoding = 'utf-8' # 编码格式
那么输出就会成这样:
<title>百度一下,你就知道</title>
百度一下,你就知道
下面我们贴出各种方法查找元素方法的代码:
find_all方法
for item in bs.find_all('a'):
# print(item.get('href')) # 获取属性 与下面的方法等价
print(item['href'])
for item in bs.find_all('a'):
print(item.get_text()) # 遍历a标签的文本值
输出结果:
http://news.baidu.com
https://www.hao123.com
http://map.baidu.com
http://v.baidu.com
http://tieba.baidu.com
http://www.baidu.com/bdorz/login.gif?login&tpl=mn&u=http%3A%2F%2Fwww.baidu.com%2f%3fbdorz_come%3d1
//www.baidu.com/more/
http://home.baidu.com
http://ir.baidu.com
http://www.baidu.com/duty/
http://jianyi.baidu.com/
新闻
hao123
地图
视频
贴吧
登录
更多产品
关于百度
About Baidu
使用百度前必读
意见反馈
正则表达式
t_list = bs.find_all(re.compile("^a")) # 传入正则表达式来匹配内容-开头为a标签
for item in t_list:
print(item)
输出结果:
<a class="mnav" href="http://news.baidu.com" name="tj_trnews">新闻</a>
<a class="mnav" href="https://www.hao123.com" name="tj_trhao123">hao123</a>
<a class="mnav" href="http://map.baidu.com" name="tj_trmap">地图</a>
<a class="mnav" href="http://v.baidu.com" name="tj_trvideo">视频</a>
<a class="mnav" href="http://tieba.baidu.com" name="tj_trtieba">贴吧</a>
<a class="lb" href="http://www.baidu.com/bdorz/login.gif?login&tpl=mn&u=http%3A%2F%2Fwww.baidu.com%2f%3fbdorz_come%3d1" name="tj_login">登录</a>
<a class="bri" href="//www.baidu.com/more/" name="tj_briicon" style="display: block;">更多产品</a>
<a href="http://home.baidu.com">关于百度</a>
<a href="http://ir.baidu.com">About Baidu</a>
<a href="http://www.baidu.com/duty/">使用百度前必读</a>
<a class="cp-feedback" href="http://jianyi.baidu.com/">意见反馈</a>
下篇预告:
使用表单和post请求
构造请求头
使用cookie